REGRESYON VE KORELASYON DEĞĠġKENLERARASI BAĞINTI VE ĠLĠġKĠ
|
|
|
- Onur Kashani
- 6 yıl önce
- İzleme sayısı:
Transkript
1 REGRESYON VE KORELASYON DEĞĠġKENLERARASI BAĞINTI VE ĠLĠġKĠ
2 - SĠSTEM, ALT SĠSTEM ve SĠSTEM DĠNAMĠKLERĠ - TERĠM ve TANIMLAR - REGRESYON YÖNTEMLERĠ BASĠT DOĞRUSAL REGRESYON SPSS de REGRESYON ANALĠZĠ - KORELASYON ve ÇEġĠTLERĠ BASĠT KORELASYON ANALĠZĠ (PEARSON KORELASYON ANALĠZĠ) SPSS de KORELASYON ANALĠZĠ - ÇOKLU DOĞRUSAL REGRESYON ANALĠZĠ - ROBUST (SAĞLAM) REGRESYON - LOJĠSTĠK REGRESYON Ġkili Lojistik Regresyon (BLOGREG) Analizi Sıralı Lojistik Regresyon (OLOGREG) Analizi Ġsimsel Lojistik Regresyon (NLOGREG) Analizi
 Sistemler olarak alt sistemlere ayrılır. Sistemler denge içinde çalıģır.")
3 SĠSTEM, ALT SĠSTEM ve SĠSTEM DĠNAMĠKLERĠ Doğa bir ana sistemdir. Bu sistemin altsistemleri vardır. Biyolojik, Sosyo-ekonomik vb. sistemler. ĠNSAN yaģamı da bir sistemdir, Anatomik ve Fizyolojik (Kas-Ġskelet, Sinir, DolaĢım, Solunum, BoĢaltım, Üregenital) Sistemler olarak alt sistemlere ayrılır. Sistemler denge içinde çalıģır. Dinamik sistemde bir takım girdiler (INPUT) ve Çıktılar (OUTPUT) vardır. Girdilerin ve Çıktıların iç ve dıģ dinamikleri sistemin olumlu (sağlıklı) ya da olumsuz (hastalıklı) davranmasını sağlar. Doğada bir çok değiģken birbirlerini etkileyerek değer alırlar. Doğada denge bir etkileģimler zinciri içinde gerçekleģir. Sistemler Dengeli ise Sağlıklı, değilse Hastadır.
4 SĠSTEM MODELLEMESĠ Sistemler matematiksel, istatistiksel ya da benzeģimsel olarak modellenebilir. Bu modelde sonuç/sonuçlar (cevap, response) çıktı, faktörler (faktor, predictor) girdi olarak yer alır. Girdilerin modeldeki etkileri, modelin dinamiğini belirler. Neden-Sonuç (Girdi-Çıktı) iliģkilerini matematiksel olarak tanımlamak sistemin izlenmesi bakımından önemlidir. Doğada her oluģum bir sistem olarak ele alınarak modellenebilir, incelenebilir.
5 Modelleme, Regresyon ve Korelasyon DeğiĢkenler bazı faktör/faktörlerden pozitif ya da negatif yönde etkilenirler. Faktörlerin bazılarının etkisi çok yüksek iken (majör, birincil faktörler), bazılarının etkileri çok düģük düzeydedir (minör, ikincil faktörler). Cevap değiģkenleri etkileyen faktörlerin ortaya konması ve faktörlerin etki düzeylerinin belirlenmesi Regresyon ve Korelasyon yöntemleri aracılığı ile yapılır. Regresyon, iki ve daha fazla değiģken arasındaki matematiksel bağıntıyı denklemlerle ifade etmek ve değiģkenlerin birbirlerinden etkilenme biçimini ve büyüklüğünü ortaya koymak için yararlanılan bir istatistiksel yöntemdir. Korelasyon, değiģkenler arasındaki iliģkinin yönünü, derecesini ve önemini ortaya koyan istatistiksel yöntemdir.
6 TERĠM ve TANIMLAR Faktör: Bir hastalığın ortaya çıkmasında az ya da çok kesin etkisinin (neden, etken, sebep) bilindiği değiģkenlerdir Risk faktörü: Bir hastalığın ortaya çıkmasında katkısının olduğu bilinen, fakat bu faktörün mutlaka hastalığa yol açmasının söz konusu olmadığı faktörlerdir. Sigara, Yaş, Cins, Irk, Kimyasal ajanlar kanser in birer risk faktörleridir. Bağımlı değiģken: Değeri baģka değiģkenlerin etkileri ile oluģan değiģkenlerdir (dependent variable, response variable). Bağımsız değiģken: Değeri rasgele koģullar altında oluģan değiģkenlerdir (Independent variable, Explanatory variable, Factor variable, Predictor variable). Bağımsız değiģken, bağımlı değiģkenin değiģimi üzerinde az ya da çok etkili olan değiģkendir.
7 Model ve DeğiĢkenlerarası Bağıntının Formulasyonu Model : Bir problemin çözümünde ya da bir olayın açıklanmasında yararlanılan matematiksel ya da benzetimsel sembolik yaklaģımlara model adı verilir. Model, genelde bir matematiksel eģitlik ya da eģitsizlik biçiminde belirlenir. Y f(x) Y 0 1 X Y 0 1X 2X2... pxp
8 REGRESYON YÖNTEMLERĠ Regresyon yöntemleri, modeldeki değiģken sayısına, değiģkenin ölçüm tekniğine göre farklı Ģekillerde sınıflandırılmaktadır. 1. Modeldeki değiģkenler sürekli ve değiģken sayısı k=2 ise (bir bağımlı (q=1), bir bağımsız değiģken(p=1)) kurulacak regresyon modelleri Basit Doğrusal Regresyon Polinomiyal regresyon Geometrik Regresyon Üssel Regresyon Basit Eğrisel Regresyon (Nonlinear regresyon)
9 2. Modeldeki değiģkenler sürekli (interval/orantılı) ve sayısı k>2 ise (bir bağımlı(q=1), iki ve daha fazla bağımsız değiģken(p>2)) Çoklu (Multiple) Doğrusal Regresyon Çoklu Doğrusal Olmayan (Multiple Nonlinear) Regresyon 3. Modeldeki bağımlı değiģken nominal/ordinal/ nominalize interval ölçekli, bağımsız değiģkenler orantılı/interval/ordinal/nominal ölçekli ve enaz iki kategorili iseler q=1 p=>1 ise ; Lojistik Regresyon Ordinal Regresyon Robust Regresyon Poisson Regresyon
10 BASĠT DOĞRUSAL REGRESYON Y bağımlı (response, dependent) değiģken ve X bağımsız (belirleyici, predictor) değiģken olmak üzere iki değiģken arasındaki sebepsonuç iliģkisini doğrusal bir model ile ortaya koyan yönteme basit doğrusal regresyon denir. Basit doğrusal regresyon, iki değiģken (Y, X) arasındaki neden-sonuç iliģkisini Y=a+bX biçiminde bir denklem (model) ile ortaya koyar.
11 BASĠT DOĞRUSAL REGRESYON Basit doğrusal regresyon uygulamak için; 1. n birimden Y ve X değiģkenleri için veriler toplanır. (X i,y i ). Verilerin aralıklı ya da orantılı ölçekli olması gerekir. 2. Verilerin XY iliģki grafiği çizilir. Grafikteki xy noktaları bir çember ya da elips içine alınır. 3. Eğer noktaları sınırlayan çerçeve bir elips ve elipsin asal (ana) ekseni ikincil (yan) ekseninden daha büyük ise veriler arasında basit doğrusal bir bağıntı olabileceği varsayılır. 4. Verileri temsil eden Y=a+bX doğrusunun denklemi hesaplanır.
12 BASĠT DOĞRUSAL REGRESYON
13 a ve b Katsayılarının Hesaplanması b X Y X Y n X X n i i i i n i i n i n i i i n i n a X Y X X Y n X X i i i i i i i ( ) bx Y a
14 a ve b Katsayılarının Hesaplanması ÇT Xi Yi X Y ( )( ) n xy i i b ÇTxy / KT x KT x X 2 i ( Xi ) n 2 X X / n KT y Y 2 i ( Yi ) n 2 Y Y / n a Y bx
15 Modelin Önemliliği Y=a+bX modelinin geçerliliğini belirlemek için Regresyon Analizi yönteminden yararlanılır. Modelin önemliliği, belirlenen model ile Y nin değiģiminin X tarafından ne kadar açıklanabildiğinin kontrolu yapılır. Modelin önemliliği aynı zamanda eğimin regresyon katsayısının önemliliğini ve iki değiģken arasındaki korelasyonun da önemliliğini verir.
16 Tahminin Varyansı, b nin Varyansı S Yi a bxi SY X ( ( )). n s 2 n 1 2 KT y (CT KT XY X ) 2 s 2 b n 1 2 KT y ( CTXY ) KT x 2 / KT Y

17 b nin Önemliliği T b S b 2 H 0 : =0 sd=n-2 t<t 0.05,sd P>0.05 n.s. t>t 0.05,sd P<0.05 * t>t 0.01,sd P<0.01 ** t>t 0.001,sd P<0.001*** s 2 b n 1 2 KT y ( CTXY ) KT x 2 / KT Y
 2/ KT XY AKT KTY RKT X rsd=1 asd=n-2 GKT KT")
18 Modelin Önemliliğinin Belirlenmesi Genel KT=Regresyon KT+Artık KT GKT=RKT+AKT RKT ( CT ) 2/ KT XY AKT KTY RKT X rsd=1 asd=n-2 GKT KT Y
19 Regresyon Analizi Tablosu DK sd KT KO F p Regresyon 1 RKT RKO RKO/AKO Artık n-2 AKT AKO - - Genel n-1 GK Y F(rsd, asd)<f(0.05,rsd,asd) P>0.05 ns. Model önemsiz F(rsd, asd)>f(0.05,rsd,asd) P<0.05 * Model önemli. F(rsd, asd)<f(0.01,rsd,asd) P<0.01 ** Model önemli. F(rsd, asd)<f(0.001,rsd,asd) P<0.001 *** Model önemli.
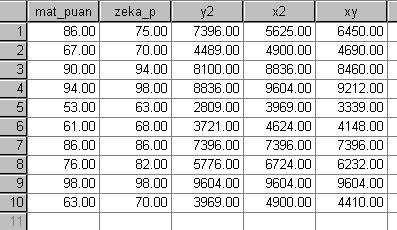
20 10 Lise Öğrencisinin Matematik ve Zeka Puanları Öğr. No Mat_P (Y) Zeka_P (X) T
21 Şekil: 10 Orta Okul Öğrencisinin Matematik ve Zeka Puanları İlişki Grafiği
22 Tablo: 10 Lise Öğrencisinin Matematik, Zeka Puanları ve Gerekli Hesaplamalar Öğr. No Mat_P (Y) Zeka_P (X) Y2 X2 XY T
23 ÇT CT xy KT KT Xi Yi X Y ( )( ) n (804)(774) xy i i x x X b ÇTxy / KT x 2 i ( Xi ) n b / b (804) Y X Y 804/10 774/10 a Y bx a * 80.4 a RegresyonDenklemi 1.111* X
24 SPSS de REGRESYON ANALĠZĠ SPSS veri sayfasında X ve Y verilerini farklı sütunlara giriniz Analyze > Regression >Linear seçeneklerini tıklayınız. ĠĢlem penceresinde X ve Y değiģkenlerini doğru tanımlayarak alanlara taģıyınız. OK tıklayınız.
25

26 SPSS de REGRESYON
27
28 Model 1 Regress ion Res idual Total ANOVA b Sum of Squares df Mean Square F Sig a a. Predic tors: (Constant), ZEKA_P b. Dependent Variable: MAT_PU AN Model 1 (Constant) ZEKA_P Unstandardized Coeff icients a. Dependent Variable: MAT_PUAN Coefficients a Standardized Coeff icients B Std. Error Beta t Sig
29 KORELASYON ve ÇEġĠTLERĠ Korelasyon (Correlation), değiģkenler arasındaki iliģkinin yönünü, derecesini ve önemini ortaya koyan istatistiksel yöntemdir. DeğiĢkenlerin sayısına ve hesaplama biçimine göre; Ġkili (Bivariate) Korelasyon Kısmi (Partial) Korelasyon Çoklu (Multiple) Korelasyon Setlerarası (Canonical) Korelasyon isimleri ile anılır.
30 BASĠT KORELASYON ANALĠZĠ (PEARSON KORELASYON ANALĠZĠ) Ġki değiģken arasındaki iliģkiyi, önemini, yönünü inceleyen korelasyon yöntemidir. Korelasyon, korelasyon katsayısı ile ölçülür. r XY ile gösterilir. Önemlilik t testi ile belirlenir. n 1 i 2 n 1 i i 2 i n 1 i 2 n 1 i i 2 i n 1 i n 1 i i n 1 i i i i XY n Y Y n X X n Y X X Y r 2 n sd r 1 2) (n r t 2
31 Korelasyon Katsayısının Hesaplanması CT xy KT x KT Y (774) 10 2 KT Y r * t * (10 2) 1 (0.932) t 7.27, sd 8, P 0.001***

32 SPSS de KORELASYON ANALĠZĠ
33
34 Correlati ons MAT_PUAN ZEKA_P MAT_PUAN Pears on Correlation ** Sig. (2-t ailed)..000 N ZEKA_P Pears on Correlation.932** Sig. (2-t ailed).000. N **. Correlation is signif icant at the 0.01 lev el (2-tailed). Verilere basit doğrusal regresyon uygulanıyor ise korelasyon analizi sonuçları da regresyon çıktısı içinde yer alır. Mat_P ve Zeka_P verileri Örneğimize regresyon uygulaması tekrarlanırsa sonuçlar aģağıdaki gibi elde edilir.
35 Correlations MAT_PUAN Z EKA_P MAT_PUAN Pears on Correlation ** Sig. (2-t ailed)..000 N ZEKA_P Pears on Correlation.932** Sig. (2-t ailed).000. N **. Correlation is signif icant at the 0.01 lev el (2-tailed). Model 1 Model Summary Adjust ed Std. Error of R R Square R Square the Estim ate.932 a a. Predictors: (Constant), ZEKA_P Model 1 (Constant) ZEKA_P Uns tandardized Coef f icients a. Dependent Variable: MAT_PUAN Coefficients a Standardi zed Coeff icien ts B Std. Error Beta t Sig
36 ÇOKLU DOĞRUSAL REGRESYON ANALĠZĠ Y bağımlı değiģken ve X 1, X 2,..., X p bağımsız değiģkenler olmak üzere değiģkenler arasındaki sebep-sonuç iliģkisini matematiksel bir model olarak ortaya koyan yönteme çoklu regresyon analizi adı verilir. Bir bağımlı değiģken ile bu değiģkenin değiģimi üzerinde etkide bulunan p sayıda bağımsız değiģken arasındaki iliģkinin düzeyini belirleyen yönteme ise çoklu korelasyon analizi denilmektedir. Genellikle çoklu regresyon ve korelasyon analizi birlikte ele alınan ve hesaplamaları birlikte yapılan karma yöntemlerdir.
37 ÇOKLU DOĞRUSAL REGRESYON Çoklu Doğrusal Regresyon Analizi, Y ile iki ve daha fazla açıklayıcı değişken arasındaki ilişkiyi Y=b 0 +b 1 X 1 +b 2 X b p X p biçiminde inceler. Verilere uyan modelin açıklayıcılık yüzdesi belirtme katsayısı R 2 ile belirlenir. Regresyon analizi, modelin tutarlılığını; tahmin gücünü ve her bir değiģkenin Y üzerindeki açıklayıcılığını test eder. Modelin belirleyicilik gücünü ifade eden R 2, aģağıdaki gibi hesaplanır. RKT R 2 gresyon KarelerToplamı Re KT Genel Kareler Toplamı Y
38 ÇOKLU DOĞRUSAL REGRESYON Çoklu belirtme katsayısı (R 2 ) modele yeni bir değiģken eklendiğinde artıģ gösterir. Modele yeni bir değiģken eklenmesine rağmen paydanın değeri değiģmezken payın değeri artar. Bu nedenle R 2 hesaplanırken değiģken sayısına göre düzeltme yapılması gerekir. DüzeltilmiĢ R 2 değeri (R 2 düz ), 2 Rdüz 1 e y 2 2 / ( N k) / ( N 1) ya da 2 Rdüz 1 2 ( 1 R )( N 1) biçiminde hesaplanır N k 1
39 ÇOKLU DOĞRUSAL REGRESYON Örnek: Rasgele seçilen 16 bireyin Günlük Ġçtiği Sigara Sayısı, YAġ, BOY, AĞIRLIK ve SKB değerleri aģağıdaki tabloda verilmiģtir GİSS YAS (yil) BOY (cm) AGIRLIK (Kg) SKB (mm/hg)
40 ÇOKLU DOĞRUSAL REGRESYON SPSS de çoklu regresyon analizi uygulamak için SKB, YAS, BOY, KILO ve GISS değerleri ayrı sütunlara girilir. Çoklu regresyon analizi uygulamak için Statistics>Regression>Linear seçenekleri tıklanır. Açılan ekranda Dependent alanına SKB değiģkeni, Independent(s) alanına ise diğer dört değiģken taģınır. OK tıklanır.

41 ÇOKLU DOĞRUSAL REGRESYON

42 ÇOKLU DOĞRUSAL REGRESYON
43 ÇOKLU DOĞRUSAL REGRESYON Model 1 Variables Entered/Removed b Variables Variables Entered Remov ed Method GISS, YAS, AGIRLIK, BOY a, Enter a. All requested v ariables entered. b. Dependent Variable: SKB Model 1 Model Summary Adjusted Std. Error of R R Square R Square the Estimate,942 a,887,846 4,7942 a. Predictors: (Constant), GISS, YAS, AGI RLIK, BOY
44 ÇOKLU DOĞRUSAL REGRESYON Model 1 Regression Residual Total ANOVA b Sum of Squares df Mean Square F Sig. 1990, ,729 21,655,000 a 252, , , a. Predictors: (Constant), GISS, YAS, AGIRLIK, BOY b. Dependent Variable: SKB
45 ÇOKLU DOĞRUSAL REGRESYON Model 1 (Constant) YAS BOY AGIRLIK GISS a. Dependent Variable: SKB Unstandardized Coeff icients Coefficients a Standardi zed Coeff icien ts B Std. Error Beta t Sig. 53,292 65,883,809,436,161,139,166 1,162,270,170,448,100,379,712,333,260,315 1,281,226,521,182,562 2,872,015
46 ROBUST (SAĞLAM) REGRESYON Sıralama puanları kullanılarak kategorik verilere regresyon modeli uygulamak için ROBUST regresyon yaklaşımı kullanılır. Robust regresyon analizi, SPSS paket programında bulunmadığından dolayı bu analizi diğer bir istatistik paket programı olan MINITAB ile inceleyeceğiz.
47 ROBUST (SAĞLAM) REGRESYON MINITAB de verilere sağlam (robust) regresyon uygulamak için sıralı ya da aralıklı ölçekli veriler sıralama puanlarına dönüģtürülür. MINITAB de Robust regresyon menü seçenekleri ile uygulanamamaktadır. Bunun için MTB> iletisinde iken RREGRES komutundan yararlanılır. Komut yazılımı; >RREGRES dep_var, pred_numb, predictor(s) biçimindedir. REGRESS komutundan sonra bağımlı değiģken, açıklayıcı değiģken sayısı ve açıklayıcı değiģkenlerin sıralama puanlarının yer aldığı sütun numaraları yazılır.
48 ROBUST (SAĞLAM) REGRESYON Örnek: 12 öğrencinin yılsonu baģarı puanları, sosyal etkinlik skorları, sosyo-ekonomik düzey skorları, babanın eğitim düzeyi ve yıl içi devamsızlık gün sayıları verilmiģtir. Veriler aralıklı ölçekli skor değerlerdir. Öğrencilerin yılsonu baģarı puanlarını etkileyen faktörlerin regresyon modelini ROBUST regresyon uygulanması ile bulalım.
49 ROBUST (SAĞLAM) REGRESYON Tablo: 12 bireyin baģarı, sosyal etk., sosyo-eko., babanın eğitim düzeyi ve yıl içi devamsızlık gün sayısı değerleri Birey No Sosyal Etk. Puanı Sosyo- Eko. Düzeyi Babanın Eğ. Düzeyi Başarı Puanı Yıl içi dev. gün sayısı
50 ROBUST (SAĞLAM) REGRESYON MTB > rank c1 c6 MTB > rank c2 c7 MTB > rank c3 c8 MTB > rank c4 c9 MTB > rank c5 c10 MTB > rregres c9 4 c6-c8 c10
51 ROBUST (SAĞLAM) REGRESYON The regression equation is C9 = C C C C10 Coefficient StDev Coef Predictor Rank Least-sq Rank Least-sq Constant C C C C Hodges-Lehmann estimate of tau = Least-squares S = 2.502
52 ROBUST (SAĞLAM) REGRESYON Çıktı incelendiğinde orijinal değerlerin C1-C5, C6-C10 sütunlarına sıralama puanları olarak yazıldığı görülür. Sıralama puanlarına uygulanan regresyon analizinde model; C9 = C C C C1 olarak belirlenir.
53 LOJĠSTĠK REGRESYON Lojistik regresyon; cevap değiģkenin kategorik, ikili (binary, dichotomous), üçlü ve çoklu kategorilerde gözlendiği durumlarda açıklayıcı değiģkenlerle neden sonuç iliģkisini belirlemede yararlanılan bir yöntemdir. Açıklayıcı değiģkenlere göre cevap değiģkenin beklenen değerleri olasılık olarak elde edildiği bir regresyon yöntemidir. Basit ve çoklu regresyon yönteminde bağımlı değiģkenin normal dağılım göstermesi, bağımsız değiģkenlerin normal dağılım göstermesi ve hata varyansının N(0, 2 ) parametreli normal dağılım göstermesi gerekmektedir. Bu koģulları içermeyen veri setlerine basit ya da çoklu regresyon analizleri uygulanamaz.
54 LOJĠSTĠK REGRESYON Lojistik regresyon analizi, sınıflama ve atama iģlemi yapmaya yardımcı olan bir regresyon yöntemidir. Normal dağılım varsayımı, süreklilik varsayımı ön koģulu yoktur. Bağımlı değiģken üzerinde açıklayıcı değiģkenlerin etkileri olasılık olarak elde edilerek risk faktörlerinin olasılık olarak belirlenmesi sağlanır.
55 LOJĠSTĠK REGRESYON Doğada gözlenen fenomenlerin bazıları var-yok, baģarılı-baģarısız gibi ikili biçimde sonuçlanırlar. Bazı sonuçlar ise yok-orta-çok, hiç-az-çok, olumsuz-olumlu-çok olumlu biçiminde üçlü gözlem sonuçları olarak belirlenirler. Bazı sonuçlar ise çok sınıflı kategorik ya da sıralı ölçekli değerler olarak belirlenebilirler. Bu sonuçların ortaya çıkmasında bir çok etken (faktör) rol oynar. Acaba faktörlerin değiģimleri ve farklı kombinasyonları, sonucun görülmesi ya da görülmemesinde, oluģumun derecelendirilmesinde nasıl etkide bulunmaktadır? Normal dağılım varsayımı kurulamayan durumlarda sonucun ortaya çıkmasıçıkmaması, hafif-orta-ağır olarak belirlenmesine açıklayıcı değiģkenlerin etkileri nasıl ortaya konabilir?
56 LOJĠSTĠK REGRESYON Toplumda bazı kiģilerde kalp hastalığı görülürken bazılarında görülmemektedir. Toplumda birçok yönden benzer özellik gösteren bireylerin bazılarında X hastalığı görülürken diğerlerinde görülmemektedir. Niçin? Hangi etken ya da etkenler ne düzeyde bu sonuçların ortaya çıkmasına etki etmektedirler? Bir olayın ortaya çıkmasında bu etkenlerin bir risk faktörü olduğu ve bu etkenlerden hangilerinin önemli risk faktörleri olduğu nasıl belirlenebilir?
57 LOJĠSTĠK REGRESYON Yukarıda sayılan sorulara cevap vermek için verilerin Lojistik Regresyon Analizi ile analiz edilmesi gerekir. Lojistik regresyon, bağımlı değiģkenin tahmini değerlerini olasılık olarak hesaplayarak, olasılık kurallarına uygun sınıflama yapma imkanı veren bir istatistiksel yöntemdir. Lojistik regresyon tablolaģtırılmıģ ya da ham veri setlerini analiz eden bir yöntemdir.
58 LOJĠSTĠK REGRESYON Veri yapılarına göre kurulan lojistik modeller aģağıdaki gibi belirlenir. Ġki değiģkenli lojistik regresyon modeli; P(Y) e 1 0 e 0 1 X 1 X 1 e 1 ( 0 X) 1 ÇokdeğiĢkenli lojistik regresyon modeli; P(Y) 1 e Z e Z Burada Z, bağımsız değiģkenlerin doğrusal kombinasyonudur. Z β β X β X... β X p p
59 LOJĠSTĠK REGRESYON ln Regresyon katsayılarının hesaplanması aģağıdaki gibi yapılır. P(Y) Q(Y) P(Y) Q(Y) e β β 0 β1x1 β2x2... βpxp 0β1X1 β2x2... βpxp β0 β1x1 β2x β 2 pxp e e e...e Burada Q(Y), Q(Y)=1-P(Y) olarak hesaplanır. Odds Ratio nun P(Y)/Q(Y) olarak hesaplandığını hatırlayacak olursak her bir parametrenin Exp() değerleri OR değerleri olarak ele alınırlar. Böylece Exp( p ), Y değiģkeninin X p değiģkeninin etkisi ile kaç kat daha fazla ya da yüzde kaç oranda fazla gözlenme olasılığına sahip olduğunu belirtir. p katsayısının önemliliği aynı zamanda OR p =Exp( p ) nın da önemliliği olarak değerlendirilir.
60 LOJĠSTĠK REGRESYON Lojistik regresyon analizinde üç temel yöntem vardır. Ġkili Lojistik Regresyon (BLOGREG, Binary Logistic Regression) Ordinal Lojistik Regresyon (OLOGREG, Ordinal Logistic Regression) Ġsimsel Lojistik Regresyon (NLOGREG, Nominal Logistic Regression)
61 Ġkili Lojistik Regresyon (BLOGREG) Analizi Ġkili cevap içeren bağımlı değiģkenlerle yapılan lojistik regresyon analizidir. Bir ya da daha fazla açıklayıcı değiģken ile ikili cevap değiģken arasındaki bağıntıyı ortaya koyar. Açıklayıcı değiģkenler ya faktör değiģkenlerdir ya da ortak değiģkendir (covariate). Faktör değiģkenler kategorik isimsel ölçeklidirler, ortak değiģkenler ise sürekli değiģken olmalıdır.
62 Ġkili Lojistik Regresyon (BLOGREG) Analizi Örnek: Yenidoğanın doğum ağırlığının <3.0 kg (doğum ağırlığı=1) ve 3.0+ kg (doğum ağırlığı=2) olmasında annenin yaģı, boyu, kilosu, sigara içip içmemesinin (içiyorsa sigara=1, içmiyorsa sigara=0) rolü araģtırılmaktadır. Bu amaçla rasgele seçilen 30 hamile kadınla ilgili bilgiler tabloda verilmiģtir. Bebeklerin doğum ağırlığının DüĢük (<3.0 kg) ya da Normal ve üstü (3+ kg) olmasında annenin yaģının, boyunun, kilosunun ve sigara alıģkanlığının rolü var mıdır?
63 Ġkili Lojistik Regresyon (BLOGREG) Analizi Birey DOG_AGR YAS SIGARA BOY KILO

64 Ġkili Lojistik Regresyon (BLOGREG) Analizi Örnek verilerine SPSS de BLOGREG analizi uygulamak için Analyze>Regression>Binary-Logistic seçenekleri aģağıdaki ekrandaki gibi seçilir.

65 Ġkili Lojistik Regresyon (BLOGREG) Analizi Seçimler yapıldığında Lojistik regresyon iģlem penceresi görüntülenir. Dependent alanına dog_agr girilir. Diğer açıklayıcı değiģkenler Covariates alanına taģınırlar. Categorical seçeneği tıklanır.

66 Ġkili Lojistik Regresyon (BLOGREG) Analizi SPSS, faktörleri kategorik ortak değiģken olarak modele alır. DeğiĢkenler içinde sadece sigara alıģkanlığı kategorik olduğu için sigara değiģkeni Categorical Variables alanına alınır. DeğiĢkenin Contrast tipi belirlenir. Kurulu seçenek Deviation dur.

67 Ġkili Lojistik Regresyon (BLOGREG) Analizi Çıktıda yer alması istenilen bilgilerin belirlenmesi için Options seçeneği tıklanır ve aģağıdaki ekran görüntülenir. Bu ekranda uygun seçimler yapılır.

68 Ġkili Lojistik Regresyon (BLOGREG) Analizi SPSS lojistik regresyon analizinde hesaplanan ve daha sonraki analizlerde kullanılmak üzere veri sayfasına kaydedilmesi istenilen istatistikleri belirlemek için Save seçeneği tıklanır ve aģağıdaki ekran görüntülenir. Bu ekranda dosyaya kaydedilmesi istenilen değerler belirlenir.
69 Ġkili Lojistik Regresyon (BLOGREG) Analizi Ġlgili tüm tanımlamalar yapıldıktan sonra OK tıklanır. ÖzetlenmiĢ ve düzenlenmiģ sonuçlar aģağıdaki gibi elde edilir. Dependent Vari able Encoding Original Value 1,00 2,00 Internal Value 0 1 Unweighted Cases a Selected Cases Unselected Cases Total a. Case Processing Summary Included in Analysis Missing Cases Total N Percent ,0 0, ,0 0, ,0 If weight is in eff ect, see classification table for the total number of cases.
70 Ġkili Lojistik Regresyon (BLOGREG) Analizi SIGARA a. Categorical Variables Codings a,00 1,00 Paramet e Frequency r coding (1) 16 1, ,000 Categorical v ariable(s) with only 0, and 1 values have been recoded using the above coding scheme. Parameter estimates are not the same as f or indicator (0,1) v ariables. Classification Table a,b Predicted Observ ed Step 0 DOG_AGR 1,00 2,00 Ov erall Percentage a. Constant is included in the model. b. The cut v alue is,500 DOG_AGR Percent age 1,00 2,00 Correct 0 14, ,0 53,3
71 Ġkili Lojistik Regresyon (BLOGREG) Analizi Step 0 Step 1 Constant Variables in the Equation B S.E. Wald df Sig. Exp(B),134,366,133 1,715 1,143 Omnibus Tests of Model Coefficients Step Block Model Chi-square df Sig. 4,315 4,365 4,315 4,365 4,315 4,365 Step 0 Variables Overall Statistics Variables not in the Equation YAS SIGARA(1) BOY KILO Classification Table a Score df Sig.,332 1,565 3,274 1,070,699 1,403,758 1,384 4,126 4,389 Predicted Step 1 Model Summary -2 Log Cox & Snell Nagelkerke likelihood R Square R Square 37,140,134,179 Observed Step 1 DOG_AGR Overall Percentage a. The cut v alue is,500 1,00 2,00 DOG_AGR Percentage 1,00 2,00 Correct , ,5 63,3 Variables in the Equation Step 1 a YAS SI GARA(1) BOY KILO Constant B S. E. Wald df Sig. Exp(B) -,019,071,074 1,786,981,681,398 2,921 1,087 1,975 -,027,084,103 1,748,973 -,042,074,326 1,568,958 7,564 12,479,367 1, ,737 a. Variable(s) entered on step 1: YAS, SIGARA, BOY, KILO.
72 Ġkili Lojistik Regresyon (BLOGREG) Analizi Çıktı incelendiğinde bütün açıklayıcı değiģkenlerin dog_agr üzerindeki etkisinin önemsiz olduğu, düģük doğum ağırlığını belirleyici bir risk faktörü olmadıkları gözlenmektedir. Sigaranın düģük doğum ağırlıklı bebek doğum olasılığını kat artırdığı bulunmuģ fakat bu önemli bir risk faktörü olarak sayılmasına yetmemiģtir. (OR=1.9755, P= ns ). P(dog_agr) nin tahmini için model sabit ve açıklayıcı değiģkenlerin regresyon katsayıları kullanılarak aģağıdaki gibi yazılır. P(Y)=1/(1+e -Z ) z= boy kilo sigara yaş Model önemli olarak Y nin tahminine katkıda bulunmaktadır. Risk faktörlerinin (açıklayıcı değiģkenlerin) tek baģlarına önemli rolleri yok ise de ortak olarak Y nin değiģimini belirleme etkinliğine sahip görülmektedir.
73 Sıralı Lojistik Regresyon (OLOGREG) Analizi Sıralı Lojistik regresyon (OLOGREG) yöntemi, cevap değiģkenin üç ve daha fazla kategori içerdiği ve değerlerin sıralı ölçekle elde edildiği durumlarda; cevap değiģken ile açıklayıcı değiģkenler arasındaki neden sonuç iliģkilerini ortaya koymaya yönelik bir yöntemdir. Cevap değiģkenin sıralı ölçekli olduğu durumlarda uygulanan bir yöntemdir. Sıralı ölçekli cevap değiģken, en az üç kategoride gözlenen değerler içermelidir.
74 Sıralı Lojistik Regresyon (OLOGREG) Analizi Sıralı ölçekli veriler kodlanırken ya da isimsel olarak kategorileri belirlendiğinde cevapların doğal sıralama yapısında olması gerekir. Örneğin, hastalık Ģiddeti söz konusu ise, hafif<orta<ağır olarak kategoriler belirlenmelidir. Hasta bireyin hastalık Ģiddeti bu kategori yapısı içinde doğru olarak değerlendirilmelidir. Bir oluģuma karģı beğeni sıralaması sözkonusu ise; kategoriler, beğenmedim<az beğendim<beğendim<çok beğendim biçiminde sıralanmalıdır. Bu isimsel değerlerin kod değerleri de aynı büyüklük sıralamasını izlemesi gerekir (1<2<3<4 gibi). OLOGREG analizi isimsel kategoriler yerine kod değerleri de iģlemektedir.
75 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi İsimsel Lojistik regresyon (NLOGREG) yöntemi, cevap değişkenin üç ve daha fazla kategori içerdiği ve değerlerin isimsel ölçekle elde edildiği durumlarda; cevap değişken ile açıklayıcı değişkenler arasındaki neden sonuç ilişkilerini ortaya koymaya yönelik bir yöntemdir. Örneğin bir meslek dalları tercihlerinde sınıflar; Mühendislik, Bankacılık, Tıp, Turizm, vb. isimsel olarak belirlenebilirler.
76 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Örnek: ABD de 1992 yılındaki baģkanlık seçimleri için yapılan kamuoyu araģtırmasında 1847 kiģiye; Bush, Perot ve Clinton için oyları, yaģları, eğitim süreleri (yıl olarak) ve cinsiyetleri sorulmuģtur. Elde edilen verilerin bir kısmı aģağıdaki tabloda verilmiģtir. Burada oy sütunundaki verilerde 1 Bush için, 2 Perot ve 3 Clinton için oy verileceğini göstermektedir. Cinsiyet sütununda ise 1 erkek, 2 kadın ı göstermektedir.
77 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Birey Oyu YaĢı Eğitim Süresi Cinsiyeti

78 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Veriler SPSS paket programında ayrı ayrı sütunlara girilir. Analyze > Regression > Multinomial Logistic Regression tıklanır.
 alanına ise kategorik veri olan cinsiyet ve Covariate(s) alanına ise sürekli değiģken olan yaş ve eğitim")
79 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Dependent alanına bağımlı değiģken olan oy taģınır. Factor(s) alanına ise kategorik veri olan cinsiyet ve Covariate(s) alanına ise sürekli değiģken olan yaş ve eğitim süresi taģınır. OK tıklanır.
80 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Parameter Estimates OY Bush Perot Intercept EGT_SUR YAS [CINSIYET=1] [CINSIYET=2] Intercept EGT_SUR YAS [CINSIYET=1] [CINSIYET=2] B St d. Error Wald df Sig. Exp(B) -,536,346 2,398 1,122 1,041E-02,019,311 1,577 1,010-2,19E-03,003,450 1,502,998,429,104 17,013 1,000 1,536 0 a,, 0,,,270,475,322 1,570-1,63E-02,027,377 1,539,984-3,47E-02,005 48,075 1,000,966 a. This parameter is set to zero because it is redundant.,742,141 27,618 1,000 2,100 0 a,, 0,,
81 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Çıktı sonucunda; eğitim süresinin, Clinton yerine Bush ve ya Perot un seçilmesinde önemli bir etkisi yoktur (Bush için p=0,577>0,05, Perot için p=0,539>0,05). YaĢın ise Clinton nın yerine Bush un seçilmesinde önemsiz fakat Clinton nın yerine Perot un seçilmesinde önemli bir etkisinin olduğu ortaya çıkmıģtır (Bush için p=0,502>0,05, Perot için p=0,000<0,001). YaĢ arttıkça Clinto nun yerine Perot un seçilme olasılığı azalmaktadır. Hesaplanan ODDS ratio oranı 0,966 dır. YaĢ bir birim arttıkça Clinton nun yerine Perot un seçilme Ģansı 0,966 kat artmaktadır.
82 Ġsimsel Lojistik Regresyon (NLOGREG) Analizi Cinsiyetin ise Clinton nın yerine Bush un ve ya Perot un seçilmesinde önemli bir etkisinin olduğu ortaya çıkmıģtır (Bush için p=0,000<0,001 ve Perot için p=0,000<0,001). Bush için cinsiyet değiģkeninin ODDS ratio değeri 1,536 dır. Buda erkeklerin Clinton nun yerine Bush u seçme Ģansı kadınlarınkinden 1,536 kat fazladır. Yine aynı Ģekilde Perot için Cinsiyet değiģkeninin ODDS ratio değeri 2,1 dir. Buda erkeklerin Clinton un yerine Perot u seçme Ģansı kadınlara oranla 2,1 kat daha fazladır.
KORELASYON VE REGRESYON UYGULAMASI
 KORELASYON VE REGRESYON UYGULAMASI (BİLGİSAYARDA İSTATİSTİK ÇÖZÜMLEMELER) Yrd.Doç.Dr. İsmail YILDIZ Biyoistatistik AD Öğretim üyesi iyildiz@dicle.edu.tr 1 REGRESYON ve KORELASYON ANALİZİ Bağımlı değişkenin
KORELASYON VE REGRESYON UYGULAMASI (BİLGİSAYARDA İSTATİSTİK ÇÖZÜMLEMELER) Yrd.Doç.Dr. İsmail YILDIZ Biyoistatistik AD Öğretim üyesi iyildiz@dicle.edu.tr 1 REGRESYON ve KORELASYON ANALİZİ Bağımlı değişkenin
Pazarlama Araştırması Grup Projeleri
 Pazarlama Araştırması Grup Projeleri Projeler kapsamında öğrencilerden derlediğiniz 'Teknoloji Kullanım Anketi' verilerini kullanarak aşağıda istenilen testleri SPSS programını kullanarak gerçekleştiriniz.
Pazarlama Araştırması Grup Projeleri Projeler kapsamında öğrencilerden derlediğiniz 'Teknoloji Kullanım Anketi' verilerini kullanarak aşağıda istenilen testleri SPSS programını kullanarak gerçekleştiriniz.
YILLARI ARASINDA GÜNEY CAROLINA DA OKUL İÇİ ŞİDDET İSTATİSKLERİ ANALİZİ (Bir Önceki Projeden Devam Edilecektir)
") 1996-1998 YILLARI ARASINDA GÜNEY CAROLINA DA OKUL İÇİ ŞİDDET İSTATİSKLERİ ANALİZİ (Bir Önceki Projeden Devam Edilecektir) Hazırlayan : Süleyman Öğrekçi 1996 ve 1998 yılları arasında Güney Carolina da resmi
1996-1998 YILLARI ARASINDA GÜNEY CAROLINA DA OKUL İÇİ ŞİDDET İSTATİSKLERİ ANALİZİ (Bir Önceki Projeden Devam Edilecektir) Hazırlayan : Süleyman Öğrekçi 1996 ve 1998 yılları arasında Güney Carolina da resmi
REGRESYON ANALİZİ VE UYGULAMA. Yrd. Doç. Dr. Hidayet Takcı
 REGRESYON ANALİZİ VE UYGULAMA Yrd. Doç. Dr. Hidayet Takcı htakci@cumhuriyet.edu.tr Sunum içeriği Bu sunumda; Lojistik regresyon konu anlatımı Basit doğrusal regresyon problem çözümleme Excel yardımıyla
REGRESYON ANALİZİ VE UYGULAMA Yrd. Doç. Dr. Hidayet Takcı htakci@cumhuriyet.edu.tr Sunum içeriği Bu sunumda; Lojistik regresyon konu anlatımı Basit doğrusal regresyon problem çözümleme Excel yardımıyla
Regresyon. Regresyon korelasyon ile yakından ilişkilidir
 Regresyon Regresyona Giriş Regresyon korelasyon ile yakından ilişkilidir Regresyon bir bağımlı değişken ile (DV) bir veya daha fazla bağımsız değişken arasındaki doğrusal ilişkiyi inceler. DV için başka
Regresyon Regresyona Giriş Regresyon korelasyon ile yakından ilişkilidir Regresyon bir bağımlı değişken ile (DV) bir veya daha fazla bağımsız değişken arasındaki doğrusal ilişkiyi inceler. DV için başka
KORELASYON VE REGRESYON ANALİZİ. Doç. Dr. Bahar TAŞDELEN
 KORELASYON VE REGRESYON ANALİZİ Doç. Dr. Bahar TAŞDELEN Günlük hayattan birkaç örnek Gelişim dönemindeki bir çocuğun boyu ile kilosu arasındaki ilişki Bir ailenin tükettiği günlük ekmek sayısı ile ailenin
KORELASYON VE REGRESYON ANALİZİ Doç. Dr. Bahar TAŞDELEN Günlük hayattan birkaç örnek Gelişim dönemindeki bir çocuğun boyu ile kilosu arasındaki ilişki Bir ailenin tükettiği günlük ekmek sayısı ile ailenin
DÖNEM II ÜROGENİTAL SİSTEM VE HASTALIKLARIN BİYOLOJİK TEMELLERİ DERS KURULU. Yrd.Doç.Dr.İsmail YILDIZ BİYOİSTATİSTİK AD DERS NOTLARI
 DÖNEM II ÜROGENİTAL SİSTEM VE HASTALIKLARIN BİYOLOJİK TEMELLERİ DERS KURULU Yrd.Doç.Dr.İsmail YILDIZ BİYOİSTATİSTİK AD DERS NOTLARI 05.05.2014 Pazartesi, Saat:11.30-12.20;Korelasyon ve Regresyon Uygulaması
DÖNEM II ÜROGENİTAL SİSTEM VE HASTALIKLARIN BİYOLOJİK TEMELLERİ DERS KURULU Yrd.Doç.Dr.İsmail YILDIZ BİYOİSTATİSTİK AD DERS NOTLARI 05.05.2014 Pazartesi, Saat:11.30-12.20;Korelasyon ve Regresyon Uygulaması
Regresyon Analizi. Yaşar Tonta H.Ü. BBY tonta@hacettepe.edu.tr yunus.hacettepe.edu.tr/~tonta/courses/fall2008/sb5002/ SLIDE 1
 Regresyon Analizi Yaşar Tonta H.Ü. BBY tonta@hacettepe.edu.tr yunus.hacettepe.edu.tr/~tonta/courses/fall2008/sb5002/ SLIDE 1 Not: Sunuş slaytları G.A. Morgan, O.V. Griego ve G.W. Gloeckner in SPSS for
Regresyon Analizi Yaşar Tonta H.Ü. BBY tonta@hacettepe.edu.tr yunus.hacettepe.edu.tr/~tonta/courses/fall2008/sb5002/ SLIDE 1 Not: Sunuş slaytları G.A. Morgan, O.V. Griego ve G.W. Gloeckner in SPSS for
Çalıştığı kurumun prestij kaynağı olup olmaması KIZ 2,85 ERKEK 4,18
 1 * BAĞIMSIZ T TESTİ (Independent Samples t test) ÖRNEK: Yapılan bir anket çalışmasında katılımcılardan, çalıştıkları kurumun kendileri için bir prestij kaynağı olup olmadığını belirtmeleri istenmiş. 30
1 * BAĞIMSIZ T TESTİ (Independent Samples t test) ÖRNEK: Yapılan bir anket çalışmasında katılımcılardan, çalıştıkları kurumun kendileri için bir prestij kaynağı olup olmadığını belirtmeleri istenmiş. 30
UYGULAMA 4 TANIMLAYICI İSTATİSTİK DEĞERLERİNİN HESAPLANMASI
 1 UYGULAMA 4 TANIMLAYICI İSTATİSTİK DEĞERLERİNİN HESAPLANMASI Örnek 1: Ders Kitabı 3. konuda verilen 100 tane yaş değeri için; a. Aritmetik ortalama, b. Ortanca değer, c. Tepe değeri, d. En küçük ve en
1 UYGULAMA 4 TANIMLAYICI İSTATİSTİK DEĞERLERİNİN HESAPLANMASI Örnek 1: Ders Kitabı 3. konuda verilen 100 tane yaş değeri için; a. Aritmetik ortalama, b. Ortanca değer, c. Tepe değeri, d. En küçük ve en
SPSS (Statistical Package for Social Sciences)
") SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) Data Editör iki arayüzden oluşur. 1. Data View 2. Variable
SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) Data Editör iki arayüzden oluşur. 1. Data View 2. Variable
Korelasyon ve Regresyon
 Korelasyon ve Regresyon Korelasyon- (lineer korelasyon) Açıklayıcı (Bağımsız) Değişken x çalışma zamanı ayakkabı numarası İki değişken arasındaki ilişkidir. Günlük sigara sayısı SAT puanı boy Yanıt (Bağımlı)
Korelasyon ve Regresyon Korelasyon- (lineer korelasyon) Açıklayıcı (Bağımsız) Değişken x çalışma zamanı ayakkabı numarası İki değişken arasındaki ilişkidir. Günlük sigara sayısı SAT puanı boy Yanıt (Bağımlı)
Bağımsız Örneklemler İçin Tek Faktörlü ANOVA
 Bağımsız Örneklemler İçin Tek Faktörlü ANOVA ANOVA (Varyans Analizi) birden çok t-testinin uygulanması gerektiği durumlarda hata varyansını azaltmak amacıyla öncelikle bir F istatistiği hesaplanır bu F
Bağımsız Örneklemler İçin Tek Faktörlü ANOVA ANOVA (Varyans Analizi) birden çok t-testinin uygulanması gerektiği durumlarda hata varyansını azaltmak amacıyla öncelikle bir F istatistiği hesaplanır bu F
Student t Testi. Doç. Dr. Ertuğrul ÇOLAK. Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı
 Student t Testi Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Tek örnek t testi SPSS de tek örnek t testi uygulaması Bağımsız iki örnek
Student t Testi Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Tek örnek t testi SPSS de tek örnek t testi uygulaması Bağımsız iki örnek
UYGULAMA 2 TABLO YAPIMI
 1 UYGULAMA 2 TABLO YAPIMI Amaç: SPSS 10 istatistiksel paket programında veri girişi ve tablo yapımı. SPSS 10 istatistiksel paket programı ilk açıldığında ekrana gelen görüntü aşağıdaki gibidir. Bu pencere
1 UYGULAMA 2 TABLO YAPIMI Amaç: SPSS 10 istatistiksel paket programında veri girişi ve tablo yapımı. SPSS 10 istatistiksel paket programı ilk açıldığında ekrana gelen görüntü aşağıdaki gibidir. Bu pencere
ALIŞTIRMA 2 GSYİH. Toplamsal Ayrıştırma Yöntemi
 ALIŞTIRMA 2 GSYİH Bu çalışmamızda GSYİH serisinin toplamsal ve çarpımsal ayrıştırma yöntemine göre modellenip modellenemeyeceği incelenecektir. Seri ilk olarak toplamsal ayrıştırma yöntemine göre analiz
ALIŞTIRMA 2 GSYİH Bu çalışmamızda GSYİH serisinin toplamsal ve çarpımsal ayrıştırma yöntemine göre modellenip modellenemeyeceği incelenecektir. Seri ilk olarak toplamsal ayrıştırma yöntemine göre analiz
19. BÖLÜM BİRBİRİYLE İLİŞKİLİ OLAN İKİ DEĞİŞKENDEN BİRİSİNDEKİ DEĞİŞİME GÖRE DİĞERİNİN ALACAĞI DEĞERİ YORDAMA (KESTİRME) UYGULAMA-I
 UYGULAMA-I") 19. BÖLÜM BİRBİRİYLE İLİŞKİLİ OLAN İKİ DEĞİŞKENDEN BİRİSİNDEKİ DEĞİŞİME GÖRE DİĞERİNİN ALACAĞI DEĞERİ YORDAMA (KESTİRME) UYGULAMA-I Bir dil dershanesinde öğrenciler talep ettikleri takdirde, öğretmenleriyle
19. BÖLÜM BİRBİRİYLE İLİŞKİLİ OLAN İKİ DEĞİŞKENDEN BİRİSİNDEKİ DEĞİŞİME GÖRE DİĞERİNİN ALACAĞI DEĞERİ YORDAMA (KESTİRME) UYGULAMA-I Bir dil dershanesinde öğrenciler talep ettikleri takdirde, öğretmenleriyle
Korelasyon, Korelasyon Türleri ve Regresyon
 Korelasyon, Korelasyon Türleri ve Regresyon İçerik Korelasyon Korelasyon Türleri Korelasyon Katsayısı Regresyon KORELASYON Korelasyon iki ya da daha fazla değişken arasındaki doğrusal ilişkiyi gösterir.
Korelasyon, Korelasyon Türleri ve Regresyon İçerik Korelasyon Korelasyon Türleri Korelasyon Katsayısı Regresyon KORELASYON Korelasyon iki ya da daha fazla değişken arasındaki doğrusal ilişkiyi gösterir.
UYGULAMA 1 SPSS E GİRİŞ. SPSS; File, Edit, View, Data, Transform, Analyze, Graphs, Utilities, Window, Help adlı 10 adet program menüsü içermektedir.
 1 UYGULAMA 1 SPSS E GİRİŞ SPSS; File, Edit, View, Data, Transform, Analyze, Graphs, Utilities, Window, Help adlı 10 adet program menüsü içermektedir. Bu menülerin işlevleri ve alt menüleri ile komutları
1 UYGULAMA 1 SPSS E GİRİŞ SPSS; File, Edit, View, Data, Transform, Analyze, Graphs, Utilities, Window, Help adlı 10 adet program menüsü içermektedir. Bu menülerin işlevleri ve alt menüleri ile komutları
01.02.2013. Statistical Package for the Social Sciences
 Hipotezlerin test edilip onaylanması için çeşitli istatistiksel testler kullanılmaktadır. Fakat... Her istatistik teknik her tür analize elverişli değildir. Modele veya hipoteze uygun test istatistiği
Hipotezlerin test edilip onaylanması için çeşitli istatistiksel testler kullanılmaktadır. Fakat... Her istatistik teknik her tür analize elverişli değildir. Modele veya hipoteze uygun test istatistiği
Ki-Kare Bağımsızlık Analizi
 Ki-Kare Bağımsızlık Analizi Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Ki-Kare Bağımsızlık Analizi Kikare bağımsızlık analizi, isimsel ya da sıralı ölçekli
Ki-Kare Bağımsızlık Analizi Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Ki-Kare Bağımsızlık Analizi Kikare bağımsızlık analizi, isimsel ya da sıralı ölçekli
SPPS. Verileri Düzenleme ve Değiştirme 3 - Data Menüsü. Y. Doç. Dr. İbrahim Turan Nisan 2011
 SPPS Verileri Düzenleme ve Değiştirme 3 - Data Menüsü Y. Doç. Dr. İbrahim Turan Nisan 2011 Data Menüsü 1- Define Variable 1- Properties (Değişken Özelliklerini Tanımlama) Değişken özelliklerini tanımlamak
SPPS Verileri Düzenleme ve Değiştirme 3 - Data Menüsü Y. Doç. Dr. İbrahim Turan Nisan 2011 Data Menüsü 1- Define Variable 1- Properties (Değişken Özelliklerini Tanımlama) Değişken özelliklerini tanımlamak
BİYOİSTATİSTİK PARAMETRİK TESTLER
 BİYOİSTATİSTİK PARAMETRİK TESTLER Doç. Dr. Mahmut AKBOLAT *Bir testin kullanılabilmesi için belirli şartların sağlanması gerekir. *Bir testin, uygulanabilmesi için gerekli şartlar; ne kadar çok veya güçlü
BİYOİSTATİSTİK PARAMETRİK TESTLER Doç. Dr. Mahmut AKBOLAT *Bir testin kullanılabilmesi için belirli şartların sağlanması gerekir. *Bir testin, uygulanabilmesi için gerekli şartlar; ne kadar çok veya güçlü
PARAMETRİK TESTLER. Tek Örneklem t-testi. 200 öğrencinin matematik dersinden aldıkları notların ortalamasının 70 e eşit olup olmadığını test ediniz.
 PARAMETRİK TESTLER Tek Örneklem t-testi 200 öğrencinin matematik dersinden aldıkları notların ortalamasının 70 e eşit olup olmadığını test ediniz. H0 (boş hipotez): 200 öğrencinin matematik dersinden aldıkları
PARAMETRİK TESTLER Tek Örneklem t-testi 200 öğrencinin matematik dersinden aldıkları notların ortalamasının 70 e eşit olup olmadığını test ediniz. H0 (boş hipotez): 200 öğrencinin matematik dersinden aldıkları
Örnek. Aşağıdaki veri setlerindeki X ve Y veri çiftlerini kullanarak herbir durumda X=1,5 için Y nin hangi değerleri alacağını hesaplayınız.
 Örnek Aşağıdaki veri setlerindeki X ve Y veri çiftlerini kullanarak herbir durumda X=1,5 için Y nin hangi değerleri alacağını hesaplayınız. i. ii. X 1 2 3 4 1 2 3 4 Y 2 3 4 5 4 3 2 1 Örnek Aşağıdaki veri
Örnek Aşağıdaki veri setlerindeki X ve Y veri çiftlerini kullanarak herbir durumda X=1,5 için Y nin hangi değerleri alacağını hesaplayınız. i. ii. X 1 2 3 4 1 2 3 4 Y 2 3 4 5 4 3 2 1 Örnek Aşağıdaki veri
KORELASYON VE REGRESYON ANALİZİ. Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı
 KORELASYON VE REGRESYON ANALİZİ Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı İki ya da daha çok değişken arasında ilişki olup olmadığını, ilişki varsa yönünü ve gücünü inceleyen korelasyon
KORELASYON VE REGRESYON ANALİZİ Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı İki ya da daha çok değişken arasında ilişki olup olmadığını, ilişki varsa yönünü ve gücünü inceleyen korelasyon
ADMIT: Öğrencinin yüksek lisans programına kabul edilip edilmediğini göstermektedir. Eğer kabul edildi ise 1, edilmedi ise 0 değerini almaktadır.
 Uygulama-2 Bir araştırmacı Amerika da yüksek lisans ve doktora programlarını kabul edinilmeyi etkileyen faktörleri incelemek istemektedir. Bu doğrultuda aşağıdaki değişkenleri ele almaktadır. GRE: Üniversitelerin
Uygulama-2 Bir araştırmacı Amerika da yüksek lisans ve doktora programlarını kabul edinilmeyi etkileyen faktörleri incelemek istemektedir. Bu doğrultuda aşağıdaki değişkenleri ele almaktadır. GRE: Üniversitelerin
Öğr. Elemanı: Dr. Mustafa Cumhur AKBULUT
 Ünite 10: Regresyon Analizi Öğr. Elemanı: Dr. Mustafa Cumhur AKBULUT 10.Ünite Regresyon Analizi 2 Ünitede Ele Alınan Konular 10. Regresyon Analizi 10.1. Basit Doğrusal regresyon 10.2. Regresyon denklemi
Ünite 10: Regresyon Analizi Öğr. Elemanı: Dr. Mustafa Cumhur AKBULUT 10.Ünite Regresyon Analizi 2 Ünitede Ele Alınan Konular 10. Regresyon Analizi 10.1. Basit Doğrusal regresyon 10.2. Regresyon denklemi
SANAYİ İŞÇİLERİNİN DİNİ YÖNELİMLERİ VE ÇALIŞMA TUTUMLARI ARASINDAKİ İLİŞKİ - ÇORUM ÖRNEĞİ
 , ss. 51-75. SANAYİ İŞÇİLERİNİN DİNİ YÖNELİMLERİ VE ÇALIŞMA TUTUMLARI ARASINDAKİ İLİŞKİ - ÇORUM ÖRNEĞİ Sefer YAVUZ * Özet Sanayi İşçilerinin Dini Yönelimleri ve Çalışma Tutumları Arasındaki İlişki - Çorum
, ss. 51-75. SANAYİ İŞÇİLERİNİN DİNİ YÖNELİMLERİ VE ÇALIŞMA TUTUMLARI ARASINDAKİ İLİŞKİ - ÇORUM ÖRNEĞİ Sefer YAVUZ * Özet Sanayi İşçilerinin Dini Yönelimleri ve Çalışma Tutumları Arasındaki İlişki - Çorum
Hipotezlerin test edilip onaylanması için çeşitli istatistiksel testler kullanılmaktadır. Fakat...
 Hipotezlerin test edilip onaylanması için çeşitli istatistiksel testler kullanılmaktadır. Fakat... Her istatistik teknik her tür analize elverişli değildir. Modele veya hipoteze uygun test istatistiği
Hipotezlerin test edilip onaylanması için çeşitli istatistiksel testler kullanılmaktadır. Fakat... Her istatistik teknik her tür analize elverişli değildir. Modele veya hipoteze uygun test istatistiği
K-S Testi hipotezde ileri sürülen dağılımla örnek yığılmalı dağılım fonksiyonunun karşılaştırılması ile yapılır.
 İstatistiksel güven aralıkları uygulamalarında normallik (normal dağılıma uygunluk) oldukça önemlidir. Kullanılan parametrik istatistiksel tekniklerin geçerli olabilmesi için populasyon şans değişkeninin
İstatistiksel güven aralıkları uygulamalarında normallik (normal dağılıma uygunluