İSTATİSTİK DERS NOTLARI (Gözden Geçirilmiş İkinci Paylaşım)
|
|
|
- Nergis Ertegün
- 6 yıl önce
- İzleme sayısı:
Transkript
 Dr.")
1 T.C. ANKARA ÜNİVERSİTESİ EĞİTİM BİLİMLERİ FAKÜLTESİ İSTATİSTİK DERS NOTLARI (Gözden Geçirilmiş İkinci Paylaşım) Dr. Ergül DEMİR ANKARA Ocak, 2017
2 Lisans ve yüksek lisans eğitimlerinde istatistik dersi alan öğrencilerin öğrenmelerine yardımcı olmak amacıyla hazırlanmış olan bu metin, elektronik ortamda Ankara Üniversitesi Açık Ders Malzemeleri sistemine yüklenmiştir. Ankara Üniversitesi Açık Ders Malzemeleri web sayfasına elektronik adresinden erişilebilmektedir.
3 i İÇİNDEKİLER Sayfa No. İçindekiler... i BÖLÜM 1. İstatistik ile İlgili Bazı Temel Kavramlar... 1 BÖLÜM 2. Veri Setinin Hazırlanması ve Düzenlenmesi... 9 BÖLÜM 3. Frekans Dağılımları ve Frekans Tablolarının Hazırlanması BÖLÜM 4. Frekans Dağılımlarının Grafikle Gösterilmesi BÖLÜM 5. Merkezi Eğilim Ölçüleri BÖLÜM 6. Merkezden Dağılma Ölçüleri BÖLÜM 7. Bilgisayar Uygulamaları BÖLÜM 8. Bilgisayar Uygulamaları BÖLÜM 9. Normal Dağılım BÖLÜM 10. Puan Dönüşümleri BÖLÜM 11. Z Dağılımı BÖLÜM 12. Student T Dağılımı BÖLÜM 13. Hipotez Testi BÖLÜM 14. Bilgisayar Uygulamaları KAYNAKLAR
4 1 BÖLÜM 1 İSTATİSTİK İLE İLGİLİ BAZI TEMEL KAVRAMLAR İstatistik öğrenmelerinde sıklıkla karşılaşılacak olan temel bazı kavramlar, eğitim alanına yönelik örnekleriyle birlikte aşağıda açıklanmaktadır İSTATİSTİK NEDİR? İstatistik, en genel yaklaşımla, 'sayısal bilgi', 'sayısal veri' ya da 'ham veri' olarak tanımlanmaktadır. Örneğin 'Ayşe, 45kg ağırlığındadır' ifadesindeki 45kg, Ayşe'nin 'ağırlık' olarak tanımlanan bireysel hakkında bir bilgi vermektedir ve bir istatistiktir. Bir diğer yaklaşıma göre istatistik, bir süreç tanımlamaktadır. Bir süreç olarak istatistik, bir veri seti üzerinde yapılan aşamalı işlemleri ifade etmektedir. Veriler üzerinde, temelde betimleme ve çıkarsama işlemleri yapılabilmektedir. Matematiksel temelleri olan bu tür işlemleri içeren süreçler 'istatistik' ya da 'istatistiksel yöntem ve teknikler' olarak ifade edilmektedir. İstatistik, bilimsel araştırma ile istatistik ilişkisi kurularak da tanımlanabilmektedir. Temelde bir problem ya da güçlük durumuna çözüm üretme süreci ve çok yönlü bir etkinlik olan bilimsel araştırmalarda, araştırmacı, bir takım amaçlı gözlemlere bağlı olarak veriler elde etmekte ve bu verileri kullanarak olası çözüm önerilerini test etmektedir. Hipotez olarak bilinen bu olası çözüm önerilerinin test edilmesinde kullanılan yöntem ve teknikler, istatistik ya da istatistiksel yöntem olarak ifade edilmektedir GÖZLEM İstatistik özelinde gözlem; belli bir özellik hakkında bilgi ya da veri toplamak için yürütülen amaçlı ve iyi tanımlı bir eylemdir. Özellikler, 'doğrudan gözlenebilir özellikler' ve 'dolaylı gözlenebilir özellikler' olmak üzere iki grupta değerlendirilebilmektedir. Birey özellikleri dikkate alındığında, bireyin doğrudan gözlenebilir özellikleri olduğu gibi doğrudan gözlenmesi mümkün olmayan, bu nedenle ancak dolaylı olarak gözlenebilen özellikleri de bulunmaktadır. Örneğin saç rengi, göz rengi, parmakların sayısı, iki kişiden birinin diğerinden uzun ya da kısa olması gibi fiziksel özelliklerin bir çoğu doğrudan gözlenebilir özelliklerdir. Bu özelliklerin gözlenmesinde herhangi bir ölçme aracının kullanılmasına da ihtiyaç duyulmaz. Boy uzunluğu, ağırlık gibi bazı fiziksel özellikler ise üzerinde tahmin yürütülebilse bile doğrudan 'ölçülebilir' değildir. Bu tür
5 2 özelliklerin gözlenmesinde metre, baskül gibi ölçme araçlarının kullanılmasına ihtiyaç duyulur. Dolayısıyla bu tür özelliklerin de dolaylı gözlenebilen özellikler içerisinde değerlendirilmesi mümkündür. Diğer taraftan, başarı, zeka, ilgi, tutum, kişilik gibi psikolojik özelliklerin tamamı doğrudan gözlenebilir değildir. 'Örtük özellik' olarak da tanımlanabilen bu tür özelliklerin gözlenmesi oldukça güçtür. Bu tür özellikler ancak 'davranış' olarak tanımlanan belirtileri üzerinden dolaylı olarak gözlenebilirdir VERİ TOPLAMA ARACI Genellikle bireysel bir eylem olan gözlem, gözlemi yapan kişiye özgüdür ve bu yönüyle objektif bir gözlem yapılması güçtür. Gözlemlerin objektifliğini sağlamak için bazı önlemler alınabilmektedir. Araştırmacılar sıklıkla yapacakları gözlemlerin objektifliğini ve ölçmenin duyarlılığını artırmak için bir 'veri toplama aracı' ya da 'ölçme aracı' kullanır. O halde veri toplama aracı ya da 'ölçme aracı (ceasurement tool)', gözlenen belli bir özelliğe yönelik verilerin toplanmasında kullanılan aracı tanımlamaktadır. Kullanılacak veri toplama aracının türü, gözlenmek istenen özelliğe göre değişebilmektedir. Örneğin öğrenme başarısı gözlenmek istendiğinde bir başarı testi, zeka gözlenmek istendiğinde bir zeka testi, okula karşı tutum gözlenmek istendiğinde bir tutum ölçeği, kişilik özellikleri gözlenmek istendiğinde bir kişilik envanteri, bir konu hakkındaki görüşler gözlenmek istendiğinde bir anket kullanılabilmektedir GÖZLEM BİRİMİ Belli bir özelliğin üzerinde gözlendiği obje ya da nesnelerden her birine 'gözlem birimi' denir. Örneğin, bir okulda öğrencilerin derse geç kalma ya da devamsızlık durumları üzerine bir gözlem yapıldığını düşünelim. Bu gözlemde gözlem birimi, öğrencidir. Bir diğer örnek olarak belli bir caddede günlük trafik yoğunluğunun gözlendiğini düşünelim. Bu tür bir gözlemde, belli saat aralıklarında caddeden geçen araç sayısı, araç türlerine göre not edilebilir. Bu durumda gözlem birimleri araçlar olacaktır. Gözlem birimleri, canlılardan oluşabileceği gibi cansızlardan yani nesnelerden de oluşabilmektedir. Psikoloji, eğitim bilimleri, davranış bilimleri gibi alanlarda ilgi odağı birey özellikleri ve davranışlarıdır. Bu nedenle bu alanlarda yapılan gözlemlerde gözlem birimleri genellikle bireylerden oluşmaktadır.
6 EVREN - ÖRNEKLEM Evren (population), gözlenmesi amaçlanan belli bir özelliğe sahip gözlem birimlerinin tamamını içeren en geniş gözlem kümesi olarak tanımlanır. Evren, 'ana kitle', 'ana kütle' ya da 'popülasyon' olarak da ifade edilebilmektedir. Örneklem (sample), belli bir özelliğin üzerinde gözlendiği ve evrenin bir alt kümesi olan gözlem birimleri kümesidir. Tanımlanmış bir evrenden bir örneklem belirleme işlemelerini içeren yöntem ve tekniklere 'örnekleme (sampling)' denir. Tanımdan da anlaşılacağı üzere, örneklem büyüklüğü yani örnekleme dahil olan gözlem birimleri sayısı, evrenden küçüktür. Ayrıca bir evrenin içerisinde birden çok sayıda alt küme bulunabileceği için birden çok sayıda da örneklem belirlenebilir. Örneğin Ankara Üniversitesi öğrencilerinin akademik başarı düzeylerinin gözlenmek istendiğini düşünelim. Bu durumda Ankara Üniversitesinde öğrenim görmekte olan tüm öğrenciler, evreni oluşturacaktır. Tüm öğrenciler ulaşmak, tüm öğrencilerin bilgilerini almak ve bu veriler üzerinde istatistiksel işlemler yapmak çoğunlukla ciddi zaman ve emek maliyeti getirecektir. Bu durumda Ankara Üniversitesinde öğrenim gören faka Ankara Üniversitesini 'temsil edebilir (representative)' nitelikte daha küçük bir grup üzerinde gözlem yapılıp, bu daha küçük gruptan elde edilen bulgular, istatistiksel yöntemlerle ve belli bir olasılıkla evrene yani Ankara Üniversitesine genellenebilir. İşte bu daha küçük grup, örneklem olarak tanımlanır. Bir örneklemden elde edilen kestirimler, belli bir olasılıkla evrene genellenebilir. Bu tür bir genellemenin yapılabilmesi için gerekli ön koşul örneklemin evreni temsil edebilir olmasıdır. Temsil edebilir olma, gözlenmesi amaçlanan özelliğin evrendeki çeşitliliği ile örneklemdeki çeşitliliğinin birbirine yakın olmasını gerektirir. Örneğin yukarıda verilen Ankara Üniversitesi örneğinde örneklem Eğitim Bilimleri Fakültesi öğrencileri arasından belli sayıda öğrenciden oluşursa, bu örneklemin temsil edebilirliğinin düşük olacağı söylenebilir. Temsil edebilirliği yüksek olan bir örneklemde, her fakülte, bölüm ve programdan, her sınıf düzeyinden, evrendeki ağırlıklarına paralel olarak belli sayılarda öğrenci bulunması beklenir. Ayrıca cinsiyet, sosyoekonomik düzey gibi ilişkili olabilecek bazı değişkenler düzeyinde de evren ve örneklem dağılımının birbirine yakın olmasına özen göstermek gerekir.
7 HOMOJENLİK - HETEROJENLİK Gözlenen bir özellik açısından birbirine yakın ya da benzer gözlem birimlerinden oluşan gruplara 'homojen grup' denir. Aksi durumda gözlenen özellik açısından birbirinden farklı gözlem birimlerinden oluşan gruplara 'heterojen grup' denir. 'Tam homojen grup' denildiğinde, her bir grup üyelerinin her birinin aynı özellikte olduğunu, 'tam heterojen grup' ise grup üyelerinin her birinin farklı özellikte olduğunu ifade eder. Örneğin, "akademik başarı açısından A şubesi B şubesinden daha homojendir" denildiğinde, ilgilenilen özelliğin akademik başarı olduğu, A şubesindeki öğrencilerin akademik başarı ortalamalarının ya da notlarının B şubesine göre birbirine daha yakın olduğu anlaşılır PARAMETRE - İSTATİSTİK Alana özel kullanımıyla parametre, evrenden doğrudan elde edilen sayısal değerler ya da kestirimlerdir. 'Evren değer' olarak da ifade edilir. İstatistik ise örneklemden elde edilen sayısal değerler ya da kestirimlerdir. 'Örneklem değer' olarak da ifade edilir. Bu tanımlamalara göre istatistiklerle parametrelerin olasılıklı olarak örtüşme düzeylerinin test edilmesinde kullanılan yöntem ve teknikler de istatistiksel yöntem ve teknikler olarak tanımlanabilmektedir. Evren değer yani parametreler ile örnekle değer yani istatistikler, farklı sembollerle gösterilebilmektedir. Parametre İstatistik Frekans / Sıklık F f Kişi Sayısı N n Madde Sayısı K k Oran / Yüzde P ^p Aritmetik Ortalama µ Standart Sapma Σ s Varyans σ 2 s DEĞİŞKEN - SABİT Durumdan duruma, konumdan konuma, bireyden birime, zamandan zamana, bağlamdan bağlama değişmeyen özelliklere 'sabit (constant) özellik', diğer tarafta değişen ya da farklılaşan özelliklere ise 'değişken (variable) özellik' denir.
8 5 Örneğin cinsiyet, yaş, ağırlık, eğitim düzeyi, aylık gelir, okula devam ya da devamsızlık süresi gibi özellikler bireyden bireye farklılık gösterebilen bir özelliklerdir. Bu ve benzeri özellikler, amaçlanan bir gözlemde değişkenler olarak tanımlanır DEĞİŞKEN TÜRLERİ Değişkenler farklı şekillerde sınıflandırılabilmektedir Nitel Değişken - Nicel Değişken Bazı değişkenler, sembollerle ya da sözcüklerle ifade edilir. Bazı değişkenler ise sayılarla ifade edilir. Sözcük ya da sembollerle ifade edilen değişkenlere 'nitel (qualitative)', sayılarla ifade edilen değişkenler ise 'nicel (quantitative)' değişken olarak adlandırılır. Örneğin cinsiyet, kadın ve erkek olarak değerler alabilen iki kategorili ve nitel bir değişkendir. Bir başka örnek olarak eğitim düzeyi, okuryazar değil, okuryazar, ilkokul mezunu, ortaokul mezunu gibi değerler alabilen çok kategorili ve nitel bir değişkendir. Yaş, ağırlık, öğrenme başarısı, akademik aşarı, sıcaklık, aylık gelir gibi değişkenler ise sayılarla ifade edilir ve bunlar nicel değişkenlerdir Sürekli Değişken - Süreksiz/Kesikli Değişken Matematiksel bir kavram olarak süreklilik, herhangi iki sayının ortasında her zaman bir üçüncü sayının bulunması durumunu ifade etmektedir. Örneğin doğal sayılar ve tamsayılar kümeleri, sürekli sayılar değildir. Rasyonel sayılar kümesi ise süreklidir. Cinsiyet, eğitim düzeyi, doğum yeri, kan grubu, şube gibi değişkenler kesikli, yaş, ağırlık, akademik başarı, öğrenme başarısı, tutum gibi değişkenler süreklidir. Genellikle nitel değişkenler kesikli, nicel değişkenler ise sürekli değişkenlerdir Bağımlı Değişken - Bağımsız Değişken Herhangi bir değişken, tek başına bağımlı ya da bağımsız olarak sınıflandırılamaz. Bu sınıflamanın yapılabilmesi için en az iki değişken ve bu değişkenler arasında tanımlı bir ilişki bulunmalıdır. İki değişkenden biri diğer değişkenle ilişkilendirildiğinde, ilişkinin yönüne göre, bağımlı-bağımsız sınıflaması yapılabilir.
9 6 İlişkili iki değişkenden biri diğeri aracılığı ile (yani diğerine bağlı olarak) betimlenecek ya da açıklanacak ise açıklanan temel değişken 'bağımlı değişken (dependent variable)', bu değişkenle ilişkilendirilen diğer değişken ise 'bağımsız değişken (independent variable)' olarak adlandırılır. Örneğin, "bir sınıftaki öğrencilerin yazılı notlarının dağılımı" dikkate alındığında, sadece bir tane değişken vardır: Yazılı notları (ya da kısaca not). Bu notların 0 ile 100 arasında verildiğini düşünürsek, öğrenci başarısını ya da öğrenme başarısını temsil eden bir değişken olarak 'not' değişkeni, nicel, sürekli ve eşit aralıklı ölçek düzeyinde bir değişkendir. "Bir sınıftaki öğrencilerin notlarının cinsiyetlerine göre dağılımı" dikkate alındığında ise iki değişken söz konusudur: (1) Not ve (2) cinsiyet. Notların kendi çerisinde dağılımının değil öğrencilerin cinsiyetlerine göre dağılımı betimlenecektir. Yani söz konusu iki değişken birbiri ile ilişkilendirilmektedir. Bu durumda ilgilenilen esas değişken olarak 'not' değişkeni bağımlı değişken, notların ilişkilendirildiği cinsiyet değişkeni ise bağımsız değişken olarak sınıflandırılır ÖLÇEK VE ÖLÇEKLEME Özel kullanımıyla ölçek, genellikle tutum, ilgi, kişilik gibi duyuşsal özelliklerin gözlenmesinde ya da ölçülmesinde kullanılan özel bir veri toplama aracıdır. Diğer bir tanımlamayla ölçek, belli birimlerle birimlendirilmiş ve yapılandırılmış bir ölçme aracıdır. Bu özel kullanımının yanı sıra bir değişkenin alabileceği olası değerlere de ölçek denilmektedir. Bir değişkenin sayı ya da sembol olarak alabileceği değerler, bir ölçek üzerinde ifade edilmektedir. Bu değerlerin yani bir değişkenin alabileceği değerlerin belirlenmesi, değişkenin seçeneklerinin belirlenmesi işlemlerine de 'ölçekleme' denilmektedir. Bir değişkenin farklı şekillerde ölçeklenmesi mümkündür. Ölçekleme, toplanacak verinin niteliğini de etkilemektedir.
10 7 Örneğin bir değişken olarak yaş değişkenini dikkate alalım. Bireylerin yaşları hakkındaki bilgileri farklı şekillerde almak mümkündür. Örneğin "Yaşınız:..." şeklinde sorulan açık uçlu bir soruya, 24, 25, 34, 38 gibi verilen yanıtlarla yaş değişkenine yönelik veriler sürekli ve nicel olarak toplanabilir. Aynı değişkene yönelik veriler "Yaşınız: ( ) 20 ve altında, ( ) arası, ( ) arası, ( ) 31 ve üzeri" şeklinde sorulan bir soru ile de toplanabilir. Bu durumda elde edilen veriler, ilk duruma göre daha sınırlı olacaktır ÖLÇEK TÜRLERİ Dört tür ölçek düzeyi söz konusudur: 1. Sınıflama Ölçeği (Nominal scale) 2. Sıralama Ölçeği (Ordinal scale) 3. Eşit Aralıklı Ölçek (Interval scale) 4. Eşit Oranlı Ölçek (Ratio scale) Bu ölçek türleri, en az bilgi sağlayan ölçek türünden en çok bilgi sağlayan ölçek türüne doğru sıralı olarak verilmiştir. Aynı şekilde aralarında kapsama ilişkisi de vardır. Yani bir üst dzey, alt düzeyleri kapsamaktadır. Sınıflama ölçeği düzeyindeki bir değişken, sadece grup ya da gruba aidiyet hakkında bilgi verir. Örneğin kan grubu, doğum yeri, cinsiyet, şube, medeni durum gibi değişkenler sınıflama ölçeği düzeyinde değişkenlerdir. Sıralama ölçeği düzeyindeki değişkenler, gruba aidiyet bilgisi yanı sıra kategoriler arasında bir sıra ilişkisi de gösterir. Örneğin anne eğitim düzeyi, sıralama ölçeğinde bir değişkendir. Örneğin lise mezunu olman bir anne, ortaokul mezunu olan bir anneden daha yüksek bir eğitim düzeyine sahiptir. Eşit aralıklı ölçek düzeyindeki bir değişkende değişkenin alabileceği ardışık değerler arasında eşit mesafe vardır. Yani bu değişkenin değerlerinin yer aldığı ölçek, eşit aralıklıdır. Örneğin öğrenme başarısının bir göstergesi olarak 'not' şeklinde tanımlanan değişken, 0 ile 100 arasındaki notlardan oluşuyorsa bu değişken eşit aralık ölçeğindedir. Yani 1 notu ile 2 notu, 2 notu ile 3 notu ve benzeri arasındaki mesafeler birbirine eşittir. Eşit aralıklı ölçek düzeyindeki bir değişkende 'izafi/göreli/yapay sıfır' ya da 'izafi başlangıç noktası' tanımlıdır. Bu nokta mutlak yokluğu ifade etmez. Örneğin notu 0 olan bir öğrencinin öğrenemediği dolayısıyla öğrenme başarısı bulunmadığı söylenemez. Belki yapılan ölçmenin sınırlılığında öğrenme başarısı gözlenememiştir denilebilir. Hava sıcaklığı da benzer şekilde eşit aralıklı ölçek düzeyinde bir değişkendir.
11 8 Eşit oranlı ölçekte düzeyindeki bir değişkende de ölçekleme, eşit aralıklıdır. Fakat eşit aralık ölçeğinden farkı, 'gerçek/mutlak sıfır' noktasına sahip olmasıdır. Örneğin ağırlık, eşit oranlı ölçek düzeyinde bir değişkendir. 0kg, ağırlığın olmadığını yani mutlak yokluğu ifade eder. Ölçek türleri, bir değişkenin değerleri üzerinde yapılabilecek işlemlerin belirlenmesinde yardımcı olur. Sınıflama ölçeği düzeyindeki değişkenlerde basit sayma ve sınıflama işlemleri yapılabilir. Sıralama ölçeği düzeyindeki değişkenlerde sayma ve sınıflama işlemlerinin yanı sıra medyan, sıra farkları ve korelasyon hesaplamaları yapılabilir. Eşit aralıklı ölçek düzeyindeki değişkenlerde, toplam ve farka dayalı istatistiksel hesaplamaların tamamı kullanılabilir. Eşit oranlı ölçek düzeyinde ise çarpma ve bölme işlemleri dahil tüm işlemleri içeren istatistiksel hesaplamalar kullanılabilir BİRİM Bir değişkenin alabileceği değerler, bir birim değer ile ifade edilir. Öreğin 3cm denildiğinde santimetre, birim değer olarak 1cm uzunluğu tanımlamaktadır. Buna göre bir değişkenin ölçeklendiği birim değer 'birim' olarak ifade edilir. Birimler, 'doğal birim' ve 'yapay birim' olarak ikiye ayrılır. Metre (m), gram (gr), saniye (sn) gibi birimler, sonradan tanımlanmış birimler olarak yapay birimlerdir. 3 kişi, beş öğrenci, 6 kitap, 8 oda gibi değerlerde kullanılan kişi, öğrenci, kitap, oda, adet gibi birimler ise doğal birimlerdir ÖLÇME - DEĞERLENDİRME Ölçme ve değerlendirme birbirini tamamlayan ardışık iki süreçtir. Ölçme, bir özelliğe yönelik gözlemlerin yapılması ve bu gözlemlerin sayı ve sembollerle ifade edilmesidir. Bir başka yaklaşımla ölçme, gözlemler kümesi ile sayı ve semboller kümesi arasındaki bir eşleştirme ve bir fonksiyondur. Değerlendirme, ölçme sonuçlarını, bir ölçüte ya da ölçütler takımına göre yorumlama ve anlamlandırma sürecidir. Ölçme sonuçları tek başlarına çok bilgi vermez ve bir anlam ifade etmez. Bir takım ölçütlerle birlikte anlam kazanabilir. Örneğin, yabancı dil yeterliğinin ölçüldüğü bir sınavdan 400 puan aldığınızı düşününüz. Bu puan sizin için ne ifade eder? Bu bilginin yanı sıra "puanlama, 0 ile 500 puan arasında yapılmıştır" bilgisi verilse, 400 puanın anlamlandırılması daha kolay hale gelir. Bir başka bilgi olarak "kesme puanı 300'dür" bilgisi verilse, sonrasında "sınava katılanların puan ortalaması 385'tir" bilgisi verilse. Ancak bu ve benzeri bilgiler, birer ölçüt olarak dikkate alındığında, 400 puanın yorumlanması ve anlamlandırılması mümkün olmaktadır.
12 9 BÖLÜM 2 VERİ SETİNİN HAZIRLANMASI VE DÜZENLENMESİ Veri seti; satırlarında gözlem birimleri, sütunlarında ise değişkenler bulunan iki boyutlu bir matristir. Satır ve sütunların kesişim bölgelerine 'hücre (cell)' adı verilir. Her bir hücreye, gözlemlerin değerleri yani yapılan ölçmenin sonuçları sayı veya sembol olarak girilir. Bir hücrede herhangi bir sayı veya sembol olmaması, amaçlanan gözlemin bulunmadığını ifade eder. Veri setinde yer alan bu tür boşluklar 'kayıp veri (missing value)' olarak adlandırılır. Veri setinin hazırlanmasından önce, yerine getirilmesi gereken işlemler yani gözlem aşamaları bulunmaktadır. Öncelikle gözlenmek istenen özelliğin ve bu özellikle ilişkili değişkenlerin 'iyi' tanımlanması gerekmektedir. Bu aşama kuramsal ya da kavramsal çerçevenin oluşturulması aşamasıdır. Amaçlı gözlemlerin yapılması ve ilgilenilen özelliğe yönelik verilerin toplanması, sonraki aşamalardan biridir. Ölçmelerin hassasiyetini ve duyarlılığını artırmak için gözlemlerde sıklıkla bir 'ölçme aracı' ya da 'veri toplama aracı' kullanılır. Farklı özellikler, farklı ölçme araçları ile gözlenir. Örneğin birey özelliklerine yönelik olarak, başarı, zeka gibi bilişsel özellikler başarı testi, zeka testi gibi ölçme araçları ile; tutum, ilgi, kişilik, görüş, inanç gibi duyuşsal özellikler ölçek, envanter, anket gibi ölçme araçları ile; psikomotor beceriler ise kontrol listesi, gözlem formu gibi ölçme araçları ile gözlenebilir. Ölçme aracı kullanmak, ilgilenilen özellik hakkında veri toplamanın yaygın yollarından biridir.
13 10 Veri setinin hazırlanması, ancak amaçlanan gözlemin ya da gözlemlerin yapılmasından ve ilgilenilen özelliğe yönelik verilerin 'iyi' tanımlanmış değişkenler düzeyinde toplanmasından sonra, toplanan bu verilerin belli bir düzen içerisinde bir matris ya da çizelge üzerinde gösterilmesi işidir. Değişkenlerin 'iyi' tanımlanmış olması iki aşamaya vurgudur. Öncelikle ilgilenilen temel özellik hakkında bilgi sağlayacak 'gerekli' ve 'doğru' değişkenlerin belirlenmesi gerekmektedir. İkinci olarak bu değişkenlerin en 'iyi' bilgi verecek şekilde yani mümkün olan en üst ölçek düzeyinde ölçeklenmesi gerekmektedir. ÖRNEK Bir sınıftaki 20 öğrencinin derse karşı ilgileri gözlenmek istenmektedir. Öğrencilerin ilgi düzeyleri, bu amaçla geliştirilmiş bir ölçek kullanılarak ölçülmüş ve 0 ile 60 puan arasındaki toplam ölçek puanları ile tanımlanmıştır. Bu durumda ilgi puanı olarak tanımlanan değişken, nicel, sürekli ve eşit aralıklı ölçek düzeyinde bir değişkendir. (Bu değişken veri seti üzerinde gösterilirken 'ILGI' kısaltması kullanılacaktır.) Ayrıca derse karşı ilgileri ile ilişkili olabileceği dikkate alınarak, öğrencilerin cinsiyetleri, annelerinin eğitim düzeyleri ve ders başarıları hakkında da veri toplanmıştır. Cinsiyet (CINS): Cinsiyet kız öğrenciler için K, erkek öğrenciler için E olmak üzere iki kategorili olarak ölçeklenmiştir. Nitel, kesikli ve sınıflama ölçeği düzeyinde bir değişkendir. Anne Eğitim Düzeyi (AED): Anne eğitim düzeyleri, okuryazar değil için 1, okuryazar için 2, ilkokul mezunu için 3, ortaokul mezunu için 4, lise mezunu için 5, yüksekokul mezunu için 6, üniversite/lisans mezunu için 7 ve lisansüstü eğitim mezunu için 9 olmak üzere çok kategorili olarak ölçeklenmiştir. Nitel, kesikli ve sıralama ölçeği düzeyinde bir değişkendir. Ders Başarısı (BAS): Ders başarıları olarak yazılı sınav notları dikkate alınmıştır. Yazılı sınav notları 0 ile 100 arasında değişmektedir. Nicel, sürekli ve eşit aralıklı ölçek düzeyinde bir değişkendir. Görüldüğü gibi öncelikle gözlenecek olan özellik ve bu özellikle ilişkili diğer özellikler ayrı birer değişken olarak ayrıntılı bir şekilde tanımlanmaktadır. Her bir değişkenin alabileceği olası değerler yani o değişkene yönelik gözlemlerin sayı ve sembollerle eşleştirilme şekli, gözlem yapılmadan ve veriler toplanmadan önce belirlenmektedir. Ayrıca veri seti üzerinde gösterimde değişkeler için kullanılacak kısaltma ve semboller de önceden belirtilmektedir.
14 11 Bu örnekte gözlem birimleri öğrencilerden oluşmaktadır ve toplam 20 gözlem birimi bulunmaktadır. O halde hazırlanacak veri setinde başlık satırı hariç 20 satır bulunmalıdır. İlgi puanları, cinsiyet, anne eğitim düzeyi ve ders başarı notları olmak üzere 4 tane de değişken bulunmaktadır. O halde hazırlanacak veri setinde başlık sütunu hariç 4 sütun bulunmalıdır. Sonuç olarak veri seti, başlık satır ve sütunları dahil 21x5'lik bir matris olacaktır. Gözlem sonuçları her bir değişken düzeyinde, gözlem birimleri yani öğrencilere göre sıralı olarak aşağıda verilmiştir: ILGI : 45; 50; 40; 45; 30; 35; 33; 34; 30; 40; 42; 40; 45; 38; 41; 42; 40; 45; 37; 35 CINS : K; K; K; E; E; K; K; K; E; K; E; K; E; K; K; E; E; E; K; K AED : 1; 1; 3; 5; 7; 5; 6; 4; 2; 3; 3; 5; 5; 6; 8; 7; 6; 5; 5; 4 BAS : 80; 90; 85; 85; 60; 60; 70; 72; 75; 55; 83; 80; 75; 70; 65; 70; 80; 90; 75; 70 Şimdi bu gözlemden elde edilen ve yukarıda verilen verileri kullanarak bir veri seti oluşturalım. ILGI CINS AED BAS 1 45 K K K E E K K K E K E K E K K E E E K K 4 70 Görüldüğü gibi veri setinde tüm hücreler doludur. Yani amaçlanan her bir gözlem yapılabilmiştir ve bulunmaktadır. Bu tür veri setlerine 'eksiksiz (complete) veri seti' denilmektedir. Bazı gözlemler yapılamamış olsa idi örneğin bazı öğrencilerin annelerinin eğitim düzeyleri hakkında, bazı öğrencilerin
15 12 cinsiyetleri hakkında ve benzeri veriler elde edilememiş olsa idi, aşağıdaki gibi bir veri seti ortaya çıkabilirdi. Kayıp veriler ILGI CINS AED BAS 1 45 K K K E E K K K E E K E K K E K K 4 70 Yukarıda görüldüğü gibi veri setinin bazı hücrelerinde boşluklar bulunmaktadır. Bu boşluklar ilgili gözlemin bulunmadığını ifade etmektedir. Örneğin 10. öğrencinin cinsiyeti hakkında bir bilgi bulunmamaktadır. Yine 13. öğrencinin annesinin eğitim düzeyi hakkında bilgi bulunmamaktadır. Bu boşluklar 'kayıp veri' olarak adlandırılmaktadır. Kayıplar içeren bu tür veri setlerine 'eksik (incomplete) veri seti' denilmektedir. Bir veri setindeki kayıplar çoğaldıkça, amaçlanan özelliğe yönelik olarak elde edilen veriler azalır. Bu durumda verilerden özelliğe yönelik betimleme ve çıkarımların yapılması güçleşir. Bir takım istatistiksel düzeltmelerle belli bir orana kadar kayıplar ihmal edilebilmektedir. Kayıplar çoğaldıkça bu tür düzeltmeler de işe yaramayabilir. Bu durumda eksik gözlemlerin tamamlanması için çaba gösterilmesi belki de ölçme işleminin tekrar edilmesi gerekebilir. Veri seti hazırlama, elle yapılabileceği gibi bu amaçla kullanılabilecek bilgisayar programları ve yazılımları da bulunmaktadır. Örneğin bir Excell programı, veri seti hazırlamada kullanılabilecek işlevsel bir programdır. Bunun yanı sıra istatistiksel analizlere özel olarak hazırlanmış SPSS, MatLab gibi paket programlarda da veri seti hazırlanabilmektedir. Örneğin yukarıda verilen gözlem sonuçlarının gösterildiği bir veri seti Excell programında düzenlendiği şekliyle aşağıda gösterilmektedir.


16 13 Görüldüğü gibi Excel programında veri seti hazırlarken ilk satır başlık satırı olarak düzenlenmektedir. O nedenle satır sayısını gösteren sayılara bakarak kaç gözlem birimi olduğunu belirlerken dikkatli olmak gerekir. Ayrıca Excell programında veri seti hazırlarken ikinci bir sayfada değişkenleri ve değişkenlerin kategorilerini tanımlamak, ilerleyen aşamalarda yapılacak betimleme ve çıkarım işlemlerinde kolaylık sağlayacaktır. Benzer şekilde SPSS, MatLab gibi özel programlarda da veri seti hazırlamak mümkündür. Özellikle gözlem birimlerinin ve değişkenlerin fazla olduğu yani veri setinin büyük olduğu ölçmelerde, bu tür bilgisayar tabanlı uygulamalardan yararlanmak, büyük kolaylık sağlamaktadır.

17 14 BÖLÜM 3 FREKANS DAĞILIMLARI VE FREKANS TABLOLARININ HAZIRLANMASI Ölçme sonuçları üzerinde yani amaçlanan özelliğe yönelik gözlemlerden elde edilen veriler üzerinde yapılacak istatistiksel işlemler genel olarak aşağıdaki şekilde sınıflandırılabilmektedir. Şekil 3.1. İstatistiksel İşlemlerin Sınıflandırılması İstatistiksel işlem olarak veriler üzerinde öncelikle betimleme işlemleri yapılmaktadır. Betimleme, bir tasvir etme, genel dağılımı ortaya çıkarma, durumu olduğu gibi resmetme anlamlarına gelmektedir. Çıkarım ya da tahmin işlemleri, daha ileri düzey istatistiksel işlemleri ve genel olarak hipotez testlerini içermektedir. Veriler üzerinden yapılacak betimleme işlemleri, yine iki grupta tanımlanabilmektedir. Frekans dağılımları ile betimleme, betimleme işlemlerinin genellikle başlangıcını oluşturur. Betimsel istatistikler ise bir takım hesaplamalarla elde edilen aritmetik ortalama, mod, medyan, standart sapma gibi sayısal değerleri ifade etmektedir. Frekans, kısaca görülme sıklığıdır. Bir gözlem değerinin ya da ölçme sonucunun tüm gözlem birimleri içerisinde görülme sıklığı, bu değerin frekansı olarak belirlenir. Örneğin 30 kişilik bir sınıfta öğrencilerin öğrenme başarısını ölçmek için bir yazılı yoklama yapıldığını ve 0 ile 100 arasında notlar verildiğini düşünelim. 6 öğrenci 70, 8 öğrenci 65, diğer öğrenciler ise başkaca notlar almış olsun. Bu durumda 70 değerinin görülme sıklığı yani frekansı 6, 65 notunun görülme sıklığı yani frekansı 65 olmuş olur. Frekans dağılımlarının belirlenmesi, temelde bir sayma ve sınıflama işlemidir. Sayma ve sınıflama sonuçları, tablo ve grafikler üzerinde gösterilir. Bu nedenle tablo ve grafikle gösterme konusunda gerekli bilgi ve becerilerin kazanılmış olması önemlidir.
18 15 Frekans tabloları, bir ya da bir kaç değişkene yönelik frekansların, yapılandırılmış bir şekilde sunumudur. Tabloların gösteriminde dikkat edilmesi gereken bazı biçimsel özellikler vardır. Bunlardan bazıları aşağıda verilmiştir: 1. Her tablo için tablonun üst kısmında bir adlandırma yapılır. Bu adlandırmada tablo numarası ile birlikte betimlenen bilginin içeriği hakkında bilgi yer alır. Örneğin 'Tablo 1. Ailelerin Aylık Gelir Düzeylerinin Dağılımı' şeklindeki bir başlık, aylık gelir düzeyi değişkenine göre ölçme sonuçlarının frekans dağılımlarının betimlendiği bir tabloyu ifade eder. 2. Tablolarda görsel sadeliği sağlamak amacıyla yatay ve dikey çizgilerin mümkün olduğunca az kullanılması önerilir. 3. Tablolarda kısaltma ya da sembollere, çok gerekli olmadıkça yer verilmemelidir. Kısaltma ya da sembol kullanıldığı durumlarda, bunların ne anlama geldiği tablonun alt kısmına dip not olarak açıklanmalıdır. Örneğin bir tabloda 'ailelerin gelir düzeyi' ile ilgili bilgiler, bu başlık uzun olduğu için AGD kısaltması ile verilebilir. BU durumda AGD kısaltmasının üzerine bir asteriks (*) konulup tablonun altında '*AED: Ailelerin gelir düzeyi' açıklaması verilmelidir. 4. Tablolarda sayıların sağa yaslı şekilde verilmesi önerilir. Böylece aynı basamaklar alt alta gelir, sayıların kolay algılanmasını ve okunması sağlanmış olur. Ondalıklı sayıların gösteriminde aynı basamakların alt alta gelmesini sağlamak için sağa yaslamanın yanı sıra odalık basamak sayısının yani virgülden sonraki basamak sayısının her bir sayı için aynı olmasına dikkat etmek gerekir. Örneğin her bir ölçme sonucu, virgülden sonra iki basamak olacak şekilde gösterilirse bu tür bir standart yakalanmış olur. Frekans tablolarında temel olarak (1) frekans, (2) yüzde, (3) yığmalı frekans ve (4) yığmalı yüzde bilgileri yer alır. Frekans ölçme sonuçlarının görülme sıklığını, yüzde görülme sıklığının yüzdesini ifade eder. Yığmalı (kümülatif) frekans ise sıralı olarak verilen frekansların bir öncesi ile toplamı alınarak belirlenir. Yığmalı (kümülatif) yüzde de benzer şekilde belirlenir. Yığmalı değerlerin hesaplanabilmesi için sıralı en az üç kategori bulunmalıdır. Frekans tabloları tek bir değişkene yönelik olarak hazırlanabileceği gibi iki veya daha fazla değişken için de hazırlanabilir. Bir frekans tablosunda betimlenen değişken sayısı arttıkça, tabloda yer alan bilgilerin anlaşılması ve yorumlanması da o ölçüde güçleşir. ÖRNEK 1 Bir sınıftaki 15 öğrencinin cinsiyetleri ve sosyoekonomik düzeyleri gözlenmiştir. Cinsiyet (CINS) değişkeni, kız öğrenciler için K, erkek öğrenciler için E sembolleriyle ölçeklenen iki kategorili bir
19 16 değişkendir. Sosyoekonomik düzey (SED) değişkeni ise alt SED için 1, orta SED için 2 ve üst SED için ile kodlanan çok kategorili bir değişkendir. Bu değişkenlere yönelik ölçme sonuçları aşağıda sıralı bir şekilde verilmektedir. CINS: K; K; K; E; E; K; E; E; K; K; E; K; K; E; K SED: 1; 1; 2, 3; 3; 2, 2; 2; 1; 3; 1; 1; 2; 2; 3 Bu veriler kullanılarak hazırlanacak veri seti aşağıdaki gibidir. CINS SED 1 K 1 2 K 1 3 K 2 4 E 3 5 E 3 6 K 2 7 E 2 8 E 2 9 K 1 10 K 3 11 E 1 12 K 1 13 K 2 14 E 2 15 K 3 a) Öncelikle cinsiyet değişkenine yönelik frekans tablosunu hazırlayalım. Öğrencilerin cinsiyetleri sayıldığında 9 kız, 6 erkek öğrenci bulunduğu görülmektedir. Bu sayılar sırasıyla %60 ve %40 yüzde değerlerine karşılık gelmektedir. Cinsiyet değişkeni iki kategorili bir değişken olduğu için yığmalı değerlerin hesaplanması söz konusu değildir. Buna göre frekans tablosu aşağıda verilmiştir. Tablo 3.1. Öğrencilerin Cinsiyetlerine Göre Dağılımı Cinsiyet f % Kız 9 60,0 Erkek 6 40,0 Toplam ,0 Cinsiyet değişkeni iki kategorili bir değişken olduğu için bu tabloda yer alan bilgilerin yorumları, sade ve basit olacaktır. Örneğin burada ancak "öğrencilerin %60'ı kız, %40'ı ise erkek öğrencilerden oluşmaktadır" gibi bir yorum yapılabilir.
20 17 b) Öğrencilerin sosyoekonomik düzeylerine göre frekans dağılımları da benzer şekilde tablolaştırılabilir. SED değişkeni, çok kategorili bir değişken olduğu için yığmalı frekans ve yığmalı yüzde değerlerinin de hesaplanması mümkündür. Tablo 3.2. Öğrencilerin Sosyoekonomik Düzeylerine Göre Dağılımları Kümülatif Kümülatif SED* f % F % Alt 5 33,3 5 33,3 Orta 6 40, ,3 Üst 4 26, ,0 Toplam ,0 SED: Sosyoekonomik düzey Tablo 3.2'de görüldüğü gibi öğrencilerin %33'ü alt, %40'ı orta ve %27'si üst sosyoekonomik düzeyde yer almaktadır. Öğrencilerin çoğunluğu oluşturan kısmı (%40), orta sosyoekonomik düzeydedir. Yığmalı değerlere dikkat edilecek olursa öğrencilerin 11'i üst sosyoekonomik düzeyin altındadır. Yine öğrencilerin %73'ü üst sosyoekonomik düzeyin altındadır. c) Yukarıda değişkenler düzeyinde frekans dağılımları ayrı ayrı verilmiştir. Bu değişkenlerin frekans dağılımlarının aynı tablo üzerinde gösterilmesi de mümkündür. Tablo 3.3. Öğrencilerin Cinsiyetlerine ve Sosyoekonomik Düzeylerine Göre Dağılımı Cinsiyet Sosyoekonomik % Kümülatif Kümülatif f Düzey (Sınıf Geneli) F % Alt 4 26,7 4 26,7 Kız Orta 3 20,0 7 46,7 Üst 2 13,3 9 60,0 Ara Toplam 9 60,0 Alt 1 6, ,7 Erkek Orta 3 20, ,7 Üst 2 13, ,0 Ara Toplam 6 40,0 Genel Toplam ,0 Tablo 3.3'te yer alan bilgiler kullanılarak Tablo 1 ve Tablo 2 için yapılan yorumların yapılabileceği görülmektedir. Bunun yanı sıra "kız öğrencilerin %20'si orta sosyoekonomik düzeyde, %46,7'si ise üst sosyoekonomik düzeyin altında yer almaktadır", "orta sosyoekonomik düzeyde kız ve erkek öğrencilerin sayısı aynıdır" gibi cinsiyet ve SED'in bir arada değerlendirildiği yorumların yapılabilmesi de mümkündür. Örnek 1'de verilen cinsiyet ve sosyoekonomik düzey değişkenleri, kesikli değişkenler oldukları için bu değişkenlere yönelik frekans tabloları görece daha kolay hazırlanabilmektedir. Sürekli değişkenler söz konusu olduğunda ise frekans tabloları daha büyük olmaktadır. Bu nedenle sürekli değişkenlerin
21 18 frekans tablolarının hazırlanmasında, ölçme sonuçlarının gruplanarak verilmesi yoluna gidilebilmektedir. Örnek 2, bu tür bir uygulamaya yöneliktir. ÖRNEK 2 Bir sınıftaki 25 öğrencinin yazılı sınav notları aşağıda verilmektedir. NOT: 55; 60; 65; 75; 90; 95; 90; 80; 75; 75; 70; 65; 60; 50; 45; 40; 70; 65; 70; 70; 60; 70; 80; 75; 70 Yazılı sınav notları, bir değişken olarak, nicel, sürekli ve eşit aralık ölçeği düzeyinde bir değişkendir. Yazılı sınav notlarının frekans tablosunda betimlenmesinden önce bu notları sıralamak, sayma ve sınıflama işlemleri için kolaylık sağlayacaktır. Yazılı sınav notları sıralanmış olarak aşağıda verilmektedir. SIRALI NOTLAR: 40; 45; 50; 55; 60; 60; 60; 65; 65; 65; 70; 70; 70; 70; 70; 70; 75; 75; 75; 75; 80; 80; 90; 90; 95 a) Görüldüğü gibi sıralanmış notların frekanslarını belirlemek daha kolay hale gelmiştir. Örneğin 40 değerinin sıklığı 1, 70 değerinin frekansı 6'dır. Buna göre frekans tablosu aşağıdaki gibi hazırlanabilir. Tablo 3.4. Öğrencilerin Yazılı Notlarının Dağılımı Kümülatif Kümülatif Notlar f % F % ,0 1 4, ,0 2 8, ,0 3 12, ,0 4 16, ,0 7 28, , , , , , , , , , , , ,0 Toplam ,0 Görüldüğü gibi her bir ölçme sonucu tabloda yer almaktadır. Yazılı sınav notlarının 0 ile 100 arasında değiştiği düşünüldüğü bu aralıktaki her bir notu alan öğrenci bulunsa idi 101 satırlık bir tablo hazırlanması gerekirdi. Bu örnekte 11 farklı not olduğu için daha dar bir tablo yeterli oldu. b) Ölçme sonuçlarının çeşitliliği ve puan aralığı arttıkça frekans tablosu da o ölçüde genişleyecektir. Bu durumda ölçme sonuçlarının gruplanması yoluna gidilebilir. Gruplama, aşağıdaki aşamalarda gerçekleştirilir:
22 19 1. Puan aralığının (ranj) belirlenmesi 2. Grup sayısının belirlenmesi 3. Puan aralıklarının açıklığının belirlenmesi 4. Grup aralıklarının belirlenmesi 5. Aralık orta noktalarının belirlenmesi 6. Grup frekanslarının belirlenmesi 7. Frekans tablosunun hazırlanması Puan aralığı yani ranj, en yüksek ve en düşük ölçme sonuçlarının farkıdır. Verilen örnekte en yüksek not 95, en düşük puan 40 olduğuna göre puan aralığı 95-40=55'tir. Grup sayısı, keyfi olarak belirlenir. Grup sayısının, puan aralığını kalansız bölen bir sayıda belirlenmesi, ilerleyen aşamalarda kolaylık sağlar. Verilen örnekte grup sayısını 5 olarak belirleyelim. Puan aralıklarının açıklığı, puan aralığının grup sayısına bölünmesi ile belirlenir. Verilen örnekte bu açıklık; 55/5=11 olarak belirlenir. Grup aralıkları minimum ya da maksimum değerden başlayarak, puan açıklığı değerine göre belirlenir. Verilen örnekte gruplar aşağıdaki gibi belirlenir: 1.Grup : 40 ile 50 notlar arası 2.Grup : 51 ile 61 notlar arası 3.Grup : 62 ile 72 notlar arası 4.Grup : 73 ile 83 notlar arası 5.Grup : 84 ile 95 notlar arası Grupların puan aralıklarının orta noktaları, her bir aralığın orta noktasıdır. Buna göre verilen örnekte her bir grubun orta noktası aşağıda verildiği gibidir: 1.Grup orta noktası: 45 2.Grup orta noktası: 56 3.Grup orta noktası: 67 4.Grup orta noktası: 78 5.Grup orta noktası: 89 Grup frekansları, her bir grupta yer alan ölçme sonuçlarının sıklığını ifade etmektedir. Örneğin 1.grup için frekans, 45 ile 54 arası not alan öğrenci sayısıdır. Bu değer 3'tür. Her bir grubun frekansları aşağıda verildiği gibidir: 1.Grup frekansı: 3 2.Grup frekansı: 4
23 20 3.Grup frekansı: 9 4.Grup frekansı: 6 5.Grup frekansı: 3 Yapılan bu hesaplamalardan sonra, gruplanmış yazılı sınav notlarının frekans dağılımı aşağıdaki tabloda verilmiştir. Tablo 3.4. Gruplanmış Yazılı Sınav Notlarının Dağılımı Kümülatif Kümülatif Notlar f % F % arası 3 12,0 3 12, arası 4 16,0 7 28, arası 9 36, , arası 6 24, , arası 3 12, ,0 Toplam ,0 Tablo 3.4'de gruplanarak verilen frekanslara göre "öğrencilerin %36'sı 65 ile 74 arası not almıştır", "öğrencilerin %64'ü 75'in altında not almıştır", é25 öğrenciden 22'si 85'in altında not almıştır" gibi yorumlar yapılabilir. Frekans dağılımlarını gruplandırarak vermek, tablo gösteriminde kolaylık sağlamakla birlikte veri kaybına yol açmaktadır. Örneğin yukarıdaki tablodan, 85 ile 95 arasında not almış olan 3 öğrenci olduğu görülür. Fakat bu öğrencilerin kaç not aldığı bilinemez. O nedenle gerekli olmadıkça verileri gruplama yoluna gidilmemesi önerilir.
24 21 BÖLÜM 4 FREKANS DAĞILIMLARININ GRAFİKLE GÖSTERİLMESİ Frekans dağılımlarının betimlenmesinde frekans tablolarının kullanılmasının yanı sıra grafik gösterimleri de sıklıkla kullanılmaktadır. Grafikler, görselliği daha fazla olan betimleme biçimleridir. Bu nedenle kullanılması uygun olan durumlarda, verilerin dağılımının anlaşılmasını ve yorumlanmasını kolaylaştırmaktadır. Grafiklerin, frekans dağılımlarının betimlenmesi amacıyla kullanılmasında dikkat edilmesi gereken önemli noktalardan biri, değişkenin türüne ve karakteristiğine göre kullanılacak uygun grafik türünün seçilmesidir. Bu bölümde frekans dağılımlarının betimlenmesinde yaygın olarak kullanılan 4 grafik türü tanıtılmaktadır. Tablolarda olduğu gibi grafik kullanımında da dikkat edilmesi gereken bazı biçimsel özellikler vardır. Grafikler de tablolar gibi, bir grafik numarası ve bir içerik bilgisi ile isimlendirilir. Bu isimlendirme, grafiğin alt tarafında yer alır. Grafik üzerinde gerekli açıklama ve sayısal değerler yer almalıdır. Grafiklerde frekanslara yönelik sayılar verilebileceği gibi frekans yüzdeleri ya da bu her ikisi birden verilebilir. Dikkat edilmesi gereken nokta verilen değerlerin açık ve anlaşılır olmasıdır PASTA GRAFİĞİ (Pie Graphics) 'Daire grafiği' olarak da bilinen pasta grafiği, 360 derecelik bir dairenin dilimleri ile frekans dağılımlarının gösterildiği bir grafik türüdür. Dilimlerin büyüklüğü frekans yüzdeleri ile orantılı olacak şekilde belirlenir. Pasta grafikleri, cinsiyet, şube, kan grubu gibi kesikli ve kategorik değişkenlerin frekans dağılımlarının gösterilmesinde kullanışlıdır. Değişkenlerin kategori sayısı arttıkça, pasta grafiği daha karışık bir şekle dönüşecektir. Bu nedenle pasta grafiği, 2, 3, 4gibi az kategorili değişkenlerde, daha fazla çok kategorisi olan değişkenlere göre daha kullanışlıdır. ÖRNEK 1 Bir sınıftaki 15 öğrencinin cinsiyetleri aşağıdaki gibidir. CINS: K; K; K; E; E; K; E; E; K; K; E; K; K; E; K
25 22 Görüldüğü gibi öğrencilerin 9'u kız, 6'sı erkek öğrencilerden oluşmaktadır. Bu değerlerin yüzde karşılığı sırasıyla %60 ve %40'tır. Buna göre çizilecek pasta grafiğinde, 'lik toplam alanın %60'lık dilimi kız öğrencilerin frekansını, %40'lık dilimi ise erkek öğrencilerin frekansını göstermelidir. 360 x %60 = 360 x 0,60 = x %40 = 360 x 0,40 = 144 Buna göre kız öğrencilerin frekansı 'lik, erkek öğrencilerin frekansı ise 'lik daire dilimi ile gösterilecektir. Grafikte dilimlerin dereceleri gösterilmez. Bu dereceler dilimlerin büyüklüklerinin hesaplanmasında kullanılır. Grafik aşağıda verilmiştir. Erkek 6 40% Kız 9 60% Grafik 4.1. Öğrencilerin Cinsiyetlerine Göre Dağılımı 4.2. SÜTUN GRAFİĞİ 'Bar grafiği' olarak da bilinen sütun grafiği, frekansların kartezyen sistem üzerinde sütun yükseklikleri ile eşleştirildiği bir gösterim biçimidir. Sütun grafiği 'yatay' ve 'dikey' olmak üzere iki biçimde kullanılabilmektedir. Alışıldık olan gösterim biçimi dikey sütun grafiğidir. Bu grafikte, değişken ve değişkenin kategorileri yatay eksen ile, frekanslar ise dikey eksen ile temsil edilir. Yatay sütun grafiğinde ise eksenlerin yerleri değişir. Frekans ekseninde frekans değerleri eşit aralıklı olarak yer alır. Pasta grafiğinde olduğu gibi sütun grafiği de kesikli ve kategorik değişkenlerin frekans dağılımlarının gösterilmesinde kullanışlı bir grafik türüdür. Sütun grafiğinin ayırıcı önemli bir özelliği, sütunlar arasında boşluk bırakılmasıdır. Bu durum, kesikli değişkenlerin yani sınıflama ve sıralama ölçekleri düzeyindeki veriler için kullanılan bir grafik türü olmasından kaynaklanmaktadır. Bilindiği gibi bu ölçek düzeylerindeki değişkenlerde, değişkenlerin
, alt SED, orta SED ve üst SED kategorilerine göre aşağıdaki gibidir.")
 Grafik 4.")
26 23 kategorileri arasında başka bir kategori yer almamakta ve değişkenin kategorileri eşit aralıklı olarak ölçeklenmemektedir. ÖRNEK 2 Bir sınıftaki 15 öğrencinin sosyoekonomik düzeyleri (SED), alt SED, orta SED ve üst SED kategorilerine göre aşağıdaki gibidir. SED: Alt; Alt; Orta, Üst; Üst; Orta, Orta; Orta; Alt; Üst; Alt; Alt; Orta; Orta; Üst Görüldüğü gibi öğrencilerin 5'i alt SED'de, 6'sı orta SED'de ve 4'ü üst SED'de yer almaktadır. Bu frekanslar sırasıyla %33,3, %40 ve %26,7 frekans yüzdelerine karşılık gelmektedir. O halde sütun grafiği aşağıdaki şekillerde çizilebilir. Grafik 4.2. Öğrencilerin Sosyoekonomik Düzeylerine Göre Dağılımı (Dikey) Grafik 4.3. Öğrencilerin Sosyoekonomik Düzeylerine Göre Dağılımı (Yatay)
27 HİSTOGRAM Histogram, sürekli değişkenlerin frekans dağılımlarının betimlenmesinde kullanılan, özel bir sütun grafiğidir. Kesikli verilerde kullanılması daha uygun olan sütun grafiği ile histogram arasındaki temel fark, histogramda sütunlar arasında boşluk bırakılmamasıdır. Bu durum histogramın sürekli değişkenler yani en az eşit aralık ölçeğindeki değişkenlerin frekans dağılımlarının gösterilmesinde kullanılmasıdır. Sütun grafiğine benzer şekilde histogram da kartezyen sistemde çizilmektedir. Dikey eksen frekans ekseni, yatay eksen ise değişken eksenini tanımlamaktadır. Yani değişkenin değerleri yatay eksende ve eşit aralıklı olarak, bu değerlerin frekansı ise dikey eksende ve yine eşit aralıklı olarak gösterilir. Sürekli değişkenlere yönelik frekans dağılımlarında olduğu gibi histogramlarda da gerekli durumlarda ölçme sonuçlarının gruplanarak verilmesi mümkündür. Fakat gruplama, veri kaybına yol açacağı için rasyonel ve kabul edilebilir bir gerekçe olmaksızın gruplama yapılmaması önerilir. Verilerin gruplanarak sunulmasının kabul edilebilir bir gerekçesi, değerlerin çok geniş bir aralıkta yayılma gösteriyor olmasıdır. ÖRNEK 3 Bir sınıftaki 25 öğrencinin yazılı sınav notları aşağıda verilmektedir. NOT: 55; 60; 65; 75; 90; 95; 90; 80; 75; 75; 70; 65; 60; 50; 45; 40; 70; 65; 70; 70; 60; 70; 80; 75; 70 Yazılı sınav notları, nicel, sürekli ve eşit aralık ölçeği düzeyinde bir değişkendir. Bu nedenle bu değişkenin frekans dağılımının betimlenmesinde uygun grafik türlerinden biri histogramdır. a) Gruplandırılmamış Notlara Göre Histogram Çizimi Histogram çizmeden önce bu notları sıralamak ve frekans tablosunu oluşturmak, sayma ve sınıflama işlemleri için kolaylık sağlayacaktır. Yazılı sınav notları sıralanmış olarak aşağıda verilmektedir. SIRALI NOTLAR: 40; 45; 50; 55; 60; 60; 60; 65; 65; 65; 70; 70; 70; 70; 70; 70; 75; 75; 75; 75; 80; 80; 85; 85; 90 Görüldüğü gibi öğrencilerden 1'i 40, 1'i 45, 1'i 50, 1'i 55, 3'ü 60, 3'ü 65, 6'sı 70, 4'ü 75, 2'si 80, 2'si 985 ve 1'i 90 not almıştır. Bu frekans değerlerinin yüzdeleri sırasıyla %4, %4, %4, %4, %12, %12, %24, %16, %8, %8 ve %4'tür. Buna göre frekans tablosu aşağıda verilmiştir.


28 25 Tablo 4.1. Öğrencilerin Yazılı Notlarının Dağılımı Kümülatif Kümülatif Notlar f % f % ,0 1 4, ,0 2 8, ,0 3 12, ,0 4 16, ,0 7 28, , , , , , , , , , , , ,0 Toplam ,0 Öğrencilerin yazılı notlarının frekans dağılımına göre çizilecek histogramda yatay eksende 11 değer için sütun çizilmesi gerekmektedir. Yatay eksende 45 ile 95 arasındaki değerler eşit aralıklı olarak, 5'er 5'er artacak şekilde verilebilir. Frekans değerlerine bakıldığında ise en düşük 1 en yüksek 6 değeri görülmektedir. O halde dikey eksende 0'dan 6'ya kadar değerlerin gösterilmesi yeterlidir. Bu değerlerin 1'er 1'er artması gerekmektedir. Buna göre çizilen histogram aşağıda gösterilmektedir. Grafik 4.4. Öğrencilerin Yazılı Sınav Notlarının Dağılımı Histogramı çizmek istatistik öğrenmeleri için öngörülen davranışlardan biridir. Bunun devamında bir diğer davranış ise çizilmiş bir histogramın yorumlanmasıdır. Grafik 4.4'te yer alan frekans dağılımları için "öğrencilerin %20'si 70 not almıştır", öğrencilerin%12'si 60'ın altında, %20'si 75'in üzerinde not almıştır", "toplam öğrenci sayısı 25, 70 ve üzerinde not alan öğrenci sayısı ise 15'tir" gibi betimsel yorumlar yapmak mümkündür.
29 26 b) Gruplandırılmış Notlara Göre Histogram Çizimi Grafik 4'te verilen histogram, veriler uygun olduğu ve 11 değerde toplandığı için gruplama yapmaya gerek kalmadan çizilebilmiştir. Yazılı sınav notları daha geniş bir aralıkta yayılsa ve çeşitlense idi gruplama yapmadan histogram çizmek zorlaşacaktı. Şimdi aynı verileri kullanarak gruplandırılmış notlara göre histogram çiziminin nasıl yapıldığını görelim. Bunun için öncelikle gruplandırılmış notlara göre frekans tablosu hazırlayalım. Gruplandırılmış yazılı notlarına yönelik frekans tablosunun hazırlanmasında yapılacak işlemler aşağıda aşamalı olarak açıklanmıştır. 1. Ranjın belirlenmesi: Verilen örnekte notların ranjı = 50'dir. 2. Grup sayısının belirlenmesi: Grup sayısını 5 olarak belirleyelim. 3. Puan aralıklarının açıklığının belirlenmesi: Puan aralıkları açıklığı 50 / 5 = 10 olur. 4. Grupların puan aralıklarının belirlenmesi: 1.Grup puan aralığı: 40 ile 49 not arası 2.Grup puan aralığı: 50 ile 59 not arası 3.Grup puan aralığı: 60 ile 69 not arası 4.Grup puan aralığı: 70 ile 79 not arası 5.Grup puan aralığı: 80 ile 90 not arası 5. Grup orta noktalarının belirlenmesi: 1.Grup orta noktası: 45 2.Grup orta noktası: 55 3.Grup orta noktası: 65 4.Grup orta noktası: 75 5.Grup orta noktası: Grup frekanslarının belirlenmesi: 1.Grup frekansı: 2 2.Grup frekansı: 2 3.Grup frekansı: 6 4.Grup frekansı: 10 5.Grup frekansı: 5 7. Gruplandırılmış frekans tablosunun oluşturulması: Gruplandırılmış frekans tablosu aşağıda verilmiştir. Tablo 4.2. Gruplandırılmış Yazılı Sınav Notlarının Dağılımı Kümülatif Kümülatif Notlar Orta Nokta f % f % arası ,0 2 8, arası ,0 4 16, arası , , arası , , arası , ,0 Toplam ,0

30 27 Frekans tablosu hazırlandıktan sonra gruplandırılmış notlara yönelik histogram çizilmeye başlanabilir. Histogramda bitişik 5 sütun yer alacaktır. Bu sütunların taban orta noktaları yukarıdaki frekans tablosunda verilen orta nokta değerlerine gelecektir. Sütunların kenarları ise grupların puan aralıklarının alt ve üst sınırlarına gelecektir. Buna göre çizilen histogram aşağıda verilmiştir. Grafik 4.5. Öğrencilerin Gruplandırılmış Yazılı Sınav Notlarının Dağılımı Grafik 4.5'te betimlenen frekans dağılımlarına göre "öğrencilerin %40'ı 70 ile 79 arasında not almıştır", "60'ın altında not alan 4 öğrenci vardır" gibi betimsel yorumlar yapılabilir. Fakat dikkat edilirse örneğin 55 alan kaç öğrenci olduğu ya da 55 alan öğrenci olup olmadığı anlaşılamamaktadır. Bu durum, gruplamadan kaynaklanan bir sınırlılıktır ÇİZGİ GRAFİĞİ Çizgi grafiği histograma göre daha kolay çizilebilen ve daha alışıldık bir grafik türüdür. Çizgi grafiği de kartezyen düzlemde çizilir. Yatay eksen değişken ve değişkenin değerlerinin yer aldığı, dikey eksen ise frekans değerlerinin yer aldığı eksenlerdir. Her iki eksendeki değerler de eşit aralıklı olarak eksene yerleştirilir. Çizgi grafiği, yatay eksende ölçme sonuçları yani değişkenin değerleri ile dikey eksende bu değerlerin frekanslarının kesişim noktalarının belirlenmesi ve bu noktaların ardışık olarak düz çizgilerle birleştirilmesi ile elde edilir. Çizgi grafiği, histogram da olduğu gibi sürekli değişkenlerin frekans dağılımlarının betimlenmesinde kullanılan bir grafik türüdür. Çizgi grafiği süreklilik gösterir.

31 28 Çizgi grafiği sürekli değişkenlere yönelik olarak sıklıkla kullanılan bir grafik türü olmakla birlikte özellikle gözlem sayısının az olduğu durumlarda yanıltıcı olabilmektedir. Bu nedenle çizgi grafiği kullanmada ve yorumlamada dikkatli olunması gerekmektedir. ÖRNEK 4 Örnek 3'teki yazılı sınav notlarının frekans dağılımlarının betimlendiği çizgi grafiği aşağıda verilmiştir. Grafik 4.6. Öğrencilerin Yazılı Notlarının Dağılımı Çizgi grafiğinin kullanılmasında dikkatli olunması gerekmektedir. Grafik 6'ya göre örneğin 41, 42, 43 notlarını alan 1'er öğrenci olduğu anlaşılmaktadır. Oysaki veri setinde bu notları alan öğrenci yoktur. Bu nedenle çizgi grafiği yanıltıcı olabilmektedir. Histogramda olduğu gibi çizgi grafiğinde de gruplandırılmış verilere göre yanıltıcı durum daha da artar. grafik çizmek mümkündür. Fakat bu durumda yukarıda açıklanan
32 29 BÖLÜM 5 MERKEZİ EĞİLİM ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel sayma ve sınıflama işlemleri ile elde edilen frekans tabloları ve grafik gösterimleri, betimlemenin yol ve yöntemlerinden biridir. Bunun yanı sıra 'betimsel istatistikler (descriptive statistics)' olarak adlandırılan bazı sayısal değerler kullanılarak da betimleme yapılabilmektedir. Betimsel istatistikler, (1) merkezi eğilim ölçüleri ve (2) merkezden dağılma ölçüleri olmak üzere iki grupta sınıflandırılmaktadır: Şekil 5.1. Betimsel İstatistiklerin Sınıflandırılması Merkezi eğilim ölçüleri, 'merkeze yığılma ölçüleri' olarak da ifade edilebilmektedir. Aritmetik ortalama, mod, medyan, yüzdelik gibi nokta değerler, merkezi eğilim ölçüleridir. Diğer bir deyişle bu ölçüler, tek bir nokta belirtir. Bu nokta değerler verilerin yığılma noktaları olarak ilgilenilen özelliğe dönük betimlemelerin yapılmasında dikkate alınabilir. Merkezi dağılım ölçüleri, 'merkezden yayılma ölçüleri' olarak da ifade edilebilmektedir. Standart sapma, varyans, ranj, çeyrek sapma gibi değerler, merkezden dağılma ölçüleridir. Bu ölçüler, merkez ya da ölçüt olarak belirlenen noktalara göre verilerin yayılması, çeşitlenmesi ya da farklılaşması hakkında bilgi verir. Veri setinin karakteristiğine ve verilerin dağılımına göre uygun betimsel istatistiklerin kestirilmesi gerekir. Her betimsel istatistik her veri setinde anlamlı olmayabilir. Bu nedenle her bir betimsel istatistiğin hesaplanmasının yanı sıra hangi durumlarda kullanılabilir olduğunun da bilinmesi önemlidir. Aksi durumda elde edilen sayılar, yanıltıcı olabilir, yanlış ya da eksik yorumların yapılmasına yol açabilir.
33 30 Betimsel istatistikler tek başına, ilgilenilen özellik hakkında fazlaca bilgi sağlamaz. Birden fazla betimsel istatistik bir arada değerlendirilerek ya da birden fazla gruba/örnekleme yönelik betimsel istatistikler bir arada değerlendirilerek anlamlı betimsel yorumlar yapmak mümkündür. Bu bölümde betimsel istatistiklerden merkezi eğilim ölçüleri grubunda yer alan 4 istatistik hakkında bilgi verilmektedir ARİTMETİK ORTALAMA 1 Aritmetik ortalama (mean); her bir gözleme yönelik ölçme sonuçlarının toplamının gözlem sayısına bölünmesi ile elde edilen bir nokta değerdir. Aynı şekilde hesaplanmakla birlikte evren ortalaması ve örneklem ortalaması farklı sembollerle formülleştirilmektedir. Evrenden elde edilen veriler üzerinde hesaplama yapılıyorsa, ortalama 'evren ortalaması (population mean)' olarak isimlendirilir. Evren ortalamasının formülü aşağıda verilmiştir: Örneklemden elde edilen veriler üzerinde hesaplama yapılıyorsa ortalama, 'örneklem ortalaması (sample mean)' olarak isimlendirilir. Örneklem ortalamasının formülü aşağıda verilmiştir: Ortalama, normal dağılım gösteren ve en az eşit aralıklı ölçek düzeyinde olan sürekli verilerde, en 'sağlam' merkezi eğilim ölçüsü olarak bilinir. Bu varsayımları sağlayan verilerde ortalama, verilerin tamamını temsil eden bir sayısal değer olarak dikkate alınabilir. Dikkat edilmesi gereken noktalardan biri, ortalama kestiriminin sürekli yani en az eşit aralıklı ölçek düzeyindeki değişkenler için anlamlı olduğudur. Cinsiyet, eğitim düzeyi, sınıf, şube, doğum yeri gibi kesikli verilerde ortalama, anlamlı bir istatistik değildir. Örneğin cinsiyet değişkeni için kız 1, erkek 2 olarak kodlanıp ortalama 1,63 olarak hesaplansa, bu sayıya karşılık gelen bir cinsiyet kategorisi bulunmadığı için bu sayı da anlamlı olmayacaktır. 1 Aritmetik ortalama dışında, geometrik ortalama, harmonik ortalama gibi başkaca ortalama değerler de bulunmaktadır. Fakat bunlar içerisinde en bilindik olan ve en sık kullanılan aritmetik ortalamadır. Bu nedenle bundan sonraki bölümlerde aritmetik ortalama yerine 'ortalama' kullanımı tercih edilecektir. 'Ortalama' kullanımı, bundan sonraki bölümlerde, aritmetik ortalamayı ifade etmektedir.

34 31 Diğer bir önemli nokta ortalamanın, normal dağılım gösteren verilerde daha 'sağlam' bilgi vermesidir. Düşük ya da yüksek değerlere doğru yığılma gösteren yani çarpık dağılımlarda ortalama, yanıltıcı olabilmekte,yanlış ya da eksik yorumların yapılmasına yol açabilmektedir. Ortalama, uç noktalardan aşırı etkilenen bir istatistiktir. Uç nokta, grubun ya da örneklemin genelinden manidar düzeyde ayrışan ölçme sonuçlarını ifade etmektedir. Örneğin bir yazılı yoklamada 2 öğrenci 40'ın altında diğer öğrenciler ise 50'nin üzerinde notlar almışsa, 40'ın altındaki bu notlar uç nokta oluşturur ve sınıf ortalamasını aşağıya çeker. Normal dağılım gösteren veriler, uç noktalardan, manidar düzeyde etkilenmez. Bu nedenle ortalamanın kullanılmasında verilerin dağılımına dikkat edilmesi gerekir. ÖRNEK 1 12 öğrencinin günlük bilgisayar kullanım süreleri şu şekildedir: 2sa; 3sa; 1sa; 1,5sa; 1sa; 4sa; 2,5sa; 2sa; 3sa; 2sa; 1,5sa; 2sa Buna göre bu öğrencilerin günlük ortalama bilgisayar kullanma süresini hesaplayalım. Bunun için ölçme sonucu olarak verilen 12 sayıyı toplayıp 12'ye bölmemiz gerekir. Bu 12 öğrencinin günlük bilgisayar kullanma sürelerinin ortalaması 2,125 saattir. Yukarıda açıklanan normal dağılım gösterme koşulunun sağlanabilmesi için daha fazla sayıda veriye ihtiyaç vardır. Normal dağılımın sağlandığı bir örnekte bu istatistik "öğrenciler, günlük ortalama 2,125sa bilgisayar kullanmaktadır" şeklinde bir yorumun yapılmasını mümkün kılar MEDYAN (ORTANCA) Medyan (median); küçükten büyüğe doğru sıralanmış verilerin tam ortasında kalan değerdir. Medyan, sıralanmış verileri %50 %50 olarak ikiye bölen noktadır ve grubun yarısı hakkında bilgi verir. Medyan, sıralama işlemine dayalı olduğu için en az sıralama ölçeği düzeyindeki değişkenlerde anlamlı bir betimsel istatistiktir. Cinsiyet, şube, doğum yeri, okul türü gibi sınıflama ölçeği düzeyindeki

35 32 kategorik değişkenlerde medyan anlamlı değildir. Bu tür değişkenlerde kategoriler arasında bir sıra ilişkisi bulunmamaktadır. Sürekli verilerde ortalama, medyana göre daha 'sağlam' bir istatistiktir. Bununla birlikte değişkene yönelik verilerin dağılımı normal dağılımdan sapma gösterdiği ya da uç noktaların etkisinin olduğu durumlarda ortalama yanıltıcı olur. Bu durumda ortalama yerine medyanın dikkate alınması önerilir. ÖRNEK 2 a) Veri Sayısı Tek Olduğunda Bir sınıftaki 25 öğrencinin bireysel kitaplığında bulunan kitap sayıları şu şekildedir: 12; 15; 10; 8; 12; 16; 20; 47; 22; 16; 18; 15; 16; 19; 23; 45; 20; 16; 10; 15; 7; 20; 16; 10; 11 Önce, daha kolay okuyabilmek için verileri sıralayalım. Sıralı veriler aşağıda verilmiştir: 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; 47 Verilerde uç nokta olarak 45 ve 47 değerleri dikkat çekmektedir. Bunların altında yer alan en yüksek değer 23'tür. Arada 22 puanlık bir fark var. Yukarıda açıklandığı gibi bu uç noktalar ortalamayı yukarı çekecek ve yanıltıcı olacaktır. Bunu görmek için hem 25 verinin ortalamasını hem bu iki veri ihmal edildiğinde kalan 23 verinin ortalamasını hesaplayalım: Görüldüğü gibi uç noktalar ortalamanın manidar düzeyde yükselmesine neden olabilmektedir. Bu durumda ortalama yerine medyan kullanılması daha doğru olacaktır. Veri setinde 25 veri olduğuna göre sıralama yapıldıktan sonra 13. sıradaki değer medyanı verecektir. 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; sıra

36 33 Kitap sayısını gösteren ölçme sonuçlarının medyanı 16'dır. Bu değer grubun yarısı hakkında bilgi verir. Yani "öğrencilerin yarısının bireysel kitaplığında 16 ve üzerinde kitap bulunmaktadır" ya da "öğrencilerin yarısının kitaplığında 16 ve altında kitap bulunmaktadır" şeklinde betimsel yorumlar yapılabilir. b) Veri Sayısı Çift Olduğunda Yukarıdaki örnekte 25 öğrenci bulunmaktaydı. Bu durumda sıralanmış verilerin tam ortasında 13. sıradaki veri kalmaktadır. Peki veri sayısı çift sayı olsaydı! Örneğin kitap sayıları aşağıdaki gibi 24 öğrenciye yönelik olsaydı: 15,5 Kitap Sayısı: 0; 2; 10; 10; 10; 11; 12; 12; 13; 14; 15; 15; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; sıra 13. sıra Bu durumda ortada iki sayı değeri kalmaktadır: 12 ve 13. sıradaki sayılar. 12. sıradaki değer 15, 13. sıradaki değer 16'dır. Medyan bu iki değerin ortalamasıdır. O halde medyan 15,5 olarak elde edilir: 5.3. MOD (TEPE NOKTASI) Mod, frekansı yani sıklığı en fazla olan değerdir. Sütun grafiği, histogram ya da çizgi grafiği gibi grafiklerde, dağılımın maksimum noktasını ifade eden frekans değeri, mod olarak belirlenir. Mod, sınıflama ölçeği düzeyindeki değişkenlerde dahil olmak üzere her tür değişkende anlamlı bir betimsel istatistiktir. Bir veri setinde görülme sıklığı en yüksek olan bir tane değer bulunabileceği gibi birden fazla değer için de görülme sıklığı eşit ve en yüksek olabilir. Mod olarak tek bir değerin belirlenebildiği değişkenlere 'tek modlu değişken' denir ve bu değişkenin değerlerinin dağılımı tek tepeli bir dağılım gösterir. Birden fazla mod değeri olan değişkenlere ise 'çok modlu değişken' denir ve bu değişkenlerin gözlenen değerlerinin dağılımı çok tepeli dağılım gösterir. Örnek olarak aşağıda iki farklı dağılım eğrisi gösterilmektedir.

37 34 Grafik 5.1. Normal Dağılım Eğrisi Grafik 5.2. Sinüs Eğrisi ÖRNEK 3 Bir sınıftaki 25 öğrencinin yazılı sınav notları aşağıda verilmektedir: NOT: 55; 60; 65; 75; 90; 95; 90; 80; 75; 75; 70; 65; 60; 50; 45; 40; 70; 65; 70; 70; 60; 70; 80; 75; 70 SIRALI NOTLAR: 40; 45; 50; 55; 60; 60; 60; 65; 65; 65; 70; 70; 70; 70; 70; 70; 75; 75; 75; 75; 80; 80; 85; 85; 90 Görüldüğü gibi en sık tekrar eden ya da frekansı en yüksek olan not 70'dir. 70 değerinin frekansı 6'dır. Bu durumda yazılı notlarının modu 70 olur. Yazılı notlarının histogramı çizildiğinde de mod yani tepe noktasının 70 olduğu açık bir şekilde görülmektedir. Söz konusu histogram aşağıda verilmektedir: Grafik 5.3. Yazılı Notlarının Dağılımı
38 35 Eğer veri setinde birden fazla mod değeri olsaydı örneğin 70 notu 6 defa gözlenirken, 60 notu ve 85 notu da 6 defa gözlenmiş olsaydı, bu değişken çok modlu bir değişkendir denilirdi. Dağılımın çok tepeli olması, normal dağılımdan sapma olduğunun bir göstergesidir. Bu durumda normal dağılım göstermesi durumunda kullanılacak istatistikler ve istatistiksel yönetmelerin kullanılması yanıltıcı olabilir YÜZDELİK VE ÇEYREK SAPMA Yüzdelik; küçükten büyüğe doğru sıralanmış verilerin belli bir yüzdesini altında bırakan noktadaki gözlenen değerdir. 'Y yüzde' sembolü ile gösterilir. Örneğin; Y 20; sıralanmış verilerin %20'sini aşağısında bırakan sıradaki gözlenen değeri, Y 25; sıralanmış verilerin %25'ini aşağısında bırakan sıradaki gözlenen değeri, Y 50; sıralanmış verilerin %50'sini aşağısında bırakan sıradaki gözlenen değeri, Y 75; sıralanmış verilerin %75'ini aşağısında bırakan sıradaki gözlenen değeri, ifade eder. Çeyreklik (quartile) ise sıralanmış verilerin çeyrek yani %25'lik dilimlerinin başlangıç ve bitiş noktalarında yer alan değerleri ifade eder. Dolayısıyla çeyreklik değerler aynı zamanda yüzdelik değerlerle ifade edilebilir. Çeyreklik, 'Q' sembolü ile ifade edilir. Teorik olarak, sıralanmış bir veri setinde 4 çeyrek bölüm vardır. Dördüncü çeyreklik, verilerin %100'ünün yani tamamının bir üstündeki değeri ifade eder. Bu nedenle pratikte dördüncü çeyreklik kullanılmaz. Birinci çeyreklik Q 1, ikinci çeyreklik Q 2 üçüncü çeyreklik Q 3 sembolleri ile gösterilir. Birinci çeyreklik 25. yüzdelik ile ikinci çeyreklik 50. yüzdelik ile üçüncü çeyreklik 75. yüzdelik ile örtüşür. Q 1=Y 25 Q 2=Y 50 Q 3=Y 75 Çeyreklik değerlerin hesaplanmasında hangi sıradaki gözlenen değerin çeyreklik olduğunun belirlenmesinde aşağıdaki formüller kullanılabilir:
39 36 Yüzdelik ve çeyreklik, en az eşit aralıklı ölçek düzeyindeki değişkenlerde anlamlı bir istatistiktir. Cinsiyet, medeni durum, şube gibi sınıflama ölçeği düzeyindeki değişkenlerde bu istatistik anlamlı değildir. Eğitim düzeyi, sınıf gibi sıralama ölçeği düzeyindeki değişkenlerde ise yüzdelik ve çeyreklik yerine 'sıra farkları (rank)' kullanılmaktadır. ÖRNEK 4 Örnek 2'de verilen öğrencilerin bireysel kitaplıklarında bulunan kitap sayısı gözlem değerleri için yüzdelik ve çeyreklik değerler hesaplaması yapalım. Bunun için söz konusu 25 gözlem değeri aşağıda küçükten büyüğe doğru sıralanmış olarak verilmiştir. 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; 47 a) 10. yüzdelik değerini hesaplayalım. 10. yüzdelik, sıralanmış verilerin %10'unu aşağısında bırakan sıradaki gözlenen değer olacaktır. 25 veri olduğuna göre 25'in %10'u 2,5 olarak hesaplanır. O halde 10. yüzdelik 2,5 veriyi aşağıda bırakan sıradaki yani üçüncü sıradaki değer olacaktır. O değer 10'dur. 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; 47 Y 10 b) 25. yüzdelik yani birinci çeyreklik değerini hesaplayalım. 25. yüzdelik, sıralanmış verilerin %25'ini aşağısında bırakan sıradaki gözlenen değer olacaktır. 25 veri olduğuna göre 25'in %25'i 6,25 olarak hesaplanır. O halde 25. yüzdelik 6,25 veriyi aşağıda bırakan sıradaki yani yedinci sıradaki değer olacaktır. O değer 12'dir. 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; 47 Y 25 c) 40. yüzdelik değerini hesaplayalım. 40. yüzdelik, sıralanmış verilerin %40'ını aşağısında bırakan sıradaki gözlenen değer olacaktır. 25 veri olduğuna göre 25'in %40'ı 10 olarak hesaplanır. O halde 40. yüzdelik 10 veriyi aşağıda bırakan sıradaki yani on birinci sıradaki değer olacaktır. O değer 20'dir. 7; 8; 10; 10; 10; 11; 12; 12; 15; 15; 15; 16; 16; 16; 16; 16; 18; 19; 20; 20; 20; 22; 23; 45; 47 Y 40
40 37 BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel sayma ve sınıflama işlemleri ile elde edilen frekans tabloları ve grafik gösterimleri, betimlemenin yol ve yöntemlerinden biridir. Bunun yanı sıra 'betimsel istatistikler (descriptive statistics)' olarak adlandırılan bazı sayısal değerler kullanılarak da betimleme yapılabilmektedir. Betimsel istatistikler, (1) merkezi eğilim ölçüleri ve (2) merkezden dağılma ölçüleri olmak üzere iki grupta sınıflandırılmaktadır: Şekil 6.1. Betimsel İstatistiklerin Sınıflandırılması Merkezi eğilim ölçüleri, 'merkeze yığılma ölçüleri' olarak da ifade edilebilmektedir. Aritmetik ortalama 2, mod, medyan, yüzdelik gibi nokta değerler, merkezi eğilim ölçüleridir. Diğer bir deyişle bu ölçüler, tek bir nokta belirtir. Bu nokta değerler verilerin yığılma noktaları olarak ilgilenilen özelliğe dönük betimlemelerin yapılmasında dikkate alınabilir. Merkezi dağılım ölçüleri, 'merkezden yayılma ölçüleri' olarak da ifade edilebilmektedir. Standart sapma, varyans, ranj, çeyrek sapma gibi değerler, merkezden dağılma ölçüleridir. Bu ölçüler, merkez ya da ölçüt olarak belirlenen noktalara göre verilerin yayılması, çeşitlenmesi ya da farklılaşması hakkında bilgi verir. Veri setinin karakteristiğine ve verilerin dağılımına göre uygun betimsel istatistiklerin kestirilmesi ve dikkate alınması gerekir. Her betimsel istatistik her veri setinde anlamlı olmayabilir. Bu nedenle her 2 Aritmetik ortalama dışında, geometrik ortalama, harmonik ortalama gibi başkaca ortalama değerler de bulunmaktadır. Fakat bunlar içerisinde en bilindik olan ve en sık kullanılan aritmetik ortalamadır. Bu nedenle bundan sonraki bölümlerde aritmetik ortalama yerine 'ortalama' kullanımı tercih edilecektir. 'Ortalama' kullanımı, bundan sonraki bölümlerde, aritmetik ortalamayı ifade etmektedir.
41 38 bir betimsel istatistiğin hesaplanmasının yanı sıra hangi durumlarda kullanılabilir olduğunun da bilinmesi önemlidir. Aksi durumda elde edilen sayılar, yanıltıcı olabilir, yanlış ya da eksik yorumların yapılmasına yol açabilir. Betimsel istatistikler tek başına, ilgilenilen özellik hakkında fazlaca bilgi sağlamaz. Birden fazla betimsel istatistik bir arada değerlendirilerek ya da birden fazla gruba/örnekleme yönelik betimsel istatistikler bir arada değerlendirilerek anlamlı betimsel yorumlar yapmak mümkündür. Bu bölümde betimsel istatistiklerden merkezden dağılma ölçüleri grubunda yer alan 4 istatistik hakkında bilgi verilmektedir STANDART SAPMA 'Standart kayma' olarak da ifade edilen standart sapma (standard deviation); bir veri setinde her bir verinin ortalamadan uzaklıklarının standartlaştırılmış bir ölçüsüdür. Evren standart sapması ve örneklem standart sapması, farklı sembollerle ifade edilmenin yanı sıra farklı formüllerle hesaplanır. Evren Standart Sapması Örneklem Standart sapması Formüllerde yer alan; X i, her bir gözlem birimine yönelik ölçme sonucunu µ, evren ortalamasını,, örneklem ortalamasını, n, örneklem büyüklüğünü yani örneklemde yer alan nesne yada kişi sayısını, N, evren büyüklüğünü yani evrende yer alan gözlem birimi sayısını ifade etmektedir. Dikkat edilirse örneklem standart sapmasının belirlenmesinde (n-1)'e bölme işlemi yapılmaktadır. Bu değer 'serbestlik derecesi' olarak isimlendirilir. Daha az yanlı yani daha titiz bir kestirim sağlamaktadır. Standart sapma, ortalamaya bağlı olarak hesaplanan bir istatistiktir. Ortalamada olduğu gibi standart sapma da sürekli değişkenlerde ve özellikle normal dağılım gösteren değişkenlerde kullanışlıdır. Değişkenin sürekli yani en az eşit aralık ölçeğinde olduğu ve değişkenin gözlenen değerlerinin normal dağılım gösterdiği durumlarda standart sapma en 'sağlam' merkezden dağılma ölçüsü olarak bilinir.
42 39 Cinsiyet, eğitim düzeyi, doğum yeri, sınıf, şube, okul türü gibi kategorik değişkenlerde yani sınıflama ve sıralama ölçeği düzeyindeki değişkenlerde, ortalama anlamlı olmadığı gibi standart sapma da anlamlı değildir. Verilerin normal dağılımdan sapması ya da uç noktaların etkisinin söz konusu olduğu durumlarda, ortalamada olduğu gibi standart sapma da doğrudan yorumlanabilir değildir. Bu durumlarda standart sapma, yanıltıcı olabilir, eksik ve yanlış betimsel yorumlara yol açabilir. ÖRNEK 1 Bir basketbol takımında oynayan 10 çocuğun ağırlıkları ölçülmüştür: Ağırlık: 45kg; 55kg; 40kg; 62kg; 55kg; 54 kg; 58kg; 48kg; 50kg; 43kg Buna göre bu çocukların ağırlıklarının standart sapmasını hesaplayalım. Standart sapma formülüne dikkat edilirse, standart sapma, ortalamaya bağlı olarak hesaplanan bir istatistiktir. O halde öncelikle ağırlıkların ortalamasının hesaplanması gerekir. Standart sapmanın hesaplanmasında işlem adımları aşağıda verilmiştir: 1. Ortalamanın hesaplanması 2. Her bir gözlem değerinden ortalamanın çıkarılması ve ortalamadan farkların bulunması. 3. Her bir ortalamadan farkın karesinin alınması. 4. Ortalamadan farkların karelerinin toplanması. 5. Elde edilen toplamın N ya da (n-1)'e bölünmesi. 6. Elde edilen sayının karekökünün alınması. Verilen örnekte öncelikle ortalamayı hesaplayalım: Ortalama hesaplandıktan sonra standart sapmayı daha kolay hesaplayabilmek için üç sütunlu bir tablo kullanılabilir:

43 = -6 (-6) 2 = Toplam 442 Ortalamadan farkların kareleri toplamı 442 olarak hesaplandı. Şimdi formülde bu değeri yerine yazarak standart sapmayı belirleyelim: Çocukların ağırlıklarının standart sapması 7,01 olarak hesaplanmıştır. Yukarıda açıklandığı gibi bu değer tek başına fazlaca bir bilgi vermez. Sadece ağırlıkların orta noktaya göre sapma gösterdiği yani çocukların farklı ağırlıklarda olduğu söylenebilir VARYANS Varyans, standart sapmanın karesidir. Standart sapma gibi varyans da verilerin ortalamadan uzaklaşma düzeyleri yani verilerin çeşitliliği hakkında bilgi verir. Evren varyansı ve örneklem varyansı, farklı sembollerle gösterilmenin yanı sıra hesaplama formüller açısından da farklıdır: Evren Varyansı Örneklem Varyansı Standart sapma için yukarıda yapılan açıklama ve uyarılar aynen varyans için de geçerlidir. Yani varyans da sürekli ve normal dağılım gösteren değişkenlerde 'sağlam' bir kestirimdir. Bu varsayımları karşılamayan değişkenlerde varyans, ya anlamsızdır ya da yanıltıcı olabilir.
44 41 Varyansın hesaplanmasında takip edilmesi gereken işlem adımları, standart sapma için verilenlerle aynıdır. Sadece varyansı hesaplarken, standart sapma hesaplamasının son adımı olan karekök alma işlemi yapılmaz. Buna göre varyans kestiriminde takip edilecek işlem adımları şu şekildedir: 1. Ortalamanın hesaplanması 2. Her bir gözlem değerinden ortalamanın çıkarılması ve ortalamadan farkların bulunması. 3. Her bir ortalamadan farkın karesinin alınması. 4. Ortalamadan farkların karelerinin toplanması. 5. Elde edilen toplamın N ya da (n-1)'e bölünmesi. Buna göre Örnek 1'de verilen değerlerin varyansının 49,11 olduğu açıktır. ÖRNEK 2 Bir sınıftaki 20 öğrencinin matematik dersine karşı tutumları bir tutum ölçeği ile ölçülmüştür. Ölçek toplam puanlarının varyansını hesaplanması aşağıdaki üç sütunlu tabloda gösterilmektedir. n ,40 179, ,40 70, ,40 70, ,40 11, ,60 0, ,60 6, ,60 12, ,60 43, ,60 134, ,40 88, ,40 29, ,40 1, ,60 0, ,60 2, ,60 0, ,60 92, ,60 134, ,40 40, ,60 0, ,60 43,56 =26,60 = 964,80 Tabloda görüldüğü gibi toplam tutum puanlarının ortalaması 26,6 ve puanların ortalamadan farklarının kareleri toplamı 964,80 olarak hesaplanmıştır. Buna göre varyans bu değerin 20-1=19'a bölümünden elde edilen değer olacaktır.

45 42 Öğrencilerin derse karşı tutum puanlarının varyansı 50,78 olarak hesaplanmıştır. Yukarıda açıklandığı gibi bu değer tek başına fazlaca bir bilgi vermez. Sadece tutum puanlarının orta noktaya göre sapma gösterdiği yani öğrencilerin farklı tutumlara sahip oldukları söylenebilir RANJ Ranj (range); ölçme sonuçlarını gösteren bir veri setindeki alt ve üst değerlerin yani maksimum ve minimum değerlerin farkıdır. Yani bir değişkene yönelik gözlenen değerlerin aralığıdır. Ranj = Maksimum Gözlenen Değer Minimum Gözlenen Değer Ranj, sürekli yani en az eşit aralıklı ölçek düzeyindeki değişkenlerde anlamlı bir istatistiktir. Kesikli yani sınıflama ve sıralama ölçekleri düzeyindeki değişkenlerde anlamlı değildir. Sıralama ölçeği düzeyindeki değişkenlerde, değişkenin gözlenen değerlerinin alt ve üst sınırlarının farkını ifade eden ranj yerine 'sıra farkları (rank)' kullanılabilmektedir. Ranj, standart sapma ve varyans gibi verilerin çeşitliliği ve yayılması hakkında bilgi veren bir merkezden dağılma ölçüsüdür. Bir değişkenin gözlenen değerlerinin ranjının yanı sıra bu değerlerin alt ya da üst sınırı biliniyorsa diğer uç değer de hesaplanabilir. Örneğin, bir sınıfta öğrencilerin akademik başarı notlarının ranjı 40 ve bu sınıfta en yüksek akademik başarı notu 95 ise en düşük akademik başarı notunun = 55 olduğu belirlenebilir. ÖRNEK 3 a) Örnek 1'de verilen, çocukların ağırlıklarının ranjını hesaplayalım: Maksimum gözlenen ağırlık = 62 Minimum gözlenen ağırlık = 40 Ranj = = 22 b) Örnek 2'de verilen öğrencilerin tutum puanlarının ranjını hesaplayalım: Maksimum tutum puanı = 40 Minimum tutum puanı = 15 Ranj = = 25
 25. yüzdeliğe (Y 25), ikinci çeyreklik (Q 2) 50.")
46 ÇEYREK SAPMA Çeyrek sapma (quartile deviation); birinci çeyreklik ile üçüncü çeyreklik değerlerinin farkının yarısı alınarak hesaplanan bir merkezi dağılım ölçüsüdür. Çeyreklik değerler, sıralanmış verilerin %25'lik bölümlerine karşılık gelen değerlerdir. Yani birinci çeyreklik (Q 1) 25. yüzdeliğe (Y 25), ikinci çeyreklik (Q 2) 50. yüzdeliğe (Y 50), üçüncü çeyreklik (Q 2) 75. yüzdeliğe (Y 75) ve dördüncü çeyreklik (Q 4) maksimum değer olarak 100. yüzdeliğe (Y 100) karşılık gelir. Buna göre çeyrek sapma, 25. ve 75. yüzdeliklerin farkının yarısıdır: Ortalama, standart sapma ve varyansın, özellikle uç noktalardan aşırı etkilendiği yukarıda açıklanmıştı. Çeyrek sapma ilk çeyreklik olan %25'lik düşük ölçme sonuçlarını ve son çeyreklik olan %25'lik yüksek ölçme sonuçlarını dışarıda bırakan bir istatistiktir. BU nedenle çeyrek sapma, uç noktalardan etkilenmez. Bu nedenle uç noktaların etkisinin manidar olduğu veri setlerinde çeyrek sapma daha 'iyi' ve 'yansız' bir kestiricidir. ÖRNEK 4 a) Örnek 1'de verilen çocukların ağırlıklarını sıralayarak bu gözlenen değerlerin çeyrek sapmasını belirleyelim: Sıralı ağırlıklar: 40kg; 43kg; 45kg; 48kg; 50kg; 54kg; 55kg; 55kg; 58kg; 62kg Y 25 Y 75 Çeyrek sapma = (55-45) / 2 = 5 b) Örnek 2'de verilen öğrenci tutum puanlarını sıralayarak, bu puanların çeyrek sapmasını hesaplayalım: Sıralı tutum puanları: 15; 15; 17; 20; 20; 23; 24; 25; 26; 26; 26; 26; 28; 30; 32; 33; 35; 35; 36; 40 Y 25 Y 75 Çeyrek sapma = (33-20) / 2 = 6,5
47 44 BÖLÜM 7 BİLGİSAYAR UYGULAMALARI - 1 Belli bir özelliğe yönelik yapılandırılmış gözlemlerle elde edilen ölçme sonuçları üzerinde bir çok istatistiksel işlem yapılabilmektedir. Bu işlemlerin bir kısmı betimleme amacıyla, bir kısmı ise ortaya atılan ve 'hipotez' olarak adlandırılan iddiaların olasılıklı olarak doğrulanması ya da yanlışlanması amacıyla yapılmaktadır. İlgilenilen özelliğin süreklilik göstermesi durumunda, geliştirilmiş daha karmaşık istatistiksel işlemlerin kullanılabilmesi ve daha 'sağlam' kanıtlar elde edilebilmesi mümkün olabilmektedir. Buradaki temel güçlük sürekli bir özelliğe yönelik gözlemlerin, belli bir sayının üzerinde olması gerekliliğidir. Başarı, zeka, tutum, ilgi gibi bireylerin sürekli özelliklerine yönelik gözlemlerde, özelliğin sürekliliğini karşılayacak sayıda gözlem elde edilmiş olması gerekir. Diğer bir deyişle çok az sayıda gözlem ve ölçme sonucu olması durumunda, sürekli özelliğe yönelik olarak yapılan kestirimler ve çıkarımlar yanıltıcı olabilmektedir. Bu nedenle özellikle sürekli özelliklere yönelik gözlemlerde ve bu özellikle ilişkilendirilen sürekli değişkenlerde, gözlem sayısının yüksek olması beklenir. İstatistiksel işlemlerde 'zengin örneklem sınırı', minimum 20 yada 30 gözlemdir. 20'nin altındaki örneklemlerde ve özellikle ilgilenilen özellik açısından homojen bir dağılımın bulunmadığı örneklemlerde, sürekli değişkenlere yani en az eşit aralıklı ölçek düzeyinde bulunan değişkenlere yönelik istatistiksel kestirim ve çıkarımlar anlamlı değildir ve bunların yanıltıcı olma olasılığı yüksektir. Bu nedenle sürekli bir özelliğe yönelik sürekli değişkenler düzeyinde elde edilen veriler üzerinde ortalama, standart sapma, varyans gibi kestirimler ve bu kestirimlere dayalı hipotez testleri yapılacaksa, örneklemin zengin örneklem sınırının üzerinde bir büyüklükte olmasına dikkat edilmesi gerekir. Aksi durumda, kesikli değişkenlere yönelik istatistiklerin kullanılması doğru olacaktır. İstatistiklerin kestirilmesinde elle hesaplama, zaman alamsının yanı sıra hesaplama hatası yapma olasılığını da artırmaktadır. Veri seti gerek gözlem birimleri gerek değişken sayıları açısından büyüdükçe bu tür olumsuzluklar daha da fazlalaşmaktadır. Zengin örneklemlerden elde edilen veriler üzerinde çalışma, bu tür bir güçlüğü doğal olarak ortaya çıkarmaktadır. Bu nedenle özellikle büyük veri setleri üzerinde istatistiksel kestirimlerin yapılmasında, hesap makinesi ya da bilgisayar kullanılması, önemli bir kolaylık sağlamaktadır. İstatistiksel hesaplamalarda kullanılabilecek özel amaçlı hesap makineleri, günümüzde erişilebilir durumdadır. Bunun yanı sıra bilgisayar ortamında kullanılabilecek paket programlar da bulunmaktadır. Gerek hesap makinelerinin gerek bilgisayar programlarının istatistiksel
48 45 hesaplamalarda kullanılabilmesi, bu araçların tanınması ve kullanabilme yeterliğinin kazanılmasına bağlıdır. Bu bölümde, bir veri seti üzerinde betimsel istatistiklerin kestirilmesinde Microsoft Excell programının kullanımı gösterilmektedir. Excell programı, Microsoft Office paket programının içerisinde yer alan hem kelime işlemci hem sayı işlemci özellikleri bulunan, istatistiksel işlemlerde oldukça kullanışlı bir programdır. matematiksel ve Bu bölümdeki uygulama ve açıklamalar bir örnek üzerinden aşağıda verilmiştir. ÖRNEK Bir sınıftaki 30 öğrencinin öğrenmeye karşı ilgileri, bu amaçla geliştirilmiş bir ölçek kullanılarak ölçülmüştür. Öğrencilerin bu ölçekten aldıkları toplam puanlar aşağıda verilmiştir: Toplam Puanlar: 80; 85; 67; 90; 65; 72; 95; 110; 106; 120; 92; 105; 105; 76; 130; 120; 118; 105; 108; 112; 123; 126; 93; 90; 92; 90; 85; 78; 112; 120 a) Ön Hazırlıklar Öncelikle verileri Excell sayfasında girerek veri setini hazırlayalım. Bilindiği gibi Excell sayfaları bir veri setinin genel yapısına uygun bir şekilde satır ve sütunlardan oluşmaktadır. Satırlar 1, 2, 3... şeklinde doğal sayılarla numaralandırılmıştır. Sütunlar A, B, C,... harfleri ile gösterilmiştir. Satır ve sütunların kesiştiği alanlar 'hücre' olarak isimlendirilir. Örneğin B sütunu ile 7. satırın kesiştiği alan 'B7', C sütunu ile 15. satırın kesiştiği alan 'C15' sembolleri ile gösterilir. Örnekte verilen toplam puanlar, 'öğrenmeye karşı ilgi (Öİ)' değişkeninin gözlenen değerleridir. Veri setinin hazırlanmasında bu verilerin A1 ile A30 hücreleri arasında bir sütun olarak girilmesi gerekir. Excell sayfasında 30 öğrencinin ölçek toplam puanlarını girilmesi ile elde edilen veri seti Şekil 7.1'de gösterilmektedir. b) Verilerin Sıralanması Excell'de bir sütunda yer alan veriler, sayfanın sağ üst köşesinde yer alan 'Düzenleme' bölümündeki 'Sırala ve Filtre Uygula' sekmesindeki komutlarla yapılabilmektedir. Bu örnekte verileri sıralamak için sıralamak istediğimiz A sütunu ya da bu sütundaki 30 sayıyı işaretleyip söz konusu sekmedeki 'Küçükten büyüğe sırala' seçeneğini kullanmamız gerekmektedir. Bu işlemler yapıldıktan sonra elde edilen sıralanmış veriler, Şekil 7.2'de gösterilmektedir.
49 46 Veriler sıralandığında minimum ve maksimum değerler kolaylıkla belirlenebilmektedir. Şekil 2'de görüldüğü gibi verilen örnekte minimum değer 65, maksimum değer 130'dur. Bu durumda ranj hesaplanabilir: Ranj = = 65 c) Ortalamanın Kestirilmesi Excell'de ortalama hesaplamak, özel bir komut sekmesiyle kolaylıkla yapılabilmektedir. Excell sayfasının sağ üst kısmında yer alan 'Düzenleme' grubunda yer alan Σ simgesinin altında 'Ortalama' sekmesi kullanılarak, seçilen sayıların ortalaması belirlenebilmektedir. Ortalama sonucunun yazılacağı hücre, kullanıcı tarafından belirlenmelidir. Verilen örnekte A sütununda yer alan 30 değerin ortalaması, C1 hücresinde hesaplanmıştır. Hesaplamaya ilişkin gösterim Şekil 7.3'te yer almaktadır. Şekil 3'te görüldüğü gibi ortalama, 99 olarak hesaplanmıştır. ç) Medyanın Kestirilmesi Excell'de medyan kestirimleri için kısa yol bulunmamaktadır. Bunun için sayfanın en üst satırındaki 'Formüller' sekmesi seçilir, açılan alt grupta sol tarafta 'f x' ile gösterilen 'İşlev Ekle' seçilir. Bu seçimden sonra 'İşlev Ekle' penceresi açılır. Bu penceredeki 'Kategori seçin' sekmesinde 'İstatistiksel' işaretlenir. Aşağıdaki pencerede alfabetik olarak sıralanan istatistiklerden uygun olan (bu örnekte 'ortanca' seçilecek) seçilir. 'Tamam' denildiğinde hangi verilerin ortancasının alınmak istendiğini soran 'Fonksiyon Bağımsız Değişkenleri' penceresi açılır. Bu pencerede ister elle veri aralığı girilir (bu örnek için A1:A30) ister mause kullanılarak veriler seçilir. 'Tamam' denildiğinde önceden belirlenen hücrede medyan değeri hesaplanıp gösterilir. Verilen örnekte 30 verinin medyanı, C1 hücresinde gösterilecek şekilde hesaplanmıştır. İşlem süreci ve sonucu Şekil 7.4'te gösterilmektedir. Şekil 4'te görüldüğü gibi medyan değeri 100 olarak hesaplanmıştır. d) Çeyrekliklerin Kestirilmesi Excell'de çeyrekliklerin yani 25., 50. ve 75. yüzdeliklerin hesaplanması, 'İşlev Ekle' penceresinde 'İstatistiksel' menüsünde yer alan 'Dörttebirlik' algoritması ile yapılabilmektedir. Söz konusu 'Dörttebirlik' algoritması işaretlenip 'Tamam' denildiğinde açılan pencerenin ilk satırına veri aralığı girilmektedir. 'Dizi 2' olarak belirtilen ikinci satıra ise birinci çeyreklik için 1, ikinci çeyreklik için 2, üçüncü çeyreklik için 3 yazılıp 'Tamam' denir. Böylece önceden belirlenen hücrelerde çeyreklik değerleri hesaplanarak gösterilir.
50 47 Verilen örnekte birinci çeyreklik C1, ikinci çeyreklik C2 ve üçüncü çeyreklik C3 hücresinde hesaplanmıştır. İşlem süreci ve sonuçları Şekil 5'te gösterilmiştir. Şekil 7.5'te görüldüğü gibi 30 veri için çeyreklikle aşağıdaki gibi hesaplanmıştır: Q1 = 86,25 Q2 = 100 Q3 = 112 e) Standart Sapmanın Kestirilmesi Medyan kestiriminde olduğu gibi standart sapmanın kestiriminde de 'İşlev Ekle' penceresinde 'İstatistiksel' gruplaması kullanılır. Excell'de standart sapma ile ilgili olarak söz konusu pencerede dört tane farklı algoritma yer almaktadır. Bu algoritmalar sırasıyla STDSAPMA, STDSAPMAA, STDSAPMAS ve STDSAPMASA ile gösterilmektedir: STDSAPMA: Örneklemden elde edilen sürekli verilerin standart sapmasının kestirilmesinde kullanılır. STDSAPMAA: Örneklemden elde edilen 1-0 verilerinin standart sapmasının kestirilmesinde kullanılır. STDSAPMAS: Evrenden elde edilen sürekli verilerin standart sapmasının kestirilmesinde kullanılır. STDSAPMASA: Evrenden elde edilen 1-0 verilerinin standart sapmasının kestirilmesinde kullanılır. Verilen örnekte, örneklem standart sapması STDSAPMA algoritması kullanılarak, C1 hücresinde hesaplanmış ve gösterilmiştir. İşlem süreci ve sonucu Şekil 7.6'da gösterilmiştir. Şekil 6'da görüldüğü gibi 30 verinin standart sapması 18,26245 olarak hesaplanmıştır. f) Varyansın Kestirilmesi Excell'de varyans kestirimi yine 'İşlev Ekle' penceresinde dört farklı algoritmadan uygun olanı seçilerek yapılabilmektedir. Bu algoritmalar şu şekildedir: VAR: Örneklemden elde edilen sürekli verilerin varyansının kestirilmesinde kullanılır. VARA: Örneklemden elde edilen 1-0 verilerinin varyansının kestirilmesinde kullanılır. VARS: Evrenden elde edilen sürekli verilerin varyansının kestirilmesinde kullanılır. VARSA: Evrenden elde edilen 1-0 verilerinin varyansının kestirilmesinde kullanılır. Verilen örnekte, örneklem varyansı VAR algoritması kullanılarak, C1 hücresinde hesaplanmış ve gösterilmiştir. İşlem süreci ve sonucu Şekil 7.7'de gösterilmiştir. Şekil 7'de görüldüğü gibi 30 verinin varyansı 333,5172 olarak hesaplanmıştır.

51 48 Sütunlar B7 hücresi Satırlar C15 hücresi Şekil 7.1. Veri Setinin Hazırlanması

52 Şekil 7.2. Verilerin Sıralanması 49

53 Şekil 7.3. Ortalamanın Kestirilmesi 50

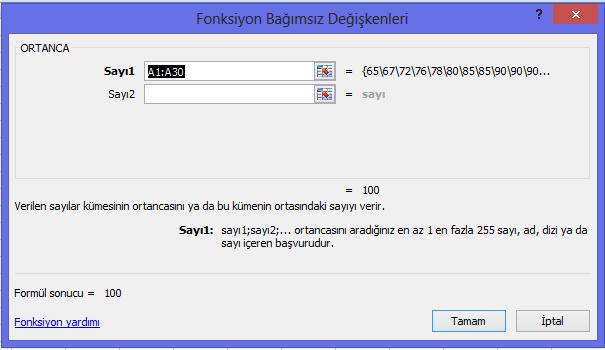
54 Şekil 7.4. Medyanın Kestirilmesi 51

55 Şekil 7.5. Çeyrekliklerin Kestirilmesi 52

56 Şekil 7.6. Standart Sapmanın Kestirilmesi 53

57 Şekil 7.7. Varyansın Kestirilmesi 54
58 55 BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2 Bu bölümde bir veri seti üzerinde betimsel istatistiklerin kestiriminde SPSS paket programının kullanımı açıklanmaktadır. Açıklamalar bir örnek üzerinde hareketle yapılmakta, SPSS uygulamaları örnek üzerinde gösterilmektedir. İstatistiksel hesaplamalarda kullanılabilecek özel amaçlı hesap makineleri, günümüzde erişilebilir durumdadır. Bunun yanı sıra bilgisayar ortamında kullanılabilecek paket programlar da bulunmaktadır. Elbette ki gerek hesap makinelerinin gerek bilgisayar programlarının istatistiksel hesaplamalarda kullanılabilmesi, bu araçların tanınması ve kullanabilme yeterliğinin kazanılmasına bağlıdır. SPSS (Statistical Package for Social Science), sosyal bilimler alanına yönelik veri setleri üzerinde istatistiksel işlemler ve analizlerin yürütülmesinde kullanılan bir paket programdır. IBM şirketi tarafından lisanslanmaktadır. İstatistiksel işlemeler ve analizler için geliştirilmiş bir program olan SPSS'in arayüzü Microsoft Office Excell programına benzemektedir. Farklı olarak SPSS'in işlem menüleri, istatistiksel işlemlere göre düzenlenmiştir. Aşağıda SPSS'in bir veri seti üzerinde betimsel istatistiklerin kestiriminde kullanımı, bir örnek le eş adımlı olarak sunulmaktadır. ÖRNEK Bir sınıftaki 30 öğrencinin öğrenmeye karşı ilgileri, bu amaçla geliştirilmiş bir ölçek kullanılarak ölçülmüştür. Öğrencilerin bu ölçekten aldıkları toplam puanlar ve cinsiyetleri aynı sırada aşağıda verilmiştir: Toplam Puanlar : 80; 85; 67; 90; 65; 72; 95; 110; 106; 120; 92; 105; 105; 76; 130; 120; 118; 105; 108; 112; 123; 126; 93; 90; 92; 90; 85; 78; 112; 120 Cinsiyetler : K; K; K; E; E; K; E; E; K; K; K; E; K; E; E; K; K; E; E; K; E; K; K; K; E; E; K; E; K; K Bilindiği gibi toplam ölçek puanları eşit aralıklı ölçek düzeyinde ve sürekli bir değişken, cinsiyet ise sınıflama ölçeğinde ve kesikli bir değişkendir.
59 56 a) Değişkenlerin Tanımlanması SPSS, iki arayüzlü olarak iki sayfa şeklinde açılır. Bu sayfalardan biri 'Data View', ikincisi 'Variable View' olarak isimlendirilir. Bu arayüzler arasındaki geçişler SPSS sayfasının sağ alt köşesindeki sekmeler aracılığı ile gerçekleştirilir. SPSS ilk açıldığında otomatik olarak 'Variable View' arayüzü kullanıcının karşısına çıkar. Bu sayfada veri setinin sütun başlıkları olan değişken isimleri ve türleri açıklamalı olarak belirlenir. Bu değişken tanımlamaları için yapılan işlemler şu şekildedir: 1. Variable View arayüzü açılır. 2. 'Name' sütununun ilk satırına ölçek puanlarını temsil eden değişken örneğin 'ILGI' olarak, ikinci satırına ise cinsiyet değişkeni örneğin 'CINS' olarak girilir. 3. İkinci sütun olan 'Type' sütunun ilk satırında, ILGI değişkeni için 'Numeric', ikinci satırında ise CINS değişkeni için 'String' türü seçilir. Bu seçim ILGI değişkeninin değerlerinin sayısal, CİNS değişkeninin değerlerinin harflerle girileceğini tanımlamaktadır. 4. Gireceğimiz değerlerin ondalık kısmı olmadığı için 'Decimals' sütununun birinci ve ikinci satırları, otomatik olarak bulunan 2 yerine 0 olarak düzeltilir. 5. İstenirse 'Label' sütununun satırlarına, ilgili değişken hakkında açıklama yazılabilir. Örneğin ILGI kısaltması ile verilen değişken için bu kısma "öğrencileri ilgi ölçeğinden aldıkları toplam puanlar", CINS kısaltması ile verilen değişken için bu hücreye "öğrencilerin cinsiyetleri" yazılabilir. 6. 'Values' sütununda kategorik değişkenlerin kategorileri tanımlanır. Örneğin cinsiyet değişkeni için bu tanımlama, 'Values' sütununun ilgili hücresine tıklanıp açılan pencere de 'Value' satırına K ve 'Label satırına 'Kız' yazılıp 'Add' sekmesi işaretlenerek, sonrasında 'Value' satırına E ve 'Label' satırına 'Erkek' yazılıp 'Add' sekmesi işaretlenerek ve en son OK' sekmesi işaretlenerek yapılabilir. 7. 'Measure' sütununda ölçek türleri seçililir. ILGI eşit aralıklı ölçek düzeyinde olduğu için bu sütunun ilk satırında 'Scale', CINS sınıflama ölçeği düzeyinde olduğu için bu sütunun ikinci satırında 'Nominal' seçilir. Yukarıdaki değişken tanımlama işlemleri yapıldığında 'Data View' arayüzünde bu değişkenlerin sütun başlıkları olarak yer aldığı görülecektir. Söz konusu bu işlemler Şekil 8.1'de gösterilmektedir.
60 57 b) Değişken Değerlerinin Girilmesi 'Variable View' arayüzünde değişkenler tanımlandıktan sonra sağ alttaki sekmelerden 'Data View' arayüzüne geçiş yapılır. Değişkenler tanımlandığı için burada birinci sütun başlığının ILGI, ikinci sütun başlığının CINS olduğu görülecektir. Veriler ilgili sütunların ilk hücresinden başlanarak aşağıya doğru girilir. Veriler girildiğinde elde edilen veri seti Şekil 8.2'de gösterilmektedir. c) Betimsel İstatistiklerin Kestirilmesi SPSS'te istatistiksel kestirimlerin tamamına yakını en üst satırda yer alan 'Analyze' menüsünden yapılmaktadır. Frekans dağılımlarının ve betimsel istatistiklerin kestirilmesinde aşağıdaki aşamalar yolu takip edilir: 1. Analyze Descriptive Statistics Frequencies işlem yolu takip edilerek 'Frequencies' penceresi açılır. 2. Sağ pencerede yer alan değişkenlerden frekans dağılımı belirlenmek ve betimsel istatistikleri kestirilmek istenenler, sağ taraftaki 'Variables' penceresine atılır. Farklı değişkenler için farklı kestirimler elde edilecekse veriler ayrı ayrı girilerek ayrı işlemler yapılabilir. 3. Sağ taraftaki sekmelerden 'Statistics' seçilir. Açılan pencerede hesaplanmak istenen istatistikler seçilir. 'Continue' seçilir. 4. Grafik gösterimi isteniyorsa sağ taraftaki sekmelerden 'Charts...' seçilir. Açılan pencerede tercih edilen uygun grafik türü seçilir. Histogram seçilecekse 'Show normal curve on histogram' seçeneği işaretlenerek histogram üzerinde normal dağılım eğrisinin gösterilmesi de sağlanabilir. 'Continue' seçilir. 5. 'Display frequency tables' seçeneği otomatik işaretli olarak çıkmaktadır. Bu seçenek işaretli olduğunda frekans tabloları otomatik olarak hazırlanır ve çıktı olarak sunulur. 6. Tüm bu düzenlemelerden sonra 'OK' seçilerek analiz başlatılır. Yukarıda verilen işlem adımları ve uygulamalar, verilen örnekteki ILGI değişkeni için Şekil 8.3a, Şekil 8.3b, Şekil 8.3c ve Şekil 8.3d'de sırasıyla gösterilmektedir. ILGI ve CINS değişkenleri farklı türde ve farklı ölçek düzeylerinde değişkenler oldukları için bu değişkenlere yönelik işlem ve kestirimlerin bir arada yapılmaması daha uygundur. Benzer işlem adımlarının CINS değişkeni için de yürütülmesi mümkündür. SPSS, analiz çıktıları ayrı bir sayfada 'Output' dosyası olarak vermektedir. Aşağıdaki tablolarda örnek veri setinde yer alan 'ILGI' değişkenine yönelik analiz çıktıları, 'Output' dosyasından kopyalanarak verilmiştir.
61 58 Yapılan işlemler sonucunda elde edilen ilk çıktı özet istatistiklerin verildiği tablodur: Statistics Öğrencilerin ilgi ölçeğinden aldıkları toplam puanlar N Valid 30 Missing 0 Mean 99,00 Median 100,00 Mode 90 a Std. Deviation 18,262 Variance 333,517 Range 65 Minimum 65 Maximum ,00 Percentiles , ,50 a. Multiple modes exist. The smallest value is shown Tablo başlığı, değişkenlerin tanımlanmasında 'Label' sütununda yapılan açıklamalar olarak verilmektedir. Bu açıklama yapılmamış olsaydı tablo başlığı, değişken adı olarak 'Name' sütuna girilen ILGI olarak atanacaktı. Bu tabloda yukarıdan aşağıya doğru sırasıyla örneklem sayısı, kayıp değer sayısı, ortalama, medyan, mod, standart sapma, varyans, ranj, minimum gözlenen değer, maksimum gözlenen değer ve 25, 50 ve 75. yüzdelikler gösterilmektedir. İkinci çıktı değişken değerlerinin frekans tablosudur: Valid Öğrencilerin ilgi ölçeğinden aldıkları toplam puanlar Frequency Percent Valid Percent Cumulative Percent ,3 3,3 3, ,3 3,3 6, ,3 3,3 10, ,3 3,3 13, ,3 3,3 16, ,3 3,3 20, ,7 6,7 26, ,0 10,0 36, ,7 6,7 43, ,3 3,3 46, ,3 3,3 50, ,0 10,0 60, ,3 3,3 63, ,3 3,3 66, ,3 3,3 70, ,7 6,7 76, ,3 3,3 80, ,0 10,0 90, ,3 3,3 93, ,3 3,3 96, ,3 3,3 100,0 Total ,0 100,0

62 59 Frekans tablosunun ilk sütununda gözlem değerleri yani ölçme sonuçları, ikinci sütununda bu değerlerin frekansları, üçüncü sütununda frekans yüzdeleri, dördüncü sütununda yığmalı frekanslar ve son sütununda yığmalı yüzdeler verilmiştir. Frekans tablosunda görüldüğü gibi en sık tekrar eden yani frekansı en yüksek olan değerler 90, 105 ve 120'dir. Değişken, çok modludur. Bir önceki tabloda mod değeri 90 olarak verilmiştir. Bu değer tablo altında yer alan açıklamaya göre 90, 105 ve 120 değerlerinin en küçüğüdür. Frekans tablosuna göre "verilerin %90'ı 120 ve altındadır", "verilerin %50'si 90 puan ve altındadır" gibi yığmalı betimlemeler de yapılabilir. Üçüncü çıktı, verilerin frekans dağılımlarını gösteren histogramdır: Histogram, SPSS'in otomatik olarak yaptığı şekliyle, veriler gruplanarak verilmiştir. Bu nedenle bu histogram üzerinde tepe noktasını görmek mümkün olmamaktadır. Fakat dağılım genel şekli ile normal dağılımı karşılaştırmak mümkündür. Görüldüğü üzere örnekteki verilerin dağılımı, normal dağılıma göre daha sivri bir dağılımdır.

63 60 Değişkenler Değerlerin ondalık basamak sayısı Değişkenlere yönelik açıklamalar Değişkenlerin kategorileri Değişkenlerin ölçek türü Değerlerin veri setine girilme türü Değişkenlerin tanımlandığı sayfa Şekil 8.1. SPSS'te Değişkenlerin Tanımlanması

64 61 Değişken değerlerinin girildiği arayüz Şekil 8.2. SPSS'te Değişken Değerlerinin Girilmesi

65 Şekil 8.3a. SPSS'te Frekans Tablolarının Hazırlanması ve Betimsel İstatistiklerin Kestirilmesi (Analiz Menüsü) 62


66 Şekil 8.3b. SPSS'te Frekans Tablolarının Hazırlanması ve Betimsel İstatistiklerin Kestirilmesi (İstatistik Penceresi) 63

67 Şekil 8.3c. SPSS'te Frekans Tablolarının Hazırlanması ve Betimsel İstatistiklerin Kestirilmesi (Grafik Penceresi) 64

68 Şekil 8.3d. SPSS'te Frekans Tablolarının Hazırlanması ve Betimsel İstatistiklerin Kestirilmesi (Analiz Çıktıları) 65
69 66 BÖLÜM 9 NORMAL DAĞILIM Normal dağılım; 'normal dağılım eğrisi (normaly distribution curve)' ile kavramlaştırılan hipotetik bir evren dağılımıdır. 'Gauss dağılımı' ya da 'Gauss eğrisi' olarak da bilinen normal dağılım eğrisi, sürekli ve olasılıklı bir fonksiyon eğrisidir. Normal dağılım eğrisinin fonksiyonu aşağıdaki şekildedir: Formülden de anlaşılacağı üzere normal dağılımı tanımlayan parametreler evren ortalaması (µ) ve evren standart sapması (σ)'dır. Normal dağılım eğrisi, bir fonksiyon olarak kartezyen düzlemde aşağıdaki gibi çizilir: Normal dağılım eğrisi, ölçme sonuçlarının orta noktalarda yoğunlaştığı, uç noktalarda seyrekleştiği bir dağılımın şeklini ifade etmektedir. Normal dağılımın karakteristik özellikleri şu şekildedir: 1. Simetriktir. 2. Asimptotiktir. 3. (-, + ) aralığında değerler alır. 4. Eğri altındaki toplam alanın olasılığı 1'dir. [ P (- < X < + ) = 1 ] 5. Ortalama, mod ve medyan değerleri çakışıktır. [ µ = Medyan = Mod ]
70 ÇARPIK VE BASIK DAĞILIMLAR Aşağıda normal dağılımdan farklılaşan dağılımlar, dağılımın şekilleri ile gösterilmiştir. Şekil 9.1. Sağa Çarpık Dağılım Şekil 9.2. Sola Çarpık Dağılım Şekil 9.3. Sivri Dağılım Şekil 9.4. Basık Dağılım 9.2. DAĞILIM NORMALLİĞİNİN İNCELENMESİ a) Verilerin normal dağılım gösterip göstermediğini belirlemenin yollarından biri dağılımın grafiğini çizmek ve bu grafiği yorumlamaktır. b) Verilerin dağılımının normal dağılım gösterip göstermediğini belirlemenin bir diğer yolu ortalama, mod ve medyan değerlerine bakmaktır. Normal dağılımda bu değerler çakışıktır. Bu istatistikler birbirine yaklaştığı ölçüde dağılım normal dağılıma yaklaşır. Birbirinden uzaklaştığı ölçüde dağılım çarpıklaşır. Fakat bu yakınlığın düzeyi ile ilgili belirli bir standart yoktur. Bu nedenle burada verilen diğer yöntemlerle birlikte değerlendirilmesi önerilir. c) Normal dağılımı test etmenin bir diğer yolu da basıklık ve çarpıklık katsayılarına bakmaktır. Çarpıklık (skewness) katsayısı normal dağılımda 0'dır. Negatif çarpıklık katsayısı sola çarpık dağılıma, pozitif çarpıklık katsayısı sağa çarpık dağılıma işaret eder. Basıklık (kurtosis) katsayısı da normal dağılımda 0'dır. Pozitif basıklık katsayısı sivri dağılıma, negatif basıklık katsayısı ise basık bir dağılıma işaret eder. Dağılımın normal dağılımdan manidar düzeyde farklılaşmıyor olması için bu değerlerin (- 1, +1) aralığında kalması beklenir. ÖRNEK 1 Bir sınıftaki 25 öğrencinin yazılı sınav notları aşağıda verilmektedir. Buna göre yazılı sınav notlarının normal dağılım gösterip göstermediğini belirlemeye çalışalım. NOT: 55; 60; 65; 75; 90; 95; 90; 80; 75; 75; 70; 65; 60; 50; 45; 40; 70; 65; 70; 70; 60; 70; 80; 75; 70

 Örnekteki veriler için çarpıklık katsayısı -0,508 ve basıklık katsayısı 0,186'dır.")
71 68 a) Verilen notların dağılımını betimleyen histogram aşağıdaki gibidir. Şekil 9.1. Öğrencilerin Yazılı Sınav Notlarının Dağılımı Histogramda görüldüğü gibi verilerin dağılımı normal dağılıma göre daha sivridir. b) Örnekteki veriler için ortalama 68,2, medyan ve mod 70 olarak hesaplanır. Bu değerler birbirine oldukça yakındır. Buna göre dağılımın yatay eksende normal olduğu yani sağa ya da sola çarpık olmadığı söylenebilir. c) Örnekteki veriler için çarpıklık katsayısı -0,508 ve basıklık katsayısı 0,186'dır. Buna göre dağılım hafifçe sağa çarpı ve sivridir. Fakat bu sapmalar (-1, +1) aralığında kaldığı için dağılımın normal olduğu söylenebilir NORMAL DAĞILIM EĞRİSİ ALTINDAKİ ALANLAR VE OLASILIK Normal dağılım eğrisi iyi tanımlı bir eğridir. Bu nedenle standart sapma aralıklarına göre eğri altında kalan alanlar hesaplanabilmektedir: Yukarıdaki şekilde görüldüğü gibi ortalamanın 1 standart sapma sağında ve solunda kalan alanlar eğri altındaki toplam alanın %34,1'ini oluşturmaktadır. -1 ve +1 standart sapma arasında kalan alan toplam alanın %68,2'sidir. Ortalamanın 2 standart sapma sağı ile 2 standart sapma solu yani -2 standart sapma ile +2 standart sapma arasında kalan alan, eğri altında kalan toplam alanın yaklaşık %95'ini oluşturmaktadır. -3 ve +3 standart sapma aralığı ise eğri altındaki toplam alanın yaklaşık %99'unu oluşturmaktadır.

72 69 Normal dağılım eğrisinin iyi tanımlı olması, normal dağılım gösteren ölçme sonuçlarının belli aralıklarda görülme olasılığının belirlenebilmesini sağlamaktadır. Diğer bir deyişle bir değişkenin gözlenen değerleri normal dağılım gösteriyorsa, herhangi bir gözlem değerinin ya da belli bir aralıktaki gözlem değerlerinin görülme olasılığı belirlenebilir. Normal dağılımın davranış bilimleri, eğitim bilimleri, psikoloji gibi odağında insan ve birey bulunan alanlarda önemli bir karşılığı vardır. Birey özelliklerinin önemli bir kısmı evrende normal dağılım göstermektedir. Örneğin zeka, evrende normal dağılım gösteren bir birey özelliğidir. Yani orta düzeyde zekaya sahip olan bireyler çoğunluğu, yüksek düzeyde zekaya ya da düşük düzeyde zekaya sahip olan bireyler azınlığı oluşturur. Başarı, ilgi, tutum, kişilik gibi özelliklerin önemli bir kısmı için de benzer durum söz konusudur. İlgilenilen özelliğin normal dağılım göstermesi, bu özelliğe yönelik ölçme sonuçlarının görülme olasılığı hakkında önemli çıkarımlar ve kestirimler yapılabilmesini de olanaklı hale getirmektedir. ÖRNEK 2 Bir sınıfta yazılı yoklama notlarının ortalaması µ=60 ve standart sapması σ=5 olarak hesaplanmıştır. Yazılı notları normal dağılım göstermektedir. Bu durumda notların dağılımı aşağıdaki gibi olacaktır: Buna göre aşağıdaki soruları yanıtlayalım.
73 70 a) Bu sınıfta bir öğrencinin 50'nin altında not alma olasılığı kaçtır? Bu sorunun yanıtı, eğride 50 değerinde yer alan dikey çizginin solunda kalan alandır. Bu alan 0,0227'dir. Buna göre bu sınıfta bir öğrencinin 0'nin altında not almış olma olasılığı %2,27'dir. b) Bu sınıfta bir öğrencinin 55 ile 65 arasında not alma olasılığı kaçtır? Bu sorunun yanıtı, eğride 55 ve 65 değerlerinde yer alan dikey çizgiler ile eğri arasında kalan toplam alandır. Bu alan 0,6826'dır. Buna göre bu sınıfta bir öğrencinin 55 ile 65 arasında not almış olma olasılığı %68,26'dır. c) Bu sınıfta bir öğrencinin 55'in üzerinde not almış olma olasılığı kaçtır? Bu sorunun yanıtı, 55 değerindeki dikey çizginin solunda eğrinin altında kalan toplam alandır. Bu alan 0, ,50 = 0,8413'tür. Buna göre bu sınıfta bir öğrencinin 55'in üzerinde not almış olma olasılığı %84,13'tür. d) Bu sınıfta bir öğrencinin 65 ile 75 arasında not almış olma olasılığı kaştır? Bu sorunun yanıtı, 65 ve 75 değerlerindeki dikey çizgiler ile eğri arasında kalan toplam alandır. Bu alan 0, ,0214 = 0,1573'tür. Buna göre bu sınıfta bir öğrencinin 65 ile 75 arasında not almış olma olasılığı %15,73'tür.
74 71 BÖLÜM 10 PUAN DÖNÜŞÜMLERİ Bir gözlem sonucunda elde edilen ve üzerinde herhangi bir düzenleme yapılmamış ölçme sonuçları 'ham veri' ya da 'ham puan' olarak isimlendirilir. Genellikle ham verilerin anlaşılması ve yorumlanması güçtür. Bu nedenle bu ölçme sonuçları üzerinde bazı düzeltme ve dönüşümler uygulanarak anlaşılması ve yorumlanması daha kolay bir şekle dönüştürülebilir. 'Puan dönüşümleri' bu tür düzenlemelerden biridir. Puan dönüşümü; ham verilerin, karakteristiği bilinene tipik puanlara dönüştürülmesi işlemidir. Bazı puan dönüşümleri aşağıda örneklerle açıklanmaktadır. Aşağıda sunulanların yanı sıra başkaca puan dönüşümleri de bulunmaktadır. Gözlenen verinin karakteristiğine ve yapılacak istatistiksel işlemlere kullanılabilecek 'uygun' puan dönüşümleri vardır. Bu nedenle puan dönüşümlerinin kullanılabilmesi, gözlenen verilerin karakteristiğinin ve yapılacak istatistiksel işlemlerin bilinmesinin yanı sıra puan dönüşümlerinin karakteristiklerinin ve kullanım alanlarının da bilinmesi önemlidir YÜZDE PUANLAR Yüzde puan dönüşümü yaygın olarak kullanılan bir dönüşümdür. En basit puan dönüşümlerinden biridir. Elde etmek için, en az eşit aralık ölçeğindeki verilerin yüzde puanlarını elde etmek için bu veriler %'ye çevrilir. Yüzde puanlar, 100 üzerinden düzenlenmiş puanlardır. Üst sınır bellidir. Bu nedenle ham puanlardan daha kolay anlaşılır ve yorumlanır olduğu söylenebilir. ÖRNEK 1 Bir sınıfta öğrencilerin öğrenme başarısı çoktan seçmeli maddelerden oluşa bir testle ölçülmüştür. Testte 20 madde yer almaktadır. Çoktan seçmeli maddeler 1-0 şeklinde iki kategorili puanlandığı için bu testten alınabilecek puanlar 0 ile 20 arasında değişmektedir. Bu sınıftaki 8 öğrencinin bu testten aldıkları puanlar aşağıda verilmiştir: TEST HAM PUANLARI: 12; 15; 10; 13; 18; 8; 14; 17

75 72 Özellikle testten alınabilecek puanların üst sınırı bilinmediği durumlarda bu puanların anlaşılması ve yorumlanması güçtür. BU durumda yüzde puan dönüşümü kullanmak anlama ve yorumlama kolaylığı sağlayacaktır. Basit bir orantı kurma işlemi ile yukarıdaki test ham puanlarını yüzde puanlara dönüştürebiliriz. Her bir değeri 100 ile çarpıp 20'ye böldüğümüzde ya da kısaca 5 ile çarptığımızda yüzde puanlar elde edilmiş olur: YÜZDE PUANLAR: 60; 75; 50; 65; 90; 40; 70; 85 Bu puanların yüzde puanlar olduğu bilindiğinde, 100 üzerinden düzenlenmiş puanlar oldukları da anlaşılır. Bu durumda puanları anlamak ve yorumlamak daha kolay bir hale gelir. Örneğin ham puanın 15 olması, üst sınır da bilinmediğinden çok bir anlam içermez. Fakat buna karşılık gelen yüzde puanın 75 olduğunun bilinmesi, test ile yoklanan davranışların en azından yarısından fazlasına sahip olunduğu bilgisini verir STANDART Z PUANLARI Standart Z puanları ya da kısaca Z puanları; ortalaması 0, standart sapması 1 olan ve evrende normal dağılım gösteren 'iyi' tanımlı tipik puanlardır. Z puan dönüşümü ise ham verilerin Z puanlarına dönüştürülmesinde kullanılan doğrusal bir puan dönüşümüdür. Bir grup verinin ya da puanın ortalaması ve standart sapması bilindiğinde bu puanların her bir ayrı ayrı Z puanına dönüştürülebilir. Z puanları dönüşümünde aşağıdaki formül kullanılır: Bilinmesi gereken önemli bir husus Z puan dönüşümü ile elde edilen puanların, ortalaması 0 ve standart sapması 1 olan puanlar olduğudur. Bu bilgi, dönüşümün doğru bir şekilde yapılıp yapılmadığını kontrol etmede kullanılabilir. Diğer taraftan bu durum pozitif Z değerlerinin yanı sıra negatif Z değerlerinin de elde edilebileceğini göstermektedir. Z puanlarının, yüzde puanlarına göre daha az anlaşılır ve yorumlanabilir olduğu söylenebilir. Z puanlarının anlaşılması ve yorumlanması öncelikle bu puanların karakteristiğinin bilinmesine bağlıdır. Diğer taraftan Z puanları, evrende normal dağılım gösteren bir olasılık dağılımına sahiptir. Bu nedenle evrende süreklilik gösteren ve normal dağılıma sahip özelliklere yönelik gözlemlerde, ölçme sonuçlarının Z puanlarına dönüştürülmesi, istatistiksel işlemlerde hareket alanını genişletmekte, daha sağlam ve fazla bilgi elde edilmesine yardımcı olmaktadır.
76 73 ÖRNEK 2 Bir sınıfta öğretmen, öğrencilerin sözlü anlatım becerilerin ölçmek amacıyla sözlü yoklama uygulamıştır. Öğretmen sözlü yoklamada her bir öğrenciye iki soru sormuş ve bu soruları dereceli puanlama anahtarına göre 50şer not üzerinden puanlayarak toplamda 100 not üzerinden puanlama yapmıştır. Sözlü yoklama notlarının ortalaması µ=75 ve standart sapması σ=10 olarak hesaplanmıştır. Sınıftaki 5 öğrencinin sözlü yoklama notları aşağıda gösterilmektedir: SÖZLÜ YOKLAMA NOTLARI: 80; 70; 85; 75; 60 Buna göre her bir puanın Z puanı karşılığını bulalım. Z 80 = (80-75) / 10 = 5 / 10 = 0,5 Z 75 = (75-75) / 10 = 0 / 10 = 0 Z 70 = (70-75) / 10 = -5 / 10 = -0,5 Z 60 = (60-75) / 10 = -15 / 10 = -1,5 Z 85 = (85-75) / 10 = 10 / 10 = 1 Buna göre elde edilen Z puanları aşağıda verilmiştir: Z PUANLARI: 0,5; -0,5; 1; 0; -1, STANDART T PUANLARI Standart T puanları ya da kısaca T puanları; ortalaması 50, standart sapması 10 olan ve normal dağılım gösteren 'iyi' tanımlı tipik puanlardır. T puan dönüşümü ise ham verilerin T puanlarına dönüştürülmesinde kullanılan doğrusal bir puan dönüşümüdür. Bir grup verinin ya da puanın ortalaması ve standart sapması bilindiğinde bu puanların her bir ayrı ayrı T puanına dönüştürülebilir. T puanları dönüşümünde aşağıdaki formül kullanılır: Formülde görüldüğü gibi T puanları, Z puanlarından farklı olarak örneklem ortalaması ve örneklem standart sapması ile tanımlanmaktadır. Bunun nedenlerinden biri T puanlarının, genellikle küçük örneklemlere yönelik istatistiksel işlem ve analizlerde kullanılmasıdır. Formül incelendiğinde Z puanları ile T puanları arasında doğrusal bir ilişki olduğu görülmektedir. T puan dönüşümü formülünde yer alan her bir değerin ortalamadan farkının alınıp standart sapmaya
77 74 bölünmesi, Z puan dönüşümü formülü ile örtüşmektedir. Buna göre T puanları, Z puanlarının 10 katının 50 fazlasıdır. Yani T puanları, Z puanları kullanılarak da elde edilebilmektedir. T = 10. Z + 50 Z puanlarının negatif değerler alabiliyor olması, bir güçlük olarak yukarıda açıklanmıştı. T puanları, Z puanlarında yaşanan bu güçlüğü gidermektedir. Z puanlarında olduğu gibi T puanlarının da anlaşılması ve yorumlanması zordur. Fakat 'iyi' tanımlı ve tipik puanlar olmaları, uygun durumlarda daha ileri düzey istatistiksel kestirimlerde kullanılabilmesini sağlamaktadır. Bu da ilgilenilen özelliğin anlaşılması, açıklanması ve kontrol edilmesinde önemli bir hareket alanı sağlamaktadır. ÖRNEK 3 Ortalaması µ=65 ve standart sapması σ=12 olarak hesaplanan bir yazılı yoklamada 6 öğrencinin notları aşağıda verilmiştir. NOTLAR: 70; 75; 65; 62; 60; 53 Bu notları T puanlarına dönüştürelim. Öncelikle, her bir nottan ortalamayı çıkarıp standart sapmaya bölerek Z puanlarını bulalım. Z 70 = (70-65) / 12 = 5 / 12 0,42 Z 75 = (75-65) / 12 = 10 / 12 0,83 Z 65 = (65-65) / 12 = 0 / 12 = 0 Z 62 = (62-65) / 12 = -3 / 12 = -0,25 Z 60 = (60-65) / 12 = -5 / 12-0,42 Buna göre elde edilen Z puanları aşağıda verilmiştir: Z PUANLARI: 0,42; 0,83; 0; -0,25; -0,42; -1 Z 53 = (53-65) / 12 = -12 / 12 = -1 Şimdi her bir Z puanını 10 ile çarpıp çarpma sonucunu 50 ile toplayarak T puanlarını bulalım: T 70 = (0,42 x 10) + 50 = 4, = 54,2 T 75 = (0,83 x 10) + 50 = 8, = 58,3 T 65 = (0 x 10) + 50 = = 50 T 62 = (-0,25 x 10) + 50 = -2, = 47,5 T 60 = (-0,42 x 10) + 50 = -4, = 45,8 Buna göre elde edilen T puanları aşağıda verilmiştir: T PUANLARI: 54,2; 58,3; 50; 47,5; 45,8; 40 T 53 = (-1 x 10) + 50 = = 40

78 75 BÖLÜM 11 Z DAĞILIMI Z dağılımı; ortalaması µ=0 ve standart sapması σ=1 olan Z puanlarının evren dağılımı olarak tanımlanabilmektedir. Z dağılımı olasılıklı bir normal dağılımdır. Yani Z dağılımının genel karakteristiği normal dağılımla aynıdır. Bu nedenle Z dağılımı 'standart normal dağılım' olarak da isimlendirilmektedir. Şekil Z Dağılımı Standart Z dağılımı olarak da bilinen Z dağılımının özellikleri şu şekildedir: 1. Simetriktir. 2. Asimptotiktir. 3. (-, + ) aralığında değerler alır. 4. Eğri altındaki toplam alanın olasılığı 1'dir. [ P (- < X < + ) = 1 ] 5. Ortalama, mod ve medyan değerleri çakışıktır. [ µ = Medyan = Mod ] 6. Olasılık yoğunluk fonksiyonu vardır. Z dağılım eğrisinin olasılık yoğunluk fonksiyonu, normal dağılım eğrisinin olasılık yoğunluk fonksiyonu kullanılarak elde edilebilmektedir. Normal dağılım eğrisinin olasılık yoğunluk fonksiyonu aşağıdaki gibidir: Bu fonksiyonda µ yerine 0, σ yerine 1 yazıldığında Z dağılım eğrisinin fonksiyonu aşağıdaki şekilde elde edilir: Normal dağılım, ortalama ve standart sapma değerlerine göre tanımlı bir evren dağılımıdır. Bu nedenle ortalama ve standart sapmaya göre sonsuz sayıda evren dağılımı belirlemek mümkündür. Z dağılımı ise standart bir dağılım olup ortalama ve standart sapma değerleri sabitlenmiştir. Bu durum Z dağılımının olasılıklı kestirimlerde kullanılmasını kolaylaştırmaktadır.
79 76 Z dağılımının bir diğer avantajı, tam sayı olarak verilen standart sapma aralıklarının yanı sıra bu tam sayılar arasındaki aralıklar için de hesaplama yapılabilmesi kolaylığıdır. Örneğin ortalaması 50, standart sapması 10 olarak belirlenen bir normal dağılım eğrisinde, 50 ile 60 arası, 70'in üzeri, 40'ın altı gibi tam sayı standart sapma aralıklarında değer alma olasılığı kolaylıkla belirlenebilir. Fakat örneğin 55 ile 75 arası, 45 üzeri, 75 aşağısı gibi tam sayı olmayan standart sapma aralıklarının olasılığının hesaplanması zordur. Bu hesaplamalar için, normal dağılımın olasılık yoğunluk fonksiyonu kullanılarak bir integral işlemi yapılması gerekmektedir. Z dağılımının eğrisi standart ve 'iyi' tanımlı olduğu için standart sapma açısından tam sayı aralıklarının yanı sıra tam sayı olmayan aralıkların da olasılığı daha kolay belirlenebilmektedir. Dahası bu hesaplamalar yapılarak hazırlanmış 'Standart Z Değerleri' tabloları da bulunmaktadır. Hesaplama şeklini bilmeyenler, bu tablolardan yararlanarak Z dağılımı üzerinde belli aralıkların olasılıklarını hesaplayabilir. Bu amaçla hazırlanmış bir Z değerleri tablosu, Tablo 11.1 olarak sonda verilmiştir. Tablo 11.1'de verilen Z değerleri tablosu, pozitif bir Z değeri ile 0 arasında kalan eğri altındaki alanın olasılığını göstermektedir. Olasılık değerleri 0 ile 1 arasında değişir. Bu nedenle tablodaki değerler ondalıklı sayı olarak gösterilmektedir. Tablodaki ilk sütun ve ilk satırda yer alan değerler istenen Z değerinin belirlenmesi için kullanılır. İstenen Z değerinin birler ve onda birler basamakları ilk sütundan, yüzde birler basamağı ise ilk satırdan belirlenir. Bu değerlerin kesiştiği hücredeki değer, bu Z değeri ile 0 arasındaki alanın olasılık değeridir. Bir Z dağılımı üzerinde belli aralıklarda eğri altında kalan alanın yani belli değerlerin görülme olasılığının belirlenmesinde temelde üç işlem yapılmaktadır: 1. İstenen alanı belirleme ve dağılım üzerinde gösterme 2. Z puanlarına dönüştürme 3. Z değerleri tablosunu okuyarak istenen alanı belirleme ÖRNEK Bir okulda öğrencilerin zeka düzeyleri bu amaçla geliştirilmiş bir zeka testi kullanılarak ölçülmüştür. Ölçeme sonuçlarına göre her bir öğrenciye bir zeka puanı verilmiştir. Zeka puanlarının ortalaması µ=100 ve standart sapması σ=15 olarak hesaplanmıştır. Ayrıca zeka puanlarının normal dağılım gösterdiği belirlenmiştir. Bu bilgilere göre aşağıdaki soruları yanıtlayınız. a) Zeka puanlarının dağılımını gösteriniz. Zeka puanları normal dağılım gösterdiği, ortalaması ve standart sapması bilindiğine göre bu puanların dağılımının şekli aşağıdaki gibi olacaktır.

80 77 b) Bu okuldaki bir öğrencinin zeka puanının 100'ün üzerinde olma olasılığı nedir? Yukarıdaki eğride, aynı zamanda simetri ekseni olan 100 değerindeki dikey çizginin sağ tarafı ile eğri altında kalan toplam alan sorulmaktadır. Bu alan %50'lik bir kısım oluşturmaktadır. O halde bu okuldaki bir öğrencinin zeka puanının 100'ün üzerinde olma olasılığı 0,5'tir. c) Bu okuldaki bir öğrencinin zeka puanının 70'in altında olma olasılığı nedir? Yukarıdaki eğride 70 değerindeki dikey çizginin sol tarafı ile eğri altında kalan alan sorulmaktadır. BU alanın yüzde değeri 2,14 + 0,13 = 2,27'dir. Yani %2,27'dir. O halde bu okuldaki bir öğrencinin zeka puanının 70'in altında olma olasılığı 0,0227'dir. d) Bu okuldaki bir öğrencinin zeka puanının 80'in üzerinde olma olasılığı nedir? Bu soruda 80 değerinden çizilecek olan dikey doğrunun sol tarafında eğri altında kalan toplam alanın olasılığı sorulmaktadır. Dikkat edilirse 80 değeri, tam sayı olarak belirlenen standart sapma aralıklarına denk gelmemektedir. Yani ortalama ile -1 standart sapma arasındadır. Bu durumda istenen olasılığı hesaplamak daha güçtür. İstenen alanı hesaplamak için Z dağılımından yararlanalım. Öncelikle istenen alanı belirleyelim. İkinci olarak istenen alanı belirlemekte kullanılacak olan 80 değerini Z puanına dönüştürelim. Dikkat edilirse 100 değeri ortalama olduğu için bu değerin Z puanı karşılığı 0 olacaktır. Z 80 = (80-100) / 15 = -20 / 15 = -1,33 Üçüncü olarak -1,33 ile 0 arasındaki alanın olasılığını belirleyelim. Bunun için Tablo 11.1'de verilen Z değerlerinden yararlanalım. Dikkat edilirse Tablo 11.1'deki Z değerleri, orta nokta ile pozitif bir Z değeri arasındaki alanı vermektedir. Fakat Z eğrisi simetrik olduğu için negatif değerlere yönelik
81 78 alanlar, bu değerlerin pozitifleri için olan alanlarla örtüşür. Yani -1,33 ile 0 arasında kalan alan +1,33 ile 0 arasında kalan alana eşit olacaktır. O halde tabloda satırda 1,3 ve sütunda 0,03 değerlerinin kesiştiği hücreye bakılır. Bu hücredeki değer 0,4082'dir. 0'ın sağındaki alan da bilindiği üzere 0,50'dir. Buna göre toplam alanın olasılığı bu değerlerin toplamıyla yaklaşık 0,41 elde edilir. 0,41 0,50 e) Bu okuldaki bir öğrencinin zeka puanının 80 ile 110 arasında olma olasılığı nedir? Öncelikle istenen alanı belirleyelim. İkinci olarak 80 ve 110 puanlar için Z puanlarını belirleyelim. Z 80 = (80-100) / 15 = -20 / 15 = -1,33 Z 110 = ( ) / 15 = 10 / 15 = 0,67 Üçüncü olarak Z tablosundan bu Z değerlerine karşılık gelen değerleri okuyalım: Z=-1,33 için sütunda 1,3 ve satırda 0,03'ün kesiştiği hücredeki değer; 0,4082 Z=0,67 için sütunda 0,6 ve sütunda 0,07'nin kesiştiği hücredeki değer; 0,2486 Son olarak bu değerleri şekil üzerinde gösterelim; 0,41 0,25 O halde toplam alanın olasılığı 0,41 + 0,25 = 0,66 olarak elde edilir. Yani 80 ile 110 arasında puan alma olasılığı 0,66'dır.

82 Tablo Standart Z Değerleri 79
83 80 BÖLÜM 12 STUDENT T DAĞILIMI 'Student t dağılımı' ya da kısaca 't dağılımı'; normal dağılım ve Z dağılımının da içerisinde bulunduğu 'sürekli olasılık dağılımları' ailesinde yer alan dağılımlardan bir diğeridir. T dağılımı, William Sealy Gosset'in 1908 yılında Biometrika dergisinde 'Student' takma adıyla yayımladığı makalesinde tanımladığı bir hipotetik dağılımdır. T dağılımı, pratikte, Z puanları üzerinde bir düzeltme ile elde edilen t puanlarının dağılımıdır. Bilindiği gibi Z puanları, evren ortalaması ve evren standart sapmasına göre tanımlanmaktadır: Yine bilindiği gibi evren ve örneklem standart sapması farklı formüllerle ve farklı şekillerde hesaplanmaktadır. Bu farklılık, gözlem sayıları ile ilişkilidir. Gözlem sayısı arttıkça yani örneklem büyüklüğü evrene yaklaştıkça, örneklem değerleri yani istatistikler, evren değerlere yani parametrelere yaklaşmaktadır. Diğer bir deyişle küçük örneklemlerde yapılan kestirimlerin evren değerlerden yani parametrelerden farklılaşma olasılığı daha yüksektir. Bu nedenle örneklem üzerinde ve özellikle küçük örneklemler üzerinde yapılan kestirimlerde, daha 'sağlam' kestirimler elde edilmesi için istatistiksel düzeltmeler yapılır. Örneklem standart sapmasının hesaplanmasında (n-1)'e bölme bu tür bir düzeltmedir. İşte Gosset, Z dağılımının temelde bir evren dağılımı olduğu, bu dağılımın küçük örneklemlerde kullanılabilmesi için bir düzeltme yapılması gerektiği fikrinden hareketle 'Student t Dağılımı' olarak bilinen dağılımı geliştirmiştir. Bu düzeltmeyi, Z dağılımının olasılık yoğunluk fonksiyonundan hareketle geliştirdiği t dağılımına özgü bir olasılık yoğunluk fonksiyonu tanımlayarak göstermiştir. Buna göre t dağılımının olasılık yoğunluk fonksiyonu aşağıdaki gibidir: Bu formüldeki V sembolü serbestlik derecesini, gama ( ) sembolü ise serbestlik derecesine bağlı özel bir gama fonksiyonunu göstermektedir. Formüle dikkat edilirse t dağılımını belirleyen temel istatistiği serbestlik derecesi olduğu görülmektedir. Bu noktada 'küçük örneklem' ile ne kastedildiğinin açıklanması gerekmektedir. Önceki bölümlerde açıklandığı gibi sürekli özelliklere ve sürekli değişkenlere yönelik 'zengin örneklem' sınır 20 ya da
84 81 30'dur. Yani 20'den az verinin bulunduğu gözlemler, sürekli bir özelliğin açıklanması ya da sürekli bir değişkene yönelik ortalama, standart sapma gibi istatistiklerin hesaplanmasında yeterli değildir. Student T dağılımı ile belirlenen çerçevede 'küçük örneklem (small sample)', 120 ve altında gözlem birimi içeren örneklemdir. 120'nin üzerinde gözlem birimi bulunan örneklemler 'büyük örneklem (large sample)' olarak isimlendirilmektedir. O halde T dağılımı, küçük örneklemlerde yani 120'nin altında veri elde edildiği durumlarda Z dağılımına göre daha titiz ve 'sağlam' kestirimler veren Z dağılımından geliştirilmiş özel bir dağılımdır. T dağılımının şekli, normal dağılım eğrisinin şekli ile benzerdir. Normal dağılım eğrisinden farklı olarak t dağılımın şeklini belirleyen; evren ortalaması ve serbestlik derecesidir. 'V' ya da 'sd' sembolleriyle gösterilen serbestlik derecesi, tek örneklemlerde örneklem büyüklüğünün 1 eksiği yani (n-1), iki örneklem söz konusu olduğunda örneklem büyüklüklerinin toplamının 2 eksiği yani (n 1+n 2-1)'dir. Örneklem sayısı arttıkça serbestlik derecesi benzer şekilde hesaplanır. Serbestlik derecesi arttıkça, t dağılımı, daha sivri bir eğri gösterir. Şekil Serbestlik Derecesine Göre Student T Dağılımları T dağılımı ve t değerleri, pratikte, küçük örneklemlerde ve evren varyansının bilinmediği durumlarda, ortalamalar arası farkların test edilmesine yönelik hipotez testlerinde, karar kuralının belirlenmesi ve kararın verilmesi aşamalarında dikkate alınan kritik değerlerin belirlenmesinde kullanılır. Gosset'in Z dağılımı üzerinde yaptığı düzeltme, evren varyansının bilinmediği durumlarda da hipotetik dağılımın oluşturulmasını ve olasılık kestirimlerinin yapılmasını mümkün kılmaktadır. Evren varyansının bilinmediği durumlarda örneklem varyansı, örneklem büyüklüğü ne bağlı olarak evren varyansı yerine kullanılabilmektedir. Gosset bu yaklaşımıyla aslında evren varyansı ve örneklem varyansı arasındaki ilişkiyi tanımlamıştır. Buna göre evren varyansı ile örneklem varyansı arasında aşağıdaki gibi bir ilişki vardır:
85 82 Bu değer Z puanı formülünde yerine yazıldığında örneklem ortalaması ile evren ortalamasını karşılaştırmak için kullanılan t istatistiği aşağıdaki gibi elde edilmektedir: Yukarıda verilen açıklamalar doğrultusunda student t dağılımının iki özel durumda, ortalamaların karşılaştırılması gibi istatistiksel işlemlerde kullanıldığı söylenebilir: 1. Küçük örneklemlere yönelik kestirimler yapıldığında. 2. Evren varyansının bilinmediği durumlarda. Örneğin örneklemden elde edilen ortalama ile evren ortalamasının örtüşme olasılığı, 't testi' olarak bilinen ve student t dağılımına dayalı istatistiksel test ile kestirilebilmektedir. Bir başka örnek olarak 120'den az gözlem birimi söz konusu olduğunda, örneğin 60 öğrencinin not ortalamaları öğrencilerin cinsiyetlerine göre karşılaştırılmak ve manidar bir fark bulunup bulunmadığı test edilmek istendiğinde yine 't testi' kullanılabilmektedir. Verilen örneklerde olduğu gibi ortalamaların karşılaştırılmasında 't testi' kullanılması durumunda, kritik t değerlerinin belirlenmesi gerekmektedir. Kritik t değerleri, Z değerleri tablosu gibi bu amaçla hazırlanmış bir 't değerleri tablosu' kullanılarak belirlenebilmektedir. 'T değerleri tablosu' sonda Tablo 12.1 olarak verilmiştir. Tablo 12.1'deki değerleri okuyabilmek ve kullanabilmek için bazı bilgilerin verilmesi gerekir. Öncelikle kritik değerin, Z tablosunda olduğu gibi eğri altında kalan alanın olasılık değeri olmadığı bilinmelidir. T kritik değeri, yatay eksendeki bir noktadır. Tabloda ilgili t kritik değerini belirlemek için ilk sütunda serbestlik derecesi seçilir. Dikkat edilirse serbestlik dereceleri 120'ye kadar aralıklı olarak verilmektedir. 120'den sonra tabloda yer alan kritik değerler sabitlenmektedir. Bu durum, t dağılımın küçük örneklemlere yönelik bir dağılım olduğunu ve küçük örneklemin 120 ve altındaki gözlem birimlerinden oluşan örneklem olduğunu desteklemektedir. Büyük örneklemlerde t değerleri, Z değerleri ile örtüşmektedir. Tablonun ilk satırında ise hipotez testinde kurulan hipotezin tek yönlü ya da çift yönlü olmasına ve hipotezde dikkate alınan olasılık yüzdesi ya da manidarlık düzeyine göre ilgili hücre seçilir. Satır ve sütunda seçilen hücrelerin kesiştiği hücredeki değer, hipotez testinde dikkate alınacak kritik t değerini verir. Buna göre kritik t değerinin belirlenmesinde takip edilecek işlem adımları aşağıda verilmiştir: 1. Örneklem büyüklüğüne ve sayısına bağlı olarak serbestlik derecesinin belirlenmesi. 2. Hipotezin tekyönlü ya da çift yönlü kurulduğunun belirlenmesi.

86 83 3. Manidarlık düzeyi ya da olasılık düzeyinin belirlenmesi 4. Kritik t değerleri tablosunda ilgili satır ve sütunun belirlenmesi 5. Kritik t değerleri tablosunda ilgili satır ve sütunun kesiştiği hücredeki değerin kritik t değeri olarak belirlenmesi. Yukarıda açıklandığı gibi t dağılımı, daha ileri düzey istatistiksel işlemlerde ve özellikle çıkarımsal istatistik ile ilgili konularda ele alınacak ve kullanılacaktır. Bununla birlikte bu bölümdeki açıklamalar kapsamında t dağılımının kritik noktaların belirlenmesinde kullanımı aşağıda iki örnek üzerinde gösterilmiştir. ÖRNEK 1 Bir okuldaki 9. sınıf öğrencilerinin akademik başarı notlarının ortalaması µ=70 olarak hesaplanmıştır ve akademik başarı notları normal dağılım göstermektedir. Bu okulun 9A şubesindeki 25 öğrencinin akademik başarı notlarının ortalaması =75 ve standart sapması σ=4 olarak hesaplanmıştır. Bu sınıftaki öğrencilerin notları da normal dağılım göstermektedir. Okul genel ortalaması ile sınıf ortalaması arasında manidar bir fark olup olmadığı, bir istatistiksel hipotez testi ile test edilmek istenmektedir. a) Hipotez aşağıdaki gibi kurulursa, kritik t değerini belirleyelim. H 0: Okul ortalaması ile sınıf ortalaması arasında 0,05 düzeyinde (yada %95 olasılıkla) manidar bir fark yoktur. Hipoteze dikkat edilirse, manidarlık düzeyi %95'tir ve çift yönlü bir hipotezdir. Ayrıca serbestlik derecesi, tek bir örneklem olduğu için sınıf büyüklüğünün 1 eksiği yani 25-1=24 olarak belirlenir. Buna göre kritik t değerleri tablosunda satırda 24 ve sütunda 'çift yönlü' satırının %95 değerinin bulunduğu 7. sütunun kesişimine bakılır. Kesişimde yer alan kritik t değeri 2,064'tür. O halde bu hipotez testinde dikkate alınacak t kritik değeri 2,064 olarak belirlenir. 0,95 0,025 0,025
87 84 b) Hipotez aşağıdaki gibi kurulursa, kritik t değerini belirleyelim. H 0: Okul ortalaması ile sınıf ortalaması arasında 0,10 düzeyinde (yada %90 olasılıkla), sınıf ortalaması lehine manidar bir fark yoktur. Bu hipotez 'sınıf ortalaması okul ortalamasından yüksek değildir' şeklindeki önermeyi test etmeye yöneliktir. Hipoteze dikkat edilirse, manidarlık düzeyi %90'dır ve tek yönlü bir hipotezdir. Ayrıca serbestlik derecesi, tek bir örneklem olduğu için sınıf büyüklüğünün 1 eksiği yani 25-1=24 olarak belirlenir. Buna göre kritik t değerleri tablosunda satırda 24 ve sütunda 'tek yönlü' satırının %90 değerinin bulunduğu 5. sütunun kesişimine bakılır. Kesişimde yer alan kritik t değeri 1,318'dir. O halde bu hipotez testinde dikkate alınacak t kritik değeri 1,318 olarak belirlenir. 0,90 0,10 ÖRNEK 2 Bir sınıftaki kız ve erkek öğrencilerin yazılı notlarının ortalamaları arasındaki farkın manidar olup olmadığı test edilmek istenmektedir. Bu sınıfta 15 kız öğrenci, 18 erkek öğrenci bulunmaktadır. a) Hipotez aşağıdaki gibi kurulursa, kritik t değerini belirleyelim. H 0: Kız öğrencilerin ortalaması ile erkek öğrencilerin ortalaması arasında 0,01 düzeyinde (ya da %99 olasılıkla) manidar bir fark yoktur. Hipoteze dikkat edilirse, manidarlık düzeyi %99'dur ve çift yönlü bir hipotezdir. Ayrıca serbestlik derecesi, iki ayrı örneklem olduğu için =31 olarak belirlenir. Buna göre kritik t değerleri tablosunda satırda 31 (31 olmadığı için en yakın 30) ve sütunda 'çift yönlü' satırının %99 değerinin bulunduğu 9. sütunun kesişimine bakılır. Kesişimde yer alan kritik t değeri 2,750'dir. O halde bu hipotez testinde dikkate alınacak t kritik değeri 2,750 olarak belirlenir.
88 85 0,99 0,005 0,005 b) Hipotez aşağıdaki gibi kurulursa, kritik t değerini belirleyelim. H 0: Kız öğrencilerin ortalaması ile erkek öğrencilerin ortalaması arasında 0,01 düzeyinde (ya da %99 olasılıkla), kızlar lehine manidar bir fark yoktur. Bu hipotez 'kız öğrencilerin ortalaması,erkek öğrencilerin ortalamasından yüksek değildir' şeklinde ifade edilebilecek önermeyi test etmektedir. Hipoteze dikkat edilirse, manidarlık düzeyi %99'dur ve tek yönlü bir hipotezdir. Ayrıca serbestlik derecesi, iki ayrı örneklem olduğu için =31 olarak belirlenir. Buna göre kritik t değerleri tablosunda satırda 31 (31 olmadığı için en yakın 30) ve sütunda 'tek yönlü' satırının %99 değerinin bulunduğu 8. sütunun kesişimine bakılır. Kesişimde yer alan kritik t değeri 2,457'dir. O halde bu hipotez testinde dikkate alınacak t kritik değeri 2,457 olarak belirlenir. 0,99 0,01
89 86 Tablo Tek Yönlü ve Çift Yönlü Dağılımlara Yönelik T Kritik Değerleri Tek Yönlü 75% 80% 85% 90% 95% 97.5% 99% 99.5% 99.75% 99.9% 99.95% Çift Yönlü 50% 60% 70% 80% 90% 95% 98% 99% 99.5% 99.8% 99.9%
90 87 BÖLÜM 13 HİPOTEZ TESTİ Bilimsel yöntem aşamalarıyla tanımlanmış sistematik bir bilgi üretme biçimidir. Bilimsel yöntemin aşamaları aşağıdaki gibi sıralanabilmektedir (Karasar, 2012): 1. Bir problemin ya da güçlük durumunun sezilmesi 2. Problemin tanımlanması 3. Olası çözüm önerilerinin geliştirilmesi 4. Çözümlerin test edilmesi 5. Uygun çözümler üretene kadar döngüsel olarak yeni çözümlerin geliştirilmesi ve test edilmesi 6. Raporlaştırma Bilimsel yöntemin üçüncü aşaması olarak verilen olası çözüm önerileri, pratikte hipotez ve araştırma soruları ile ifade edilir. Dolayısıyla hipotez; basitçe bir iddia, bir savdır. Çözüm olarak ortaya atılan bu iddia, doğrulanmaya ya da doğrulamanın daha kolay bir yolu olarak yanlışlanmaya çalışılır. Bir hipotez kurup bu hipotezi doğrulama ya da yanlışlama ve sonunda bir karara varma işlemlerinin bütününe hipotez testi denir. Bilgi üretiminde yani araştırmalarda benimsenen yaklaşıma, bu yaklaşıma göre belirlenen araştırma tür ve modeline göre hipotezlerin kurulması ve test edilmesinde kullanılan yöntem farklılaşabilmektedir. Nitel araştırmalarda hipotez kurma yerine araştırma sorularıyla ifade etme daha yaygın bir yaklaşımdır. Nicel araştırmalarda betimleme ve açımlama düzeyindeki araştırmalarda da benzer kullanım daha fazla tercih edilebilmektedir. Tarama modeli, deneysel modeller ve genelleme araştırmalarında ise hipotez testleri, araştırmanın önemli bir bölümüdür. Bu araştırma modelleri, genellikli birçok hipotez testi içermektedir. 'Manidarlık testleri' olarak da ifade edilebilen temel betimleme işlemlerinin ötesinde çıkarımsal istatistik yöntem ve tekniklerinin kullanılması durumunda, hipotez testi aşamaları aşağıdaki gibi sıralanabilmektedir: 1. Varsayımların sağlanması 2. Hipotezlerin Kurulması 3. Test istatistiğinin Kestirilmesi 4. Karar Kuralının Belirlenmesi 5. Karar ve Yorum

91 VARSAYIMLARIN SAĞLANMASI Hipotez testlerinin bazı temel varsayımları bulunmaktadır. Bu varsayımların sağlanması ya da sağlanmaması durumlarına göre test süreci ve bu süreçte kullanılacak test istatistikleri farklılaşmaktadır Dağılımın Belirlenmesi İstatistiksel testlerde veri dağılımı, kullanılacak test istatistiğinin belirlenmesinde önemli bir ölçüttür. Verilerin normal dağılım göstermesi durumunda 'parametrik yöntemler', aksi durumda 'parametrik olmayan yöntemler' kullanılır. Parametrik yöntemler, genellikle ortalama ve varyansa dayalı algoritmalar içermektedir. Parametrik olmayan yöntemler ise genellikle sıra ve sıra farklarına dayalı algoritmalarla hesaplamalar içermektedir Ölçek Türü Bilindiği gibi ölçek türleri dörde ayrılmaktadır. 1. Sınıflama Ölçeği 2. Sıralama Ölçeği 3. Eşit Aralıklı Ölçek 4. Eşit Oranlı Ölçek Non-parametrik yöntemler Parametrik yöntemler Sınıflama ölçeği ve sıralama ölçeği düzeyindeki veriler, sınıf ve sıra bilgisi dışında bilgi sağlamamaktadır. Bu ölçek düzeylerinde frekans, yüzde, mod ve bazı durumlarda medyan, bilgi sağlayan istatistiklerdir. Bu ölçek düzeylerinde dört işlem anlamlı değildir. Dolayısıyla bu ölçek düzeylerinde çoğunlukla sıra farklarına dayalı hesaplamalar içeren 'parametrik olmayan yöntemler' kullanılmalıdır.
92 89 Eşit aralıklı ölçek ve eşit oranlı ölçek düzeyindeki verilerde ise toplama ve çıkarma anlamlıdır. Dolayısıyla bu tür verilerde ortalama, varyans, standart sapma gibi betimsel istatistiklerle bilgi sağlamak mümkündür. Dolayısıyla çoğunlukla ortalama ve varyansa dayalı hesaplamalar içeren 'parametrik yöntemler' kullanılabilirdir Örneklem Büyüklüğü Önceki bölümlerde açıklandığı gibi örneklem büyüklüğü, ilgilenilen özellik hakkında anlamlı betimleme ve çıkarımlar yapılabilmesinde önemlidir. Örnekleme kuramına göre örneklem büyüklüğü için üç kesme noktasına bağlı olarak üç tanımlama yapılabilmektedir: 1. Zengin Örneklem: Gözlem birimi sayısı 30'un (bazı kaynaklarda 20'nin) üzerinde olan örneklemleri ifade ederi. 2. Küçük Örneklem: Gözlem birimi sayısı 120 ve altında olan örneklemleri ifade eder. 3. Büyük Örneklem: Gözlem birimi sayısı 120'nin üzerinde olan örneklemleri ifade eder. Örneklem büyüklüğüne bağlı olarak elde edilen veri sayısının 20'nin altında olması durumunda parametrik olmayan yöntemlerin kullanılması önerilir. 20 ile 30 arası veri olması durumunda t testi gibi küçük örneklere yönelik testlerin kullanılabilmesi mümkündür. Genel olarak küçük örneklemlerde t testi gibi özel olarak geliştirilmiş testlerin kullanılması önerilir. Büyük örneklerde ise parametrik testlerin yöntemlerin tamamı, diğer varsayımların da karşılanması koşuluyla kullanılabilirdir Değişken Türü Değişkenin nitel ya da nicel olmasına, sürekli ya da kesikli olmasına, bağımlı-bağımsız değişken ilişkisinin kurulmuş ya da kurulmamış olmasına göre kullanılacak istatistiksel yöntemler de değişmektedir. Bu noktada bir genelleme yapmak çok doğru görülmemektedir. Fakat değişken türlerine göre farklı hesaplama biçimleri, algoritma ve formüller içeren bir çok yöntem bulunmaktadır. Uygun olan yöntemi kullanabilmek için ilgilenilen değişken ya da değişkenlerin doğası hakkında bilgi sahibi olunmasının yanı sıra istatistiksel yöntemler hakkında da bilgi ve yeterlik sahibi olunması gerekmektedir. Örneğin Z testi, sürekli verilere yönelik bir testtir. Aynı zamanda Z testi uygulamalarında, cinsiyet gibi bir nitel değişkenin kategorilerine göre elde edilen sürekli verilerin ortalamaları da karşılaştırılabilmektedir Örneklem Sayısı Veriler tek bir örneklemden elde edilebildiği gibi birden fazla örneklemden de elde edilebilmektedir. Buna göre örneklem sayısına bağlı olarak hipotez testlerini de sınıflamak mümkündür: 1. Tek örnekleme dayalı hipotez testleri 2. İkili örneklemli hipotez testleri 3. İkiden çok örneklemli hipotez testleri
93 90 Örneğin parametrik testlerden Z ve t testleri, parametrik olmayan testlerden Χ 2 testi hem tek örnekleme dayalı hem iki örneklemli testlerde kullanılabilmektedir. İkiden çok örneklem olduğunda parametrik testlerden F testi, parametrik olmayan testlerden Χ 2 testi ve H testi kullanılabilmektedir. Değişkenler arasında bağımlı değişken - bağımsız değişken ilişkisi bulunduğu durumlarda da 'bağımlı örneklem' ve 'bağımsız örneklem' sınıflaması yapılabilmektedir. Bağımlı ve bağımsız değişkenlerin sayısına göre tek örneklemli, ikili örneklemli ya da çok örneklemli hipotez testleri kullanılabilmektedir. Deneysel model araştırmalarda da örneklem ya da çalışma grupları sınıflandırılabilmektedir. 'Deney grubu' ve 'kontrol grubu' bu tür araştırmalardaki temel sınıflamadır. Bu tür bir sınıflamada kullanılacak hipotez testleri, en az iki örneklemli olmaktadır HİPOTEZLERİN KURULMASI Hipotez kurma; birbirinin tümleyeni olan iki önermenin belirlenmesini ifade etmektedir. Yani hipotez testlerinde hipotezler, iki önermeyle ifade edilmektedir. Bunlardan ilki 'sıfır hipotezi', 'yokluk hipotezi' ya da 'null hipotezi' olarak adlandırılan ve 'H 0' ile gösterilen önermedir. H 0, manidar bir fark olmadığı iddiasıdır. İkincisi önerme ise 'alternatif hipotez' olarak isimlendirilen ve 'H 1' ile gösterilen ifadedir. H 1 manidar bir fark olduğu iddiasıdır. Hipotezlerde H 1 önermesinde hipotezin yönü belirlenir. Buna göre hipotezler (i) tek yönlü hipotez ve (ii) çift yönlü hipotez olmak üzere iki farklı şekilde kurulabilmektedir. Çift yönlü hipotezler, gözlenen özellik ya da özellikler açısından gözlem birimleri arasında manidar bir farkın varlığını ve yokluğunu test etmeye yönelik olarak kurulan hipotezlerdir. Tek yönlü hipotezler ise gözlenen özellik ya da özellikler açısından gözlem birimleri arasında manidar bir farkın yokluğunun yanı sıra varlığı durumunda hangi birim ya da birimler lehine bir fark olduğunun test edilmesine yönelik olarak kurulan hipotezlerdir. Hipotez kurmada, hipotez testi için öngörülen manidarlık düzeyinin de belirtilmesi gerekir. Manidarlık düzeyi, olasılıklı olarak hipotezin test edileceği 'güven aralığını' tanımlar ve 'α' sembolü ile gösterilir. Sosyal bilimlerde ve eğitim bilimlerinde manidarlık düzeyi, sıklıkla α=0,05 yada α=0,01 olarak alınmaktadır. BU manidarlık düzeyleri sırasıyla %95 ve %99'luk güven aralıkları yüzdelerini ifade etmektedir. Yukarıdaki açıklamalar doğrultusunda kurulan bazı hipotezler aşağıda örnek olarak verilmektedir: Çift yönlü hipotez H 0: Okul ortalaması ile sınıf ortalaması arasında α=0,05 düzeyinde manidar bir fark yoktur. H 1: Okul ortalaması ile sınıf ortalaması arasında α=0,05 düzeyinde manidar bir fark vardır.
94 91 Tek yönlü hipotez H 0: Okul ortalaması ile sınıf ortalaması arasında α=0,05 düzeyinde manidar bir fark yoktur. H 1: Okul ortalaması ile sınıf ortalaması arasında α=0,05 düzeyinde, sınıf ortalaması lehine manidar bir fark yoktur. Ya da; H 1: Sınıf ortalaması okul ortalamasından α=0,05 düzeyinde manidar bir şekilde fazladır. Çift yönlü hipotez H 0: Öğrencilerin tutum puanları arasında cinsiyetlerine göre α=0,01 düzeyinde manidar bir fark yoktur. H 1: Öğrencilerin tutum puanları arasında cinsiyetlerine göre α=0,01 düzeyinde manidar bir fark vardır. Tek yönlü hipotez H 0: Öğrencilerin tutum puanları arasında cinsiyetlerine göre α=0,01 düzeyinde manidar bir fark yoktur. H 1: Öğrencilerin tutum puanları arasında cinsiyetlerine göre α=0,01 düzeyinde, kız öğrenciler lehine manidar bir fark vardır. Ya da; H 1: Kız öğrencilerin tutum puanları erkek öğrencilerin tutum puanlarından α=0,01 düzeyinde daha yüksektir. Çift yönlü hipotez H 0: Öğrencilerin öğrenmeye karşı ilgileri arasında şubelere göre α=0,05 düzeyinde manidar bir fark yoktur. H 1: öğrencilerin öğrenmeye karşı ilgilerinde en az iki şube arasında α=0,05 düzeyinde manidar bir fark vardır TEST İSTATİSTİĞİNİ KESTİRLMESİ Kullanılacak parametrik ya da parametrik olmayan teste göre kestirilecek test istatistiği değişmektedir. Bazı örnek test istatistikleri aşağıdaki tabloda gösterilmektedir.

95 92 Tablo Örnek Test İstatistikleri Test İstatistiği Açıklama Zengin ve tek örneklemlerde örneklem ortalaması ile evren ortalamasının karşılaştırılmasında kullanılan Z testi istatistiği. Zengin ve ikili örneklemlerde örneklem ortalamalarının karşılaştırılmasında kullanılan Z testi istatistiği. Zengin ve tek örneklemlerde örneklem oranı ile evren oranının karşılaştırılmasında kullanılan Z testi istatistiği. Zengin ve ikili örneklemlerde örneklem oranlarının karşılaştırılmasında kullanılan Z testi istatistiği. Küçük ve ikili örneklemlerde, örneklem varyanslarının homojen olması durumunda örneklem ortalamalarının karşılaştırılmasında kullanılan t testi istatistiği. Küçük ve ikili örneklemlerde, örneklem varyanslarının homojen olmaması durumunda örneklem ortalamalarının karşılaştırılmasında kullanılan t testi istatistiği KARAR KURALI ve KARAR Karar kuralı, kestirilen test istatistiğin değerlendirilmesinde kullanılacak kritik noktaların ve bu noktalar göre verilecek kararların, manidarlık düzeyine ve hipotezin yönüne göre belirlenmesini ifade etmektedir. Karar kuralının belirlenmesi için temel üç işlem yapılır: 1. Belirlenen manidarlık düzeyi ve hipotezin yönüne göre hipotetik dağılım eğrisi üzerinde güven aralığının ve 'kabul - ret' bölgelerinin belirlenmesi. 2. Güven aralığını gösteren kritik değerlerin, kullanılan teste göre belirlenmesi. 3. Güven aralığına göre karar kuralının yazılması. Karar kuralı belirlendikten sonra, bir önceki aşamada kestirilen test istatistiğine göre uygun olan karar verilir ve bu karar kısaca yorumlanır. ÖRNEK 1 Normal dağılım altında α=0,05 manidarlık düzeyinde çift yönlü olarak kurulan bir hipotez için karar kuralını belirleyelim:

96 93 a) Kabul ve Ret Bölgelerinin Belirlenmesi Manidarlık düzeyi α=0,05 olduğuna göre normal dağılım eğrisi altında kabul bölgesi %95, red bölgesi %5 olarak belirlenir. Çift yönlü hipotez olduğu için ret bölgeleri, eğrinin sağ ve sol uçlarında %2,5'luk alanlar olarak yer alır. 0,9 0,02 KABUL 0,02 b) Kritik Değerlerin Belirlenmesi RET Kritik değerler, örneğin normal dağılım altındaki testlerden Z testi kullanılacaksa Z tablosundan, student t testi kullanılacaksa t tablosundan belirlenebilir. Z testi için bu kritik değerler -,196 ve +1,96 olarak belirlenir. Bu durumda güven aralığı (-1,96; +1,96) olarak belirlenir. t testi için bu kritik değerler serbestlik derecesine göre değişir. Örneğin serbestlik derecesi 30 olduğunda bu t kritik değerleri -2,042 ve +2,042 olarak belirlenebilmektedir. Bu durumda güven aralığı (-2,042, +2,042) olarak belirlenir. Örneğin Z testi için verilen kritik değerler dikkate alındığında, aşağıdaki şekil elde edilir. 0,9 0,02 KABUL 0,02 RET c) Karar Kuralının Yazılması Z istatistiği için karar kuralı üçüncü aşamada hesaplanan test istatistiğine göre aşağıdaki gibi yazılır:
97 94 Hesaplanan test istatistiği +1,96'dan büyük ya da -1,96'dan küçükse H 0 hipotezi reddedilemeyecek. Hesaplanan test istatistiği -1,96 ile +1,96 arasında ise H 0 hipotezi reddedilecek ve H 1 hipotezi kabul edilecek. Test istatistiğinin yanı sıra p olasılık değeri de hesaplanmışsa bu olasılık değerine göre karar kuralı aşağıdaki gibi yazılır: Hesaplanan p olasılık değeri 0,05'ten küçükse H 0 hipotezi reddedilecek ve H 1 hipotezi kabul edilecek. Hesaplanan p olasılık değeri 0,05'ten büyükse H 0 hipotezi reddedilemeyecek. ÖRNEK 2 Normal dağılım altında Z testi kullanılarak α=0,01 manidarlık düzeyinde, tek yönlü bir hipotezin test edilmesi durumunda karar kuralını belirleyelim. Örnek 1'de verilen ilk iki adım yapıldığında karar kuralına yönelik aşağıdaki şekil elde edilir. 0,99 KABUL 0,01 RET Buna gör Z karar kuralı aşağıdaki gibi yazılır: Hesaplanan test istatistiği 2,33'ten büyükse H 0 hipotezi reddedilemeyecek. Hesaplanan test istatistiği 2,33'ten küçükse H 0 hipotezi reddedilecek ve H 1 hipotezi kabul edilecek. Test istatistiğinin yanı sıra p olasılık değeri de hesaplanmışsa bu olasılık değerine göre karar kuralı aşağıdaki gibi yazılır: Hesaplanan p olasılık değeri 0,01'den büyükse H 0 hipotezi reddedilemeyecek. Hesaplanan p olasılık değeri 0,01'den küçükse H 0 hipotezi reddedilecek ve H 1 hipotezi kabul edilecek.
98 95 BÖLÜM 14 BİLGİSAYAR UYGULAMALARI - 3 (ORTALAMALARIN KARŞILAŞTIRILMASI) Hipotez testi konusunda görüldüğü üzere temel betimleme, sayma ve sınıflama işlemlerine dayalı yöntemlerin ötesinde normal dağılım ya da başkaca bir hipotetik dağılım altında yapılan hipotez testleri, karmaşık işlem süreçleri içermektedir. Veri seti büyüdükçe bu tür işlemlerin yapılması da güçleşmektedir. Bu durumda hesap makinesi, bilgisayar gibi araçların kullanılması büyük bir kolaylık sağlamaktadır. Bu bölümde ortalamaların karşılaştırılmasına yönelik hipotez testlerinden normal dağılım altında uygulanabilen Z testi ve t testi kullanımı, örnekler üzerinde açıklanmaktadır. Test istatistiklerine yönelik p olasılık değerlerinin hesaplanmasında Microsoft Office EXCELL programı kullanılmakta ve bu programın kullanımı açıklanmaktadır. Excell'de Z testi, sadece tek yönlü hipotezler için ve tek örneklem üzerinde uygulanabilmektedir. T testi ise tek yönlü ve çift yönlü hipotezler için, tek örneklem ve ikili örneklemler için, varyansların homojen olması ve olmaması durumları için kullanılabilmektedir. Her iki kullanımda da Excell, test istatistiğini olasılık değeri olarak hesaplamaktadır. ÖRNEK 1 Bir okulda 9 sınıfların A şubesindeki 30 öğrencinin belli bir dersteki yazılı yoklama notları aşağıda verilmektedir: NOTLAR: 45; 50; 55; 60; 65; 70; 65; 73; 74; 62; 55; 68; 65; 75; 70; 83; 91; 85; 80; 56; 73; 65; 68; 72; 48; 52; 63; 65; 78; 70 Yazılı yoklamanın aynı öğretmen tarafından ve aynı şekilde 9. sınıf düzeyindeki 5 farklı şubede uygulandığını düşünelim. Yazılı yoklamayı alan tüm öğrencilerin notlarının ortalaması µ=65 ve standart sapması σ=9,43 olsun. Şube ortalamasının tüm şubeleri içeren sınıflar ortalamasından manidar şekilde yüksek olup olmadığını hipotez testi aşamalarını takip ederek test edelim. Kullanılacak test istatistiğinin Z testi olduğu açıktır. 1) Varsayımların Sağlanması Dağılım: Yazılı yoklama öğrenci başarısını ölçmektedir. Öğrenme başarısı evrende normal dağıldığı varsayılan bir özelliktir.
99 96 Ölçek Türü: Yazılı sınav notları eşit aralıklı ölçek düzeyindedir. Örneklem Büyüklüğü: Örneklem büyüklüğü 30'dur ve zengin örneklem sınırındadır. Küçük örneklemdir. Değişken Türü: Yazılı sınav notları, nicel ve sürekli bir değişkendir. Örneklem Sayısı: Tek bir grup öğrenci üzerindeki gözlem sonuçları söz konusudur. Tek örneklemdir. 2) Hipotezlerin Kurulması Tek yönlü hipotez kurulması gerekir. Manidarlık düzeyini α=0,05 alarak hipotezleri aşağıdaki gibi kurabiliriz: H 0: Şube ortalaması ile genel ortalama arasında α=0,05 düzeyinde manidar bir fark yoktur. H 1: Şube ortalaması ile genel ortalama arasında, şube ortalaması lehine α=0,05 düzeyinde manidar bir fark vardır. 3) Test İstatistiğinin Hesaplanması Evren ortalaması ile örneklem ortalaması karşılaştırılacağı ve varsayımlar sağlandığı için tek örneklemlere yönelik Z testi kullanılması mümkündür. Excell'de test istatistiğini hesaplamak için aşağıdaki işlem adımları takip edilir: 1. Veriler Excell sayfasında istenen bir sütuna yukarıdan aşağıya doğru girilir. 2. Hesaplanan değerin gösterileceği hücre keyfi olarak belirlenir. 3. Formüller İşlev Ekle (f x) İstatistiksel ZTEST yolu takip edilerek tanımlama penceresi açılır. 4. Pencerede 'Array' satırına veriler işaretlenerek girilir. 'X' satırına evren ortalaması, 'Sigma' satırına evren standart sapması girilir. 5. 'Tamam' tuşuna basıldığında önceden belirlenen hücrede, hesaplanan p olasılık değeri otomatik olarak gösterilir. Bu örnek için yukarıda açıklanan işlem adımları ve hesaplanan p olasılık değeri Şekil 1'de gösterilmektedir. Şekil 14.1'de görüldüğü gibi test istatistiğine yönelik p olasılık değeri, 0, olarak hesaplanmıştır.


100 Şekil Excell'de Z Testi Uygulaması 97
101 98 4) Karar Kuralı Hipotez testi konusunda açıklandığı şekliyle karar kuralı, manidarlık düzeyi ve hipotezlerin yönüne göre belirlenen kritik değerlere ve güven aralığına bağlı olarak yazılmaktadır. Buna göre karar kuralı, p olasılık değerine göre aşağıdaki gibi yazılır: Hesaplanan p olasılık değeri 0,05'ten büyükse H 0 hipotezi reddedilemeyecek. Hesaplanan p olasılık değeri 0,05'ten küçükse H 0 hipotezi reddedilecek ve H 1 hipotezi kabul edilecek. 5) Karar Hesaplanan olasılık değeri manidarlık düzeyinden küçüktür (p=0,1617 < 0,05). Bu durumda H 0 hipotezi reddedilir ve H 1 hipotezi kabul edilir. 9 A şubesindeki öğrencilerin yazılı sınav notlarının ortalaması 9. sınıflar genel ortalamasından manidar düzeyde daha yüksektir. ÖRNEK 2 Örnek 1'de örneklem ortalaması ile evren ortalaması karşılaştırılmıştır. İki grup ya da iki örneklemin ortalamalarının karşılaştırılması da bir başka hipotez testidir. Örnek 1'de verilen yazılı yoklama notlarının yanı sıra öğrencilerin cinsiyetlerini de tanımayalım ve cinsiyetlerine göre öğrencilerin ortalamaları arasında manidar bir fark olup olmadığını test edelim. Buna göre bir sınıftaki öğrencilerin yazılı yoklama notları ve cinsiyetleri Tablo 14.1'de gösterilmiştir.
102 99 Tablo 14.1 Not Cinsiyet 45 K 50 E 55 K 60 K 65 E 70 E 65 K 73 K 74 K 62 K 55 E 68 E 65 K 75 E 70 K 83 K 91 K 85 E 80 E 56 K 73 K 65 E 68 K 72 E 48 K 52 K 63 K 65 E 78 E 70 K Hipotez testi aşamalarını takip edelim: 1) Varsayımların Sağlanması Dağılım: Yazılı yoklama öğrenci başarısını ölçmektedir. Öğrenme başarısı evrende normal dağıldığı varsayılan bir özelliktir. Ölçek Türü: Yazılı sınav notları eşit aralıklı ölçek düzeyindedir. Örneklem Büyüklüğü: Örneklem büyüklüğü 30'dur ve zengin örneklem sınırındadır. Küçük örneklemdir. Değişken Türü: Yazılı sınav notları, nicel ve sürekli bir değişkendir. Örneklem Sayısı: Cinsiyetlerine göre ayılan iki grup öğrenci üzerindeki gözlem sonuçları söz konusudur. İkili örneklemdir ve bu örneklemler birbirinden bağımsızdır.
103 100 2) Hipotezlerin Kurulması Çift yönlü hipotez kuralım. Manidarlık düzeyini α=0,05 alarak hipotezleri aşağıdaki gibi kurabiliriz: H 0: Öğrencilerin yazılı yoklama notları arasında cinsiyetlerine göre α=0,05 düzeyinde manidar bir fark yoktur. H 1: Öğrencilerin yazılı yoklama notları arasında cinsiyetlerine göre α=0,05 düzeyinde manidar bir fark vardır. 3) Test İstatistiğinin Hesaplanması İki ortalama karşılaştırılacağı ve varsayımlar sağlandığı için bağımsız ikili örneklemlere yönelik t testinin kullanılması mümkündür. Excell'de test istatistiğini hesaplamak için aşağıdaki işlem adımları takip edilir: 1. Veriler Excell sayfasına cinsiyete göre ayrı ayrı iki sütun şeklinde girilir. Kız öğrencilerin notları bir sütunda, erkek öğrencilerin notları diğer bir sütunda olmalıdır. Bunun için Excell'deki sıralama butonlarından faydalanılabilir. 2. Hesaplanan değerin gösterileceği hücre keyfi olarak belirlenir. 3. Formüller İşlev Ekle (f x) İstatistiksel TTEST yolu takip edilerek tanımlama penceresi açılır. 4. 'Dizi1' satırına birinci sütun yani kız öğrencilerin notları, 'Dizi2' satırına ikinci sütun yani erkek öğrencilerin notları, aralık şeklinde seçilerek girilir. 'Yazı_say' satırına hipotezin yönü bilgisi tek yönlü hipotezler için 1, çift yönlü hipotezler için 2 olarak girilir. (Bu örnekte uyun olan 2'dir.) 'Tür' satırına bağımlı örneklemler t testi için 1, bağımsız örneklemler ve varyansların homojen olması durumunda 2, bağımsız örneklemler fakat varyansların homojenliğinin sağlanmadığı durumlarda 3 girilir. (Bu örnekte varyansların homojen olduğu varsayımıyla 2 girilmiştir.) 5. 'Tamam' tuşuna basıldığında önceden belirlenen hücrede, hesaplanan p olasılık değeri otomatik olarak gösterilir. Bu örnek için yukarıda açıklanan işlem adımları ve hesaplanan p olasılık değeri Şekil 2'de gösterilmektedir. Şekil 14.2'de görüldüğü gibi test istatistiğine yönelik p olasılık değeri, 0, olarak hesaplanmıştır.


104 Şekil Excell'de T Testi Uygulaması 101
BÖLÜM 4 FREKANS DAĞILIMLARININ GRAFİKLE GÖSTERİLMESİ
 BÖLÜM 4 FREKANS DAĞILIMLARININ GRAFİKLE GÖSTERİLMESİ Frekans dağılımlarının betimlenmesinde frekans tablolarının kullanılmasının yanı sıra grafik gösterimleri de sıklıkla kullanılmaktadır. Grafikler, görselliği
BÖLÜM 4 FREKANS DAĞILIMLARININ GRAFİKLE GÖSTERİLMESİ Frekans dağılımlarının betimlenmesinde frekans tablolarının kullanılmasının yanı sıra grafik gösterimleri de sıklıkla kullanılmaktadır. Grafikler, görselliği
BÖLÜM 2 VERİ SETİNİN HAZIRLANMASI VE DÜZENLENMESİ
 1 BÖLÜM 2 VERİ SETİNİN HAZIRLANMASI VE DÜZENLENMESİ Veri seti; satırlarında gözlem birimleri, sütunlarında ise değişkenler bulunan iki boyutlu bir matristir. Satır ve sütunların kesişim bölgelerine 'hücre
1 BÖLÜM 2 VERİ SETİNİN HAZIRLANMASI VE DÜZENLENMESİ Veri seti; satırlarında gözlem birimleri, sütunlarında ise değişkenler bulunan iki boyutlu bir matristir. Satır ve sütunların kesişim bölgelerine 'hücre
BÖLÜM 1 İSTATİSTİK İLE İLGİLİ BAZI TEMEL KAVRAMLAR
 1 BÖLÜM 1 İSTATİSTİK İLE İLGİLİ BAZI TEMEL KAVRAMLAR İstatistik öğrenmelerinde sıklıkla karşılaşılacak olan temel bazı kavramlar, eğitim alanına yönelik örnekleriyle birlikte aşağıda açıklanmaktadır. 1.1.
1 BÖLÜM 1 İSTATİSTİK İLE İLGİLİ BAZI TEMEL KAVRAMLAR İstatistik öğrenmelerinde sıklıkla karşılaşılacak olan temel bazı kavramlar, eğitim alanına yönelik örnekleriyle birlikte aşağıda açıklanmaktadır. 1.1.
BÖLÜM 5 MERKEZİ EĞİLİM ÖLÇÜLERİ
 1 BÖLÜM 5 MERKEZİ EĞİLİM ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel sayma
1 BÖLÜM 5 MERKEZİ EĞİLİM ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel sayma
BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ
 1 BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel
1 BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel
BÖLÜM 3 FREKANS DAĞILIMLARI VE FREKANS TABLOLARININ HAZIRLANMASI
 1 BÖLÜM 3 FREKANS DAĞILIMLARI VE FREKANS TABLOLARININ HAZIRLANMASI Ölçme sonuçları üzerinde yani amaçlanan özelliğe yönelik gözlemlerden elde edilen veriler üzerinde yapılacak istatistiksel işlemler genel
1 BÖLÜM 3 FREKANS DAĞILIMLARI VE FREKANS TABLOLARININ HAZIRLANMASI Ölçme sonuçları üzerinde yani amaçlanan özelliğe yönelik gözlemlerden elde edilen veriler üzerinde yapılacak istatistiksel işlemler genel
BÖLÜM 13 HİPOTEZ TESTİ
 1 BÖLÜM 13 HİPOTEZ TESTİ Bilimsel yöntem aşamalarıyla tanımlanmış sistematik bir bilgi üretme biçimidir. Bilimsel yöntemin aşamaları aşağıdaki gibi sıralanabilmektedir (Karasar, 2012): 1. Bir problemin
1 BÖLÜM 13 HİPOTEZ TESTİ Bilimsel yöntem aşamalarıyla tanımlanmış sistematik bir bilgi üretme biçimidir. Bilimsel yöntemin aşamaları aşağıdaki gibi sıralanabilmektedir (Karasar, 2012): 1. Bir problemin
BÖLÜM 10 PUAN DÖNÜŞÜMLERİ
 1 BÖLÜM 10 PUAN DÖNÜŞÜMLERİ Bir gözlem sonucunda elde edilen ve üzerinde herhangi bir düzenleme yapılmamış ölçme sonuçları 'ham veri' ya da 'ham puan' olarak isimlendirilir. Genellikle ham verilerin anlaşılması
1 BÖLÜM 10 PUAN DÖNÜŞÜMLERİ Bir gözlem sonucunda elde edilen ve üzerinde herhangi bir düzenleme yapılmamış ölçme sonuçları 'ham veri' ya da 'ham puan' olarak isimlendirilir. Genellikle ham verilerin anlaşılması
TEMEL İSTATİSTİKİ KAVRAMLAR YRD. DOÇ. DR. İBRAHİM ÇÜTCÜ
 TEMEL İSTATİSTİKİ KAVRAMLAR YRD. DOÇ. DR. İBRAHİM ÇÜTCÜ 1 İstatistik İstatistik, belirsizliğin veya eksik bilginin söz konusu olduğu durumlarda çıkarımlar yapmak ve karar vermek için sayısal verilerin
TEMEL İSTATİSTİKİ KAVRAMLAR YRD. DOÇ. DR. İBRAHİM ÇÜTCÜ 1 İstatistik İstatistik, belirsizliğin veya eksik bilginin söz konusu olduğu durumlarda çıkarımlar yapmak ve karar vermek için sayısal verilerin
İSTATİSTİKTE TEMEL KAVRAMLAR
 İSTATİSTİKTE TEMEL KAVRAMLAR 1. ve 2. Hafta İstatistik Nedir? Bir tanım olarak istatistik; belirsizlik altında bir konuda karar verebilmek amacıyla, ilgilenilen konuya ilişkin verilerin toplanması, düzenlenmesi,
İSTATİSTİKTE TEMEL KAVRAMLAR 1. ve 2. Hafta İstatistik Nedir? Bir tanım olarak istatistik; belirsizlik altında bir konuda karar verebilmek amacıyla, ilgilenilen konuya ilişkin verilerin toplanması, düzenlenmesi,
Kitle: Belirli bir özelliğe sahip bireylerin veya birimlerin tümünün oluşturduğu topluluğa kitle denir.
 BÖLÜM 1: FREKANS DAĞILIMLARI 1.1. Giriş İstatistik, rasgelelik içeren olaylar, süreçler, sistemler hakkında modeller kurmada, gözlemlere dayanarak bu modellerin geçerliliğini sınamada ve bu modellerden
BÖLÜM 1: FREKANS DAĞILIMLARI 1.1. Giriş İstatistik, rasgelelik içeren olaylar, süreçler, sistemler hakkında modeller kurmada, gözlemlere dayanarak bu modellerin geçerliliğini sınamada ve bu modellerden
GİRİŞ. Bilimsel Araştırma: Bilimsel bilgi elde etme süreci olarak tanımlanabilir.
 VERİ ANALİZİ GİRİŞ Bilimsel Araştırma: Bilimsel bilgi elde etme süreci olarak tanımlanabilir. Bilimsel Bilgi: Kaynağı ve elde edilme süreçleri belli olan bilgidir. Sosyal İlişkiler Görgül Bulgular İşlevsel
VERİ ANALİZİ GİRİŞ Bilimsel Araştırma: Bilimsel bilgi elde etme süreci olarak tanımlanabilir. Bilimsel Bilgi: Kaynağı ve elde edilme süreçleri belli olan bilgidir. Sosyal İlişkiler Görgül Bulgular İşlevsel
BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2
 1 BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2 Bu bölümde bir veri seti üzerinde betimsel istatistiklerin kestiriminde SPSS paket programının kullanımı açıklanmaktadır. Açıklamalar bir örnek üzerinde hareketle
1 BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2 Bu bölümde bir veri seti üzerinde betimsel istatistiklerin kestiriminde SPSS paket programının kullanımı açıklanmaktadır. Açıklamalar bir örnek üzerinde hareketle
Örnek 4.1: Tablo 2 de verilen ham verilerin aritmetik ortalamasını hesaplayınız.
 .4. Merkezi Eğilim ve Dağılım Ölçüleri Merkezi eğilim ölçüleri kitleye ilişkin bir değişkenin bütün farklı değerlerinin çevresinde toplandığı merkezi bir değeri gösterirler. Dağılım ölçüleri ise değişkenin
.4. Merkezi Eğilim ve Dağılım Ölçüleri Merkezi eğilim ölçüleri kitleye ilişkin bir değişkenin bütün farklı değerlerinin çevresinde toplandığı merkezi bir değeri gösterirler. Dağılım ölçüleri ise değişkenin
JEODEZİK VERİLERİN İSTATİSTİK ANALİZİ. Prof. Dr. Mualla YALÇINKAYA
 JEODEZİK VERİLERİN İSTATİSTİK ANALİZİ Prof. Dr. Mualla YALÇINKAYA Karadeniz Teknik Üniversitesi, Harita Mühendisliği Bölümü Trabzon, 2018 VERİLERİN İRDELENMESİ Örnek: İki nokta arasındaki uzunluk 80 kere
JEODEZİK VERİLERİN İSTATİSTİK ANALİZİ Prof. Dr. Mualla YALÇINKAYA Karadeniz Teknik Üniversitesi, Harita Mühendisliği Bölümü Trabzon, 2018 VERİLERİN İRDELENMESİ Örnek: İki nokta arasındaki uzunluk 80 kere
BÖLÜM 12 STUDENT T DAĞILIMI
 1 BÖLÜM 12 STUDENT T DAĞILIMI 'Student t dağılımı' ya da kısaca 't dağılımı'; normal dağılım ve Z dağılımının da içerisinde bulunduğu 'sürekli olasılık dağılımları' ailesinde yer alan dağılımlardan bir
1 BÖLÜM 12 STUDENT T DAĞILIMI 'Student t dağılımı' ya da kısaca 't dağılımı'; normal dağılım ve Z dağılımının da içerisinde bulunduğu 'sürekli olasılık dağılımları' ailesinde yer alan dağılımlardan bir
Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ
 Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ YARARLANILACAK ANA KAYNAK: SOSYAL BİLİMLER İÇİN İSTATİSTİK/ ŞENER BÜYÜKÖZTÜRK, ÖMAY ÇOKLUK, NİLGÜN KÖKLÜ/PEGEM YAY. YARDIMCI KAYNAKLAR:
Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ YARARLANILACAK ANA KAYNAK: SOSYAL BİLİMLER İÇİN İSTATİSTİK/ ŞENER BÜYÜKÖZTÜRK, ÖMAY ÇOKLUK, NİLGÜN KÖKLÜ/PEGEM YAY. YARDIMCI KAYNAKLAR:
VERİ KÜMELERİNİ BETİMLEME
 BETİMLEYİCİ İSTATİSTİK VERİ KÜMELERİNİ BETİMLEME Bir amaç için derlenen verilerin tamamının olduğu, veri kümesindeki birimlerin sayısal değerlerinden faydalanarak açık ve net bir şekilde ilgilenilen özellik
BETİMLEYİCİ İSTATİSTİK VERİ KÜMELERİNİ BETİMLEME Bir amaç için derlenen verilerin tamamının olduğu, veri kümesindeki birimlerin sayısal değerlerinden faydalanarak açık ve net bir şekilde ilgilenilen özellik
Genel olarak test istatistikleri. Merkezi Eğilim (Yığılma) Ölçüleri Dağılım (Yayılma) Ölçüleri. olmak üzere 2 grupta incelenebilir.
 Ölçüleri Dağılım (Yayılma) Ölçüleri. olmak üzere 2 grupta incelenebilir.") 4.SUNUM Genel olarak test istatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Dağılım (Yayılma) Ölçüleri olmak üzere 2 grupta incelenebilir. 2 Ranj Çeyrek Kayma Çeyrekler Arası Açıklık Standart Sapma Varyans
4.SUNUM Genel olarak test istatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Dağılım (Yayılma) Ölçüleri olmak üzere 2 grupta incelenebilir. 2 Ranj Çeyrek Kayma Çeyrekler Arası Açıklık Standart Sapma Varyans
TANIMLAYICI İSTATİSTİKLER
 TANIMLAYICI İSTATİSTİKLER Tanımlayıcı İstatistikler ve Grafikle Gösterim Grafik ve bir ölçüde tablolar değişkenlerin görsel bir özetini verirler. İdeal olarak burada değişkenlerin merkezi (ortalama) değerlerinin
TANIMLAYICI İSTATİSTİKLER Tanımlayıcı İstatistikler ve Grafikle Gösterim Grafik ve bir ölçüde tablolar değişkenlerin görsel bir özetini verirler. İdeal olarak burada değişkenlerin merkezi (ortalama) değerlerinin
Sıklık Tabloları, BASİT ve TEK değişkenli Grafikler Ders 3 ve 4 ve 5
 Sıklık Tabloları, BASİT ve TEK değişkenli Grafikler Ders 3 ve 4 ve 5 Sıklık Tabloları Veri dizisinde yer alan değerlerin tekrarlama sayılarını içeren tabloya sıklık tablosu denir. Tek değişken için çizilen
Sıklık Tabloları, BASİT ve TEK değişkenli Grafikler Ders 3 ve 4 ve 5 Sıklık Tabloları Veri dizisinde yer alan değerlerin tekrarlama sayılarını içeren tabloya sıklık tablosu denir. Tek değişken için çizilen
BÖLÜM 9 NORMAL DAĞILIM
 1 BÖLÜM 9 NORMAL DAĞILIM Normal dağılım; 'normal dağılım eğrisi (normaly distribution curve)' ile kavramlaştırılan hipotetik bir evren dağılımıdır. 'Gauss dağılımı' ya da 'Gauss eğrisi' olarak da bilinen
1 BÖLÜM 9 NORMAL DAĞILIM Normal dağılım; 'normal dağılım eğrisi (normaly distribution curve)' ile kavramlaştırılan hipotetik bir evren dağılımıdır. 'Gauss dağılımı' ya da 'Gauss eğrisi' olarak da bilinen
Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ
 Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ YARARLANILACAK ANA KAYNAK: SOSYAL BİLİMLER İÇİN İSTATİSTİK/ ŞENER BÜYÜKÖZTÜRK, ÖMAY ÇOKLUK, NİLGÜN KÖKLÜ/PEGEM YAY. YARDIMCI KAYNAKLAR:
Yrd.Doç.Dr. Ali SICAK BEÜ. EREĞLİ EĞİTİM FAKÜLTESİ EĞİTİM BİLİMLERİ BÖLÜMÜ YARARLANILACAK ANA KAYNAK: SOSYAL BİLİMLER İÇİN İSTATİSTİK/ ŞENER BÜYÜKÖZTÜRK, ÖMAY ÇOKLUK, NİLGÜN KÖKLÜ/PEGEM YAY. YARDIMCI KAYNAKLAR:
İSTATİSTİK I KISA ÖZET KOLAYAOF
 DİKKATİNİZE: BURADA SADECE ÖZETİN İLK ÜNİTESİ SİZE ÖRNEK OLARAK GÖSTERİLMİŞTİR. ÖZETİN TAMAMININ KAÇ SAYFA OLDUĞUNU ÜNİTELERİ İÇİNDEKİLER BÖLÜMÜNDEN GÖREBİLİRSİNİZ. İSTATİSTİK I KISA ÖZET KOLAYAOF 2 Kolayaof.com
DİKKATİNİZE: BURADA SADECE ÖZETİN İLK ÜNİTESİ SİZE ÖRNEK OLARAK GÖSTERİLMİŞTİR. ÖZETİN TAMAMININ KAÇ SAYFA OLDUĞUNU ÜNİTELERİ İÇİNDEKİLER BÖLÜMÜNDEN GÖREBİLİRSİNİZ. İSTATİSTİK I KISA ÖZET KOLAYAOF 2 Kolayaof.com
İstatistik Temel Kavramlar- Devam
 İstatistik Temel Kavramlar- Devam 26.12.2016 Dr. Seher Yalçın 1 Değişken türleri Değişken; gözlemden gözleme farklı değerler alabilen objelere, niteliklere ya da durumlara denir (Arıcı, 2006). Bir özellik
İstatistik Temel Kavramlar- Devam 26.12.2016 Dr. Seher Yalçın 1 Değişken türleri Değişken; gözlemden gözleme farklı değerler alabilen objelere, niteliklere ya da durumlara denir (Arıcı, 2006). Bir özellik
Yrd. Doç. Dr. Sedat Şen 9/27/2018 2
 2.SUNUM Belirli bir amaç için toplanmış verileri anlamlı haline getirmenin farklı yolları vardır. Verileri sözel ifadelerle açıklama Verileri tablolar halinde düzenleme Verileri grafiklerle gösterme Veriler
2.SUNUM Belirli bir amaç için toplanmış verileri anlamlı haline getirmenin farklı yolları vardır. Verileri sözel ifadelerle açıklama Verileri tablolar halinde düzenleme Verileri grafiklerle gösterme Veriler
BİLİMSEL ARAŞTIRMA YÖNTEMLERİ. Bazı Temel Kavramlar
 BİLİMSEL ARAŞTIRMA YÖNTEMLERİ Bazı Temel Kavramlar TEMEL ARAŞTIRMA KAVRAMLARI Bilimsel çalışmaların amacı, örneklem değerinden evren değerlerinin kestirilmesidir. Araştırma evreni (population) Evren, bütündeki
BİLİMSEL ARAŞTIRMA YÖNTEMLERİ Bazı Temel Kavramlar TEMEL ARAŞTIRMA KAVRAMLARI Bilimsel çalışmaların amacı, örneklem değerinden evren değerlerinin kestirilmesidir. Araştırma evreni (population) Evren, bütündeki
BÖLÜM 1 ÖLÇME VE DEĞERLENDİRMEDE TEMEL KAVRAMLAR
 İÇİNDEKİLER BÖLÜM 1 ÖLÇME VE DEĞERLENDİRMEDE TEMEL KAVRAMLAR I. Öğretimde Ölçme ve Değerlendirmenin Gerekliliği... 2 II. Ölçme Kavramı... 3 1. Tanımı ve Unsurları... 3 2. Aşamaları... 3 2.1. Ölçülecek
İÇİNDEKİLER BÖLÜM 1 ÖLÇME VE DEĞERLENDİRMEDE TEMEL KAVRAMLAR I. Öğretimde Ölçme ve Değerlendirmenin Gerekliliği... 2 II. Ölçme Kavramı... 3 1. Tanımı ve Unsurları... 3 2. Aşamaları... 3 2.1. Ölçülecek
Ölçme ve Değerlendirmenin. Eğitim Sistemi Açısından. Ölçme ve Değerlendirme. TESOY-Hafta Yrd. Doç. Dr.
 TESOY-Hafta-1 ve Değerlendirme BÖLÜM 1-2 ve Değerlendirmenin Önemi ve Temel Kavramları Yrd. Doç. Dr. Çetin ERDOĞAN cetinerdogan@gmail.com Eğitimde ölçme ve değerlendirme neden önemlidir? Eğitim politikalarına
TESOY-Hafta-1 ve Değerlendirme BÖLÜM 1-2 ve Değerlendirmenin Önemi ve Temel Kavramları Yrd. Doç. Dr. Çetin ERDOĞAN cetinerdogan@gmail.com Eğitimde ölçme ve değerlendirme neden önemlidir? Eğitim politikalarına
TEMEL İSTATİSTİK BİLGİSİ. İstatistiksel verileri tasnif etme Verilerin grafiklerle ifade edilmesi Vasat ölçüleri Standart puanlar
 TEMEL İSTATİSTİK BİLGİSİ İstatistiksel verileri tasnif etme Verilerin grafiklerle ifade edilmesi Vasat ölçüleri Standart puanlar İstatistiksel Verileri Tasnif Etme Verileri daha anlamlı hale getirmek amacıyla
TEMEL İSTATİSTİK BİLGİSİ İstatistiksel verileri tasnif etme Verilerin grafiklerle ifade edilmesi Vasat ölçüleri Standart puanlar İstatistiksel Verileri Tasnif Etme Verileri daha anlamlı hale getirmek amacıyla
OLASILIK ve KURAMSAL DAĞILIMLAR
 OLASILIK ve KURAMSAL DAĞILIMLAR Kuramsal Dağılımlar İstatistiksel çözümlemelerde; değişkenlerimizin dağılma özellikleri, çözümleme yönteminin seçimi ve sonuçlarının yorumlanmasında önemlidir. Dağılma özelliklerine
OLASILIK ve KURAMSAL DAĞILIMLAR Kuramsal Dağılımlar İstatistiksel çözümlemelerde; değişkenlerimizin dağılma özellikleri, çözümleme yönteminin seçimi ve sonuçlarının yorumlanmasında önemlidir. Dağılma özelliklerine
Merkezi Eğilim ve Dağılım Ölçüleri
 Merkezi Eğilim ve Dağılım Ölçüleri Soru Öğrencilerin derse katılım düzeylerini ölçmek amacıyla geliştirilen 16 soruluk bir test için öğrencilerin ilk 8 ve son 8 soruluk yarılardan aldıkları puanlar arasındaki
Merkezi Eğilim ve Dağılım Ölçüleri Soru Öğrencilerin derse katılım düzeylerini ölçmek amacıyla geliştirilen 16 soruluk bir test için öğrencilerin ilk 8 ve son 8 soruluk yarılardan aldıkları puanlar arasındaki
Ders 8: Verilerin Düzenlenmesi ve Analizi
 Ders 8: Verilerin Düzenlenmesi ve Analizi Betimsel İstatistik Merkezsel Eğilim Ölçüleri Dağılım Ölçüleri Grafiksel Gösterimler Bir kitlenin tamamını, ya da kitleden alınan bir örneklemi özetlemekle (betimlemekle)
Ders 8: Verilerin Düzenlenmesi ve Analizi Betimsel İstatistik Merkezsel Eğilim Ölçüleri Dağılım Ölçüleri Grafiksel Gösterimler Bir kitlenin tamamını, ya da kitleden alınan bir örneklemi özetlemekle (betimlemekle)
SPSS E GİRİŞ SPSS TE TEMEL İŞLEMLER. Abdullah Can
 SPSS E GİRİŞ SPSS TE TEMEL İŞLEMLER SPSS in üzerinde işlem yapılabilecek iki ana ekran görünümü vardır. DATA VIEW (VERİ görünümü) VARIABLE VIEW (DEĞİŞKEN görünümü) 1 DATA VIEW (VERİ görünümü) İstatistiksel
SPSS E GİRİŞ SPSS TE TEMEL İŞLEMLER SPSS in üzerinde işlem yapılabilecek iki ana ekran görünümü vardır. DATA VIEW (VERİ görünümü) VARIABLE VIEW (DEĞİŞKEN görünümü) 1 DATA VIEW (VERİ görünümü) İstatistiksel
İSTATİSTİK STATISTICS (2+0) Yrd.Doç.Dr. Nil TOPLAN SAÜ.MÜH. FAK. METALURJİ VE MALZEME MÜH. BÖLÜMÜ ÖĞRETİM ÜYESİ ÖĞRETİM YILI
 Yrd.Doç.Dr. Nil TOPLAN SAÜ.MÜH. FAK. METALURJİ VE MALZEME MÜH. BÖLÜMÜ ÖĞRETİM ÜYESİ ÖĞRETİM YILI") İSTATİSTİK STATISTICS (+) Yrd.Doç.Dr. Nil TOPLAN SAÜ.MÜH. FAK. METALURJİ VE MALZEME MÜH. BÖLÜMÜ ÖĞRETİM ÜYESİ ÖĞRETİM YILI KONU BAŞLIKLARI :. İSTATİSTİĞE GİRİŞ. VERİLERİN DÜZENLENMESİ. MERKEZİ EĞİLİM ÖLÇÜLERİ.
İSTATİSTİK STATISTICS (+) Yrd.Doç.Dr. Nil TOPLAN SAÜ.MÜH. FAK. METALURJİ VE MALZEME MÜH. BÖLÜMÜ ÖĞRETİM ÜYESİ ÖĞRETİM YILI KONU BAŞLIKLARI :. İSTATİSTİĞE GİRİŞ. VERİLERİN DÜZENLENMESİ. MERKEZİ EĞİLİM ÖLÇÜLERİ.
Örnek...4 : İlk iki sınavında 75 ve 82 alan bir öğrencinin bu dersin ortalamasını 5 yapabilmek için son sınavdan kaç alması gerekmektedir?
 İSTATİSTİK Bir sonuç çıkarmak ya da çözüme ulaşabilmek için gözlem, deney, araştırma gibi yöntemlerle toplanan bilgiye veri adı verilir. Örnek...4 : İlk iki sınavında 75 ve 82 alan bir öğrencinin bu dersin
İSTATİSTİK Bir sonuç çıkarmak ya da çözüme ulaşabilmek için gözlem, deney, araştırma gibi yöntemlerle toplanan bilgiye veri adı verilir. Örnek...4 : İlk iki sınavında 75 ve 82 alan bir öğrencinin bu dersin
Test İstatistikleri AHMET SALİH ŞİMŞEK
 Test İstatistikleri AHMET SALİH ŞİMŞEK İçindekiler Test İstatistikleri Merkezi Eğilim Tepe Değer (Mod) Ortanca (Medyan) Aritmetik Ortalama Merkezi Dağılım Dizi Genişliği (Ranj) Standart Sapma Varyans Çarpıklık
Test İstatistikleri AHMET SALİH ŞİMŞEK İçindekiler Test İstatistikleri Merkezi Eğilim Tepe Değer (Mod) Ortanca (Medyan) Aritmetik Ortalama Merkezi Dağılım Dizi Genişliği (Ranj) Standart Sapma Varyans Çarpıklık
İstatistik. Temel Kavramlar Dr. Seher Yalçın 1
 İstatistik Temel Kavramlar 26.12.2016 Dr. Seher Yalçın 1 Evren (Kitle/Yığın/Popülasyon) Herhangi bir gözlem ya da inceleme kapsamına giren obje ya da bireylerin oluşturduğu bütüne ya da gruba Evren veya
İstatistik Temel Kavramlar 26.12.2016 Dr. Seher Yalçın 1 Evren (Kitle/Yığın/Popülasyon) Herhangi bir gözlem ya da inceleme kapsamına giren obje ya da bireylerin oluşturduğu bütüne ya da gruba Evren veya
Prof.Dr.İhsan HALİFEOĞLU
 Prof.Dr.İhsan HALİFEOĞLU ÖDEV: Aşağıda verilen 100 öğrenciye ait gözlem değerlerinin aritmetik ortalama, standart sapma, ortanca ve tepe değerini bulunuz. (sınıf aralığını 5 alınız) 155 160 164 165 168
Prof.Dr.İhsan HALİFEOĞLU ÖDEV: Aşağıda verilen 100 öğrenciye ait gözlem değerlerinin aritmetik ortalama, standart sapma, ortanca ve tepe değerini bulunuz. (sınıf aralığını 5 alınız) 155 160 164 165 168
İSTATİSTİK 1. Ankara Üniversitesi Eğitim Bilimleri Fakültesi Ölçme ve Değerlendirme Anabilim Dalı. Yrd. Doç. Dr. C. Deha DOĞAN
 İSTATİSTİK 1 Ankara Üniversitesi Eğitim Bilimleri Fakültesi Ölçme ve Değerlendirme Anabilim Dalı Yrd. Doç. Dr. C. Deha DOĞAN 4. ÇEŞİT YALAN VARDIR, BEYAZ YALAN YALAN KUYRUKLU YALAN İSTATİSTİK Rakamlar
İSTATİSTİK 1 Ankara Üniversitesi Eğitim Bilimleri Fakültesi Ölçme ve Değerlendirme Anabilim Dalı Yrd. Doç. Dr. C. Deha DOĞAN 4. ÇEŞİT YALAN VARDIR, BEYAZ YALAN YALAN KUYRUKLU YALAN İSTATİSTİK Rakamlar
VERİLERİN SINIFLANDIRILMASI
 VERİLERİN SINIFLANDIRILMASI Yrd. Doç. Dr. Ünal ERKORKMAZ Sakarya Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı uerkorkmaz@sakarya.edu.tr NİTEL VE NİCEL VERİLERİN SINIFLANDIRMASI Sınıflandırma
VERİLERİN SINIFLANDIRILMASI Yrd. Doç. Dr. Ünal ERKORKMAZ Sakarya Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı uerkorkmaz@sakarya.edu.tr NİTEL VE NİCEL VERİLERİN SINIFLANDIRMASI Sınıflandırma
İstatistiK. Yrd.Doç.Dr. Levent TERLEMEZ
 İstatistiK Yrd.Doç.Dr. Levent TERLEMEZ istatistik birimlerin ya da bireylerin sayılabilir, tartılabilir ve ölçülebilir özellikleri ile ilgili bilgilerin yani verilerin toplanması toplanan verilerin açık
İstatistiK Yrd.Doç.Dr. Levent TERLEMEZ istatistik birimlerin ya da bireylerin sayılabilir, tartılabilir ve ölçülebilir özellikleri ile ilgili bilgilerin yani verilerin toplanması toplanan verilerin açık
Ders 1 Minitab da Grafiksel Analiz-I
 ENM 5210 İSTATİSTİK VE YAZILIMLA UYGULAMALARI Ders 1 Minitab da Grafiksel Analiz-I İstatistik Nedir? İstatistik kelimesi ilk olarak Almanyada devlet anlamına gelen status kelimesine dayanılarak kullanılmaya
ENM 5210 İSTATİSTİK VE YAZILIMLA UYGULAMALARI Ders 1 Minitab da Grafiksel Analiz-I İstatistik Nedir? İstatistik kelimesi ilk olarak Almanyada devlet anlamına gelen status kelimesine dayanılarak kullanılmaya
SÜREKLĠ OLASILIK DAĞILIMLARI
 SÜREKLĠ OLASILIK DAĞILIMLARI Sayı ekseni üzerindeki tüm noktalarda değer alabilen değişkenler, sürekli değişkenler olarak tanımlanmaktadır. Bu bölümde, sürekli değişkenlere uygun olasılık dağılımları üzerinde
SÜREKLĠ OLASILIK DAĞILIMLARI Sayı ekseni üzerindeki tüm noktalarda değer alabilen değişkenler, sürekli değişkenler olarak tanımlanmaktadır. Bu bölümde, sürekli değişkenlere uygun olasılık dağılımları üzerinde
2- VERİLERİN TOPLANMASI
 2- VERİLERİN TOPLANMASI Bu bölümde yararlanılan kaynaklar: İşletme İstatistiğine Giriş (Prof. Dr. İsmail Hakkı Armutlulu) ve İşletme İstatistiğinin Temelleri (Bowerman, O Connell, Murphree, Orris Editör:
2- VERİLERİN TOPLANMASI Bu bölümde yararlanılan kaynaklar: İşletme İstatistiğine Giriş (Prof. Dr. İsmail Hakkı Armutlulu) ve İşletme İstatistiğinin Temelleri (Bowerman, O Connell, Murphree, Orris Editör:
İstatistik Nedir? Ders 1 Minitab da Grafiksel Analiz-I ENM 5210 İSTATİSTİK VE YAZILIMLA UYGULAMALARI. İstatistiğin Konusu Olan Olaylar
 ENM 5210 İSTATİSTİK VE YAZILIMLA UYGULAMALARI İstatistik Nedir? İstatistik kelimesi ilk olarak Almanyada devlet anlamına gelen status kelimesine dayanılarak kullanılmaya başlanmıştır. Ders 1 Minitab da
ENM 5210 İSTATİSTİK VE YAZILIMLA UYGULAMALARI İstatistik Nedir? İstatistik kelimesi ilk olarak Almanyada devlet anlamına gelen status kelimesine dayanılarak kullanılmaya başlanmıştır. Ders 1 Minitab da
Veri Toplama, Verilerin Özetlenmesi ve Düzenlenmesi. BBY 606 Araştırma Yöntemleri
 Veri Toplama, Verilerin Özetlenmesi ve Düzenlenmesi BBY 606 Araştırma Yöntemleri 1 SPSS in açılması 2 SPSS programı 3 Veri giriş ekranı 4 Değişken giriş ekranı 5 Veri toplama Kayıtlardan yararlanarak Örneğin
Veri Toplama, Verilerin Özetlenmesi ve Düzenlenmesi BBY 606 Araştırma Yöntemleri 1 SPSS in açılması 2 SPSS programı 3 Veri giriş ekranı 4 Değişken giriş ekranı 5 Veri toplama Kayıtlardan yararlanarak Örneğin
İstatistik ve Olasılık
 İstatistik ve Olasılık Ders 2: Prof. Dr. İrfan KAYMAZ Tanım İnceleme sonucu elde edilen ham verilerin istatistiksel yöntemler kullanılarak özetlenmesi açıklayıcı istatistiği konusudur. Açıklayıcı istatistikte
İstatistik ve Olasılık Ders 2: Prof. Dr. İrfan KAYMAZ Tanım İnceleme sonucu elde edilen ham verilerin istatistiksel yöntemler kullanılarak özetlenmesi açıklayıcı istatistiği konusudur. Açıklayıcı istatistikte
İstatistik ve Olasılık
 İstatistik ve Olasılık Ders 2: Prof. Dr. İrfan KAYMAZ Tanım İnceleme sonucu elde edilen ham verilerin istatistiksel yöntemler kullanılarak özetlenmesi açıklayıcı istatistiği konusudur. Açıklayıcı istatistikte
İstatistik ve Olasılık Ders 2: Prof. Dr. İrfan KAYMAZ Tanım İnceleme sonucu elde edilen ham verilerin istatistiksel yöntemler kullanılarak özetlenmesi açıklayıcı istatistiği konusudur. Açıklayıcı istatistikte
BÖLÜM 14 BİLGİSAYAR UYGULAMALARI - 3 (ORTALAMALARIN KARŞILAŞTIRILMASI)
") 1 BÖLÜM 14 BİLGİSAYAR UYGULAMALARI - 3 (ORTALAMALARIN KARŞILAŞTIRILMASI) Hipotez testi konusunda görüldüğü üzere temel betimleme, sayma ve sınıflama işlemlerine dayalı yöntemlerin ötesinde normal dağılım
1 BÖLÜM 14 BİLGİSAYAR UYGULAMALARI - 3 (ORTALAMALARIN KARŞILAŞTIRILMASI) Hipotez testi konusunda görüldüğü üzere temel betimleme, sayma ve sınıflama işlemlerine dayalı yöntemlerin ötesinde normal dağılım
Merkezi Yığılma ve Dağılım Ölçüleri
 1.11.013 Merkezi Yığılma ve Dağılım Ölçüleri 4.-5. hafta Merkezi eğilim ölçüleri, belli bir özelliğe ya da değişkene ilişkin ölçme sonuçlarının, hangi değer etrafında toplandığını gösteren ve veri grubunu
1.11.013 Merkezi Yığılma ve Dağılım Ölçüleri 4.-5. hafta Merkezi eğilim ölçüleri, belli bir özelliğe ya da değişkene ilişkin ölçme sonuçlarının, hangi değer etrafında toplandığını gösteren ve veri grubunu
EĞĠTĠMDE ÖLÇME VE DEĞERLENDĠRME BÖLÜM IV Ölçme Sonuçları Üzerinde Ġstatistiksel ĠĢlemler VERİLERİN DÜZENLENMESİ VERİLERİN DÜZENLENMESİ
 09.0.0 Temel Kavramlar EĞĠTĠMDE ÖLÇME VE DEĞERLENDĠRME BÖLÜM IV Ölçme Sonuçları Üzerinde Ġstatistiksel ĠĢlemler Dr. Aylin ALBAYRAK SARI Hacettepe Üniversitesi Eğitim Fakültesi Evren: Üzerinde çalışılacak
09.0.0 Temel Kavramlar EĞĠTĠMDE ÖLÇME VE DEĞERLENDĠRME BÖLÜM IV Ölçme Sonuçları Üzerinde Ġstatistiksel ĠĢlemler Dr. Aylin ALBAYRAK SARI Hacettepe Üniversitesi Eğitim Fakültesi Evren: Üzerinde çalışılacak
Genel olarak test istatistikleri. Merkezi Eğilim (Yığılma) Ölçüleri Merkezi Dağılım (Yayılma) Ölçüleri. olmak üzere 2 grupta incelenebilir.
 Ölçüleri Merkezi Dağılım (Yayılma) Ölçüleri. olmak üzere 2 grupta incelenebilir.") 3.SUNUM Genel olarak test istatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Merkezi Dağılım (Yayılma) Ölçüleri olmak üzere 2 grupta incelenebilir. 2 Merkezi Eğilim Ölçüleri, belli bir özelliğe ya da değişkene
3.SUNUM Genel olarak test istatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Merkezi Dağılım (Yayılma) Ölçüleri olmak üzere 2 grupta incelenebilir. 2 Merkezi Eğilim Ölçüleri, belli bir özelliğe ya da değişkene
BÖLÜM I:TEMEL KAVRAMLAR
 İÇİNDEKİLER Önsöz. III BÖLÜM I:TEMEL KAVRAMLAR 13 Eğitim.. 13 Eğitim Türleri ve Sınıflandırılması. 17 Formal (Resmi, Biçimsel) Eğitim.... 18 İnformal (Resmi Olmayan, Biçimsel Olamayan).. 20 Davranış..
İÇİNDEKİLER Önsöz. III BÖLÜM I:TEMEL KAVRAMLAR 13 Eğitim.. 13 Eğitim Türleri ve Sınıflandırılması. 17 Formal (Resmi, Biçimsel) Eğitim.... 18 İnformal (Resmi Olmayan, Biçimsel Olamayan).. 20 Davranış..
SPSS-Tarihsel Gelişimi
 SPSS -Giriş SPSS-Tarihsel Gelişimi ilk sürümü Norman H. Nie, C. Hadlai Hull ve Dale H. Bent tarafından geliştirilmiş ve 1968 yılında piyasaya çıkmış istatistiksel analize yönelik bir bilgisayar programıdır.
SPSS -Giriş SPSS-Tarihsel Gelişimi ilk sürümü Norman H. Nie, C. Hadlai Hull ve Dale H. Bent tarafından geliştirilmiş ve 1968 yılında piyasaya çıkmış istatistiksel analize yönelik bir bilgisayar programıdır.
Verilerin Özetlenmesinde Kullanılan Tablolar ve Grafiksel Yöntemler
 Verilerin Özetlenmesinde Kullanılan Tablolar ve Grafiksel Yöntemler Frekans Dağılımları Verilerin Düzenlenmesi Sıralı dizi bir dizi verinin küçükten büyüğe yada büyükten küçüğe göre sıralanması Dağılı
Verilerin Özetlenmesinde Kullanılan Tablolar ve Grafiksel Yöntemler Frekans Dağılımları Verilerin Düzenlenmesi Sıralı dizi bir dizi verinin küçükten büyüğe yada büyükten küçüğe göre sıralanması Dağılı
Örneklemden elde edilen parametreler üzerinden kitle parametreleri tahmin edilmek istenmektedir.
 ÇIKARSAMALI İSTATİSTİKLER Çıkarsamalı istatistikler, örneklemden elde edilen değerler üzerinde kitleyi tanımlamak için uygulanan istatistiksel yöntemlerdir. Çıkarsamalı istatistikler; Tahmin Hipotez Testleri
ÇIKARSAMALI İSTATİSTİKLER Çıkarsamalı istatistikler, örneklemden elde edilen değerler üzerinde kitleyi tanımlamak için uygulanan istatistiksel yöntemlerdir. Çıkarsamalı istatistikler; Tahmin Hipotez Testleri
AKSARAYLI TEMEL İSTATİSTİK YÖNTEMLER
 TEMEL İSTATİSTİK YÖNTEMLER DERS I - 1/63 İstatistik nedir? 1. 2. tanımı) 3. (En eski tanımı) (Yöntembilim olarak (Kelime anlamı) DERS I - 2/63 İstatistik nedir? 1. Veri toplama Araştırma 2. Verilerin sınıflandırılması
TEMEL İSTATİSTİK YÖNTEMLER DERS I - 1/63 İstatistik nedir? 1. 2. tanımı) 3. (En eski tanımı) (Yöntembilim olarak (Kelime anlamı) DERS I - 2/63 İstatistik nedir? 1. Veri toplama Araştırma 2. Verilerin sınıflandırılması
Kullanılacak İstatistikleri Belirleme Ölçütleri. Değişkenin Ölçek Türü ya da Yapısı
 ARAŞTIRMA MODELLİLERİNDE KULLANILACAK İSTATİSTİKLERİ BELİRLEME ÖLÇÜTLERİ Parametrik mi Parametrik Olmayan mı? Kullanılacak İstatistikleri Belirleme Ölçütleri Değişken Sayısı Tek değişkenli (X) İki değişkenli
ARAŞTIRMA MODELLİLERİNDE KULLANILACAK İSTATİSTİKLERİ BELİRLEME ÖLÇÜTLERİ Parametrik mi Parametrik Olmayan mı? Kullanılacak İstatistikleri Belirleme Ölçütleri Değişken Sayısı Tek değişkenli (X) İki değişkenli
BKİ farkı Standart Sapması (kg/m 2 ) A B BKİ farkı Ortalaması (kg/m 2 )
 A B BKİ farkı Ortalaması (kg/m 2 )") 4. SUNUM 1 Gözlem ya da deneme sonucu elde edilmiş sonuçların, rastlantıya bağlı olup olmadığının incelenmesinde kullanılan istatistiksel yöntemlere HİPOTEZ TESTLERİ denir. Sonuçların rastlantıya bağlı
4. SUNUM 1 Gözlem ya da deneme sonucu elde edilmiş sonuçların, rastlantıya bağlı olup olmadığının incelenmesinde kullanılan istatistiksel yöntemlere HİPOTEZ TESTLERİ denir. Sonuçların rastlantıya bağlı
Verilerin Özetlenmesinde Kullanılan Sayısal Yöntemler
 Verilerin Özetlenmesinde Kullanılan Sayısal Yöntemler Merkezi Eğilim Ölçüleri Merkezi eğilim ölçüsü, bir veri setindeki merkezi, yada tipik, tek bir değeri ifade eder. Nicel veriler için, reel sayı çizgisindeki
Verilerin Özetlenmesinde Kullanılan Sayısal Yöntemler Merkezi Eğilim Ölçüleri Merkezi eğilim ölçüsü, bir veri setindeki merkezi, yada tipik, tek bir değeri ifade eder. Nicel veriler için, reel sayı çizgisindeki
TEMEL EĞİTİMDEN ORTAÖĞRETİME GEÇİŞ ORTAK SINAV BAŞARISININ ÇEŞİTLİ DEĞİŞKENLER AÇISINDAN İNCELENMESİ
 T.C. MİLLÎ EĞİTİM BAKANLIĞI ÖLÇME, DEĞERLENDİRME VE SINAV HİZMETLERİ GENEL MÜDÜRLÜĞÜ VERİ ANALİZİ, İZLEME VE DEĞERLENDİRME DAİRE BAŞKANLIĞI TEMEL EĞİTİMDEN ORTAÖĞRETİME GEÇİŞ ORTAK SINAV BAŞARISININ ÇEŞİTLİ
T.C. MİLLÎ EĞİTİM BAKANLIĞI ÖLÇME, DEĞERLENDİRME VE SINAV HİZMETLERİ GENEL MÜDÜRLÜĞÜ VERİ ANALİZİ, İZLEME VE DEĞERLENDİRME DAİRE BAŞKANLIĞI TEMEL EĞİTİMDEN ORTAÖĞRETİME GEÇİŞ ORTAK SINAV BAŞARISININ ÇEŞİTLİ
DEĞERLENDİRME ARASINDAKİ İLİŞKİLER... 1
 İÇİNDEKİLER ÖNSÖZ... xxii BÖLÜM 1 - ÖĞRENME, ÖĞRETİM VE DEĞERLENDİRME ARASINDAKİ İLİŞKİLER... 1 EĞİTİM SÜRECİ VE ÖĞRENME... 2 Öğrenme ve Bilişsel Yaklaşım... 3 Bilişsel Yaklaşımın Eğitimdeki Genel Sonuçları...
İÇİNDEKİLER ÖNSÖZ... xxii BÖLÜM 1 - ÖĞRENME, ÖĞRETİM VE DEĞERLENDİRME ARASINDAKİ İLİŞKİLER... 1 EĞİTİM SÜRECİ VE ÖĞRENME... 2 Öğrenme ve Bilişsel Yaklaşım... 3 Bilişsel Yaklaşımın Eğitimdeki Genel Sonuçları...
2. HAFTA PFS 107 EĞİTİMDE ÖLÇME VE DEĞERLENDİRME. Yrd. Doç Dr. Fatma Betül Kurnaz. betulkurnaz@karabuk.edu.tr KBUZEM. Karabük Üniversitesi
 2. HAFTA PFS 107 EĞİTİMDE Yrd. Doç Dr. Fatma Betül Kurnaz betulkurnaz@karabuk.edu.tr Karabük Üniversitesi Uzaktan Eğitim Uygulama ve Araştırma Merkezi 2 İçindekiler Ölçmede Sıfır Noktası... Hata! Yer işareti
2. HAFTA PFS 107 EĞİTİMDE Yrd. Doç Dr. Fatma Betül Kurnaz betulkurnaz@karabuk.edu.tr Karabük Üniversitesi Uzaktan Eğitim Uygulama ve Araştırma Merkezi 2 İçindekiler Ölçmede Sıfır Noktası... Hata! Yer işareti
Evren (Popülasyon) Araştırma kapsamına giren tüm elemanların oluşturduğu grup. Araştırma sonuçlarının genelleneceği grup
 Araştırma kapsamına giren tüm elemanların oluşturduğu grup. Araştırma sonuçlarının genelleneceği grup") Evren (Popülasyon) Araştırma kapsamına giren tüm elemanların oluşturduğu grup Araştırma sonuçlarının genelleneceği grup Evrendeğer (Parametre): Değişkenlerin evrendeki değerleri µ : Evren Ortalaması σ
Evren (Popülasyon) Araştırma kapsamına giren tüm elemanların oluşturduğu grup Araştırma sonuçlarının genelleneceği grup Evrendeğer (Parametre): Değişkenlerin evrendeki değerleri µ : Evren Ortalaması σ
Veri Analizi. Isınma Hareketleri. Test İstatistikleri. b) En çok tekrar eden: 7 (mod) c) Açıklık = En büyük En küçük = 10 1 = 9. d)
 En çok tekrar eden: 7 (mod) c) Açıklık = En büyük En küçük = 10 1 = 9. d)") Isınma Hareketleri 1 Aşağıda verilenleri inceleyiniz. Test İstatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Aritmetik ortalama Tepe değer (mod) Ortanca (medyan) Merkezi Dağılım (Yayılma) Ölçüleri Açıklık
Isınma Hareketleri 1 Aşağıda verilenleri inceleyiniz. Test İstatistikleri Merkezi Eğilim (Yığılma) Ölçüleri Aritmetik ortalama Tepe değer (mod) Ortanca (medyan) Merkezi Dağılım (Yayılma) Ölçüleri Açıklık
Korelasyon, Korelasyon Türleri ve Regresyon
 Korelasyon, Korelasyon Türleri ve Regresyon İçerik Korelasyon Korelasyon Türleri Korelasyon Katsayısı Regresyon KORELASYON Korelasyon iki ya da daha fazla değişken arasındaki doğrusal ilişkiyi gösterir.
Korelasyon, Korelasyon Türleri ve Regresyon İçerik Korelasyon Korelasyon Türleri Korelasyon Katsayısı Regresyon KORELASYON Korelasyon iki ya da daha fazla değişken arasındaki doğrusal ilişkiyi gösterir.
BİYOİSTATİSTİK. Genel Uygulama 1. Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH
 BİYOİSTATİSTİK Genel Uygulama 1 Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr Soru 1 Ege Üniversitesi Diş
BİYOİSTATİSTİK Genel Uygulama 1 Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr Soru 1 Ege Üniversitesi Diş
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler
 Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr - 1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi gerekenler -
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr - 1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi gerekenler -
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler
 Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 4 Kasım 2016-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 4 Kasım 2016-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
Tanımlayıcı İstatistikler. Yrd. Doç. Dr. Emre ATILGAN
 Tanımlayıcı İstatistikler Yrd. Doç. Dr. Emre ATILGAN 1 Tanımlayıcı İstatistikler Yer Gösteren Ölçüler Yaygınlık Ölçüleri Merkezi Eğilim Ölçüleri Konum Ölçüleri 2 3 Aritmetik Ortalama Aritmetik ortalama,
Tanımlayıcı İstatistikler Yrd. Doç. Dr. Emre ATILGAN 1 Tanımlayıcı İstatistikler Yer Gösteren Ölçüler Yaygınlık Ölçüleri Merkezi Eğilim Ölçüleri Konum Ölçüleri 2 3 Aritmetik Ortalama Aritmetik ortalama,
İstatistik, genel olarak, rassal bir olayı (ya da deneyi) matematiksel olarak modellemek ve bu model yardımıyla, anakütlenin bilinmeyen karakteristik
 matematiksel olarak modellemek ve bu model yardımıyla, anakütlenin bilinmeyen karakteristik") 6.SUNUM İstatistik, genel olarak, rassal bir olayı (ya da deneyi) matematiksel olarak modellemek ve bu model yardımıyla, anakütlenin bilinmeyen karakteristik özellikleri (ortalama, varyans v.b. gibi) hakkında
6.SUNUM İstatistik, genel olarak, rassal bir olayı (ya da deneyi) matematiksel olarak modellemek ve bu model yardımıyla, anakütlenin bilinmeyen karakteristik özellikleri (ortalama, varyans v.b. gibi) hakkında
TABLO ve GRAFİKLER. Epidemiyoloji Konferansları Serisi 14.05.2015. Prof. Dr. Bahar GÜÇİZ DOĞAN, HÜTF Halk Sağlığı AD.
 TABLO ve GRAFİKLER Epidemiyoloji Konferansları Serisi 14.05.2015 Prof. Dr. Bahar GÜÇİZ DOĞAN, HÜTF Prof. Dr. Bahar GÜÇİZ DOĞAN, HÜTF Neden gerekli? Tablo ve grafikler araştırma sonucunda elde edilen verilerin
TABLO ve GRAFİKLER Epidemiyoloji Konferansları Serisi 14.05.2015 Prof. Dr. Bahar GÜÇİZ DOĞAN, HÜTF Prof. Dr. Bahar GÜÇİZ DOĞAN, HÜTF Neden gerekli? Tablo ve grafikler araştırma sonucunda elde edilen verilerin
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler
 Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 16 Ekim 2015-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 16 Ekim 2015-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
SPSS (Statistical Package for Social Sciences)
") SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) Data Editör iki arayüzden oluşur. 1. Data View 2. Variable
SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) Data Editör iki arayüzden oluşur. 1. Data View 2. Variable
Mühendislikte İstatistiksel Yöntemler
 Mühendislikte İstatistiksel Yöntemler BÖLÜM 2 AÇIKLAYICI (BETİMLEYİCİ) İSTATİSTİK Yrd. Doç. Dr. Fatih TOSUNOĞLU 1-Açıklayıcı (Betimleyici) İstatistik İnceleme sonucu elde edilen ham verilerin istatistiksel
Mühendislikte İstatistiksel Yöntemler BÖLÜM 2 AÇIKLAYICI (BETİMLEYİCİ) İSTATİSTİK Yrd. Doç. Dr. Fatih TOSUNOĞLU 1-Açıklayıcı (Betimleyici) İstatistik İnceleme sonucu elde edilen ham verilerin istatistiksel
KPSS. Eğitim Bilimleri. ezberbozan. serisi. KPSS Ders Notları. özetlenmiş içerik pratik bilgiler kritik notlar ilgi çekici görseller
 KPSS Eğitim Bilimleri ezberbozan serisi özetlenmiş içerik pratik bilgiler kritik notlar ilgi çekici görseller EDİTÖR: Savaş Doğan KPSS ÖLÇME VE DEĞERLENDİRME DERS NOTLARI ISBN 978-605-364-733-1 Kitap içeriğinin
KPSS Eğitim Bilimleri ezberbozan serisi özetlenmiş içerik pratik bilgiler kritik notlar ilgi çekici görseller EDİTÖR: Savaş Doğan KPSS ÖLÇME VE DEĞERLENDİRME DERS NOTLARI ISBN 978-605-364-733-1 Kitap içeriğinin
SPSS (Statistical Package for Social Sciences)
") SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) SPSS Data Editör iki arayüzden oluşur. 1. Data View
SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) SPSS Data Editör iki arayüzden oluşur. 1. Data View
İÇİNDEKİLER. BÖLÜM 1 Değişkenler ve Grafikler 1. BÖLÜM 2 Frekans Dağılımları 37
 İÇİNDEKİLER BÖLÜM 1 Değişkenler ve Grafikler 1 İstatistik 1 Yığın ve Örnek; Tümevarımcı ve Betimleyici İstatistik 1 Değişkenler: Kesikli ve Sürekli 1 Verilerin Yuvarlanması Bilimsel Gösterim Anlamlı Rakamlar
İÇİNDEKİLER BÖLÜM 1 Değişkenler ve Grafikler 1 İstatistik 1 Yığın ve Örnek; Tümevarımcı ve Betimleyici İstatistik 1 Değişkenler: Kesikli ve Sürekli 1 Verilerin Yuvarlanması Bilimsel Gösterim Anlamlı Rakamlar
T.C. MUĞLA SITKI KOÇMAN ÜNİVERSİTESİ EĞİTİM BİLİMLERİ ENSTİTÜSÜ
 T.C. MUĞLA SITKI KOÇMAN ÜNİVERSİTESİ EĞİTİM BİLİMLERİ ENSTİTÜSÜ TEZ ÖNERİSİ HAZIRLAMA KILAVUZU MART, 2017 MUĞLA T.C. MUĞLA SITKI KOÇMAN ÜNİVERSİTESİ EĞİTİM BİLİMLERİ ENSTİTÜSÜ.... ANABİLİM DALI.... BİLİM
T.C. MUĞLA SITKI KOÇMAN ÜNİVERSİTESİ EĞİTİM BİLİMLERİ ENSTİTÜSÜ TEZ ÖNERİSİ HAZIRLAMA KILAVUZU MART, 2017 MUĞLA T.C. MUĞLA SITKI KOÇMAN ÜNİVERSİTESİ EĞİTİM BİLİMLERİ ENSTİTÜSÜ.... ANABİLİM DALI.... BİLİM
FREKANS VERİLERİ. Prof.Dr. Levent ŞENYAY III - 1
 3 FREKANS VERİLERİ 3.1. Frekans Tablolarının Düzenlenmesi 3.2. Frekans poligonu 3.3. Frekans tablosu hazırlama 3.4. Frekans Histogramı 3.5. Frekans eğrisi tipleri 3.6. Diğer İstatistiksel Grafik Gösterimler
3 FREKANS VERİLERİ 3.1. Frekans Tablolarının Düzenlenmesi 3.2. Frekans poligonu 3.3. Frekans tablosu hazırlama 3.4. Frekans Histogramı 3.5. Frekans eğrisi tipleri 3.6. Diğer İstatistiksel Grafik Gösterimler
Değer Frekans
 Veri Rasgelelik içeren olgulardan elde edilen ölçüm (gözlem) değerlerine istatistiksel veri veya kısaca veri (data) diyelim. Verilerin deneyler sonucu veya doğal şartlarda olguları gözlemekle elde edildiğini
Veri Rasgelelik içeren olgulardan elde edilen ölçüm (gözlem) değerlerine istatistiksel veri veya kısaca veri (data) diyelim. Verilerin deneyler sonucu veya doğal şartlarda olguları gözlemekle elde edildiğini
BİLİMSEL ARAŞTIRMA YÖNTEMLERİ
 BİLİMSEL ARAŞTIRMA YÖNTEMLERİ Temel Kavramlar Dr. Seher Yalçın 3.2.2017 Dr. Seher Yalçın 1 Araştırmaların Sunumu Bir araştırma raporu, genellikle, üç kümede toplanabilen bölümler halinde düzenlenir. Bunlar:
BİLİMSEL ARAŞTIRMA YÖNTEMLERİ Temel Kavramlar Dr. Seher Yalçın 3.2.2017 Dr. Seher Yalçın 1 Araştırmaların Sunumu Bir araştırma raporu, genellikle, üç kümede toplanabilen bölümler halinde düzenlenir. Bunlar:
Adım Adım SPSS. 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü. Y. Doç. Dr. İbrahim Turan Nisan 2011
 Adım Adım SPSS 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü Y. Doç. Dr. İbrahim Turan Nisan 2011 File (Dosya) Menüsü Excel dosyalarını SPSS e aktarma Variable View (Değişken Görünümü 1- Name (İsim - Kod)
Adım Adım SPSS 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü Y. Doç. Dr. İbrahim Turan Nisan 2011 File (Dosya) Menüsü Excel dosyalarını SPSS e aktarma Variable View (Değişken Görünümü 1- Name (İsim - Kod)
Copyright 2004 Pearson Education, Inc. Slide 1
 Slide 1 Bölüm 2 Verileri Betimleme, Keşfetme, ve Karşılaştırma 2-1 Genel Bakış 2-2 Sıklık Dağılımları 2-3 Verilerin Görselleştirilmesi 2-4 Merkezi Eğilim Ölçüleri 2-5 Değişimin Ölçülmesi 2-6 Nispi Sabitlerin
Slide 1 Bölüm 2 Verileri Betimleme, Keşfetme, ve Karşılaştırma 2-1 Genel Bakış 2-2 Sıklık Dağılımları 2-3 Verilerin Görselleştirilmesi 2-4 Merkezi Eğilim Ölçüleri 2-5 Değişimin Ölçülmesi 2-6 Nispi Sabitlerin
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler
 Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 24 Ekim 2014-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
Tek Değişkenli ve Çok Değişkenli Tablolar ve Grafikler Umut Al umutal@hacettepe.edu.tr BBY 375, 24 Ekim 2014-1 Plan İlgili kavramlar Tablo ne zaman kullanılır? Grafik nasıl üretilir? Örnekler Dikkat edilmesi
Sürekli Rastsal Değişkenler
 Sürekli Rastsal Değişkenler Normal Dağılım: Giriş Normal Dağılım: Tamamen ortalaması ve standart sapması ile tanımlanan bir rastsal değişken, X, için oluşturulan sürekli olasılık dağılımına normal dağılım
Sürekli Rastsal Değişkenler Normal Dağılım: Giriş Normal Dağılım: Tamamen ortalaması ve standart sapması ile tanımlanan bir rastsal değişken, X, için oluşturulan sürekli olasılık dağılımına normal dağılım
GRAFİK YORUMLAMA. 1 ) Sütun Grafiği : Belirli bir zaman aralığında bazı veri grup-
 Sütun Grafiği : Belirli bir zaman aralığında bazı veri grup-") GRAFİK YORUMLAMA Verilerin veya karşılaştırılması yapılacak değişkenlerin çizgi, tablo, nokta veya şekillerle ifade edilmesine grafik adı verilir. Grafik türleri olarak; sütun, çizgi, daire, histogram,
GRAFİK YORUMLAMA Verilerin veya karşılaştırılması yapılacak değişkenlerin çizgi, tablo, nokta veya şekillerle ifade edilmesine grafik adı verilir. Grafik türleri olarak; sütun, çizgi, daire, histogram,
İÇİNDEKİLER ÖN SÖZ...
 İÇİNDEKİLER ÖN SÖZ... v GİRİŞ... 1 1. İSTATİSTİK İN TARİHÇESİ... 1 2. İSTATİSTİK NEDİR?... 3 3. SAYISAL BİLGİDEN ANLAM ÇIKARILMASI... 4 4. BELİRSİZLİĞİN ELE ALINMASI... 4 5. ÖRNEKLEME... 5 6. İLİŞKİLERİN
İÇİNDEKİLER ÖN SÖZ... v GİRİŞ... 1 1. İSTATİSTİK İN TARİHÇESİ... 1 2. İSTATİSTİK NEDİR?... 3 3. SAYISAL BİLGİDEN ANLAM ÇIKARILMASI... 4 4. BELİRSİZLİĞİN ELE ALINMASI... 4 5. ÖRNEKLEME... 5 6. İLİŞKİLERİN
Parametrik İstatistiksel Yöntemler (t testi ve F testi)
") Parametrik İstatistiksel Yöntemler (t testi ve F testi) Dr. Seher Yalçın 27.12.2016 1 İstatistiksel testler parametrik ve parametrik olmayan testler olmak üzere iki gruba ayrılır. Parametrik testler, ilgilenen
Parametrik İstatistiksel Yöntemler (t testi ve F testi) Dr. Seher Yalçın 27.12.2016 1 İstatistiksel testler parametrik ve parametrik olmayan testler olmak üzere iki gruba ayrılır. Parametrik testler, ilgilenen
OLASILIK TEORİSİ VE İSTATİSTİK
 OLASILIK TEORİSİ VE İSTATİSTİK İstatistik: Derslerimiz içinde bu sözcük iki anlamda kullanılacaktır. İlki ve en yaygın kullanılan biçimi rakamla elde edilen bilgilerin belli kuralarla anlaşılır ve yorumlanabilir
OLASILIK TEORİSİ VE İSTATİSTİK İstatistik: Derslerimiz içinde bu sözcük iki anlamda kullanılacaktır. İlki ve en yaygın kullanılan biçimi rakamla elde edilen bilgilerin belli kuralarla anlaşılır ve yorumlanabilir
BİYOİSTATİSTİK. Ödev Çözümleri. Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH
 BİYOİSTATİSTİK Ödev Çözümleri Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr Ödev 1 Çözümleri 2 1. Bir sonucun
BİYOİSTATİSTİK Ödev Çözümleri Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr Ödev 1 Çözümleri 2 1. Bir sonucun
Yazarlar hakkında Editör hakkında Teşekkür
 İÇİNDEKİLER Yazarlar hakkında Editör hakkında Teşekkür XIII XIV XV Giriş 1 Kitabın amaçları 1 Öğretmen katkısı 2 Araştırma katkısı 2 Yansıma için bir ara 3 Sınıf etkinlikleri 3 Terminoloji üzerine bir
İÇİNDEKİLER Yazarlar hakkında Editör hakkında Teşekkür XIII XIV XV Giriş 1 Kitabın amaçları 1 Öğretmen katkısı 2 Araştırma katkısı 2 Yansıma için bir ara 3 Sınıf etkinlikleri 3 Terminoloji üzerine bir
Parametrik Olmayan İstatistiksel Yöntemler
 Parametrik Olmayan İstatistiksel Yöntemler IST-4035 1. Ders DEÜ İstatistik Bölümü 2018 Güz 1 Dersin Amacı Yaygın olarak kullanılan parametrik olmayan istatistiksel yöntemleri tanıtmaktır. Temel kavramların
Parametrik Olmayan İstatistiksel Yöntemler IST-4035 1. Ders DEÜ İstatistik Bölümü 2018 Güz 1 Dersin Amacı Yaygın olarak kullanılan parametrik olmayan istatistiksel yöntemleri tanıtmaktır. Temel kavramların
YANLILIK. Yanlılık örneklem istatistiği değerlerinin evren parametre değerinden herhangi bir sistematik sapması olarak tanımlanır.
 AED 310 İSTATİSTİK YANLILIK Yanlılık örneklem istatistiği değerlerinin evren parametre değerinden herhangi bir sistematik sapması olarak tanımlanır. YANLILIK Yanlı bir araştırma tasarımı uygulandığında,
AED 310 İSTATİSTİK YANLILIK Yanlılık örneklem istatistiği değerlerinin evren parametre değerinden herhangi bir sistematik sapması olarak tanımlanır. YANLILIK Yanlı bir araştırma tasarımı uygulandığında,
IİSTATIİSTIİK. Mustafa Sezer PEHLI VAN
 IİSTATIİSTIİK Mustafa Sezer PEHLI VAN İstatistik nedir? İstatistik, veri anlamına gelir, İstatistik, sayılarla uğraşan bir bilim dalıdır, İstatistik, eksik bilgiler kullanarak doğru sonuçlara ulaştıran
IİSTATIİSTIİK Mustafa Sezer PEHLI VAN İstatistik nedir? İstatistik, veri anlamına gelir, İstatistik, sayılarla uğraşan bir bilim dalıdır, İstatistik, eksik bilgiler kullanarak doğru sonuçlara ulaştıran
Bölüm 2 VERİLERİN DERLENMESİ VE SUNUMU
 Bölüm 2 VERİLERİN DERLENMESİ VE SUNUMU 1 Verilerin Derlenmesi ve Sunulması Anakütleden alınan örnek yardımıyla elde edilen veriler derlendikten sonra çizelgeler ve grafikler halinde bir diğer analize hazır
Bölüm 2 VERİLERİN DERLENMESİ VE SUNUMU 1 Verilerin Derlenmesi ve Sunulması Anakütleden alınan örnek yardımıyla elde edilen veriler derlendikten sonra çizelgeler ve grafikler halinde bir diğer analize hazır
BİYOİSTATİSTİK Olasılıkta Temel Kavramlar Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH
 BİYOİSTTİSTİK Olasılıkta Temel Kavramlar Yrd. Doç. Dr. slı SUNER KRKÜLH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim D. Web: www.biyoistatistik.med.ege.edu.tr 1 OLSILIK Olasılık; Tablo
BİYOİSTTİSTİK Olasılıkta Temel Kavramlar Yrd. Doç. Dr. slı SUNER KRKÜLH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim D. Web: www.biyoistatistik.med.ege.edu.tr 1 OLSILIK Olasılık; Tablo
Oluşturulan evren listesinden örnekleme birimlerinin seçkisiz olarak çekilmesidir
 Bilimsel Araştırma Yöntemleri Prof. Dr. Şener Büyüköztürk Doç. Dr. Ebru Kılıç Çakmak Yrd. Doç. Dr. Özcan Erkan Akgün Doç. Dr. Şirin Karadeniz Dr. Funda Demirel Örnekleme Yöntemleri Evren Evren, araştırma
Bilimsel Araştırma Yöntemleri Prof. Dr. Şener Büyüköztürk Doç. Dr. Ebru Kılıç Çakmak Yrd. Doç. Dr. Özcan Erkan Akgün Doç. Dr. Şirin Karadeniz Dr. Funda Demirel Örnekleme Yöntemleri Evren Evren, araştırma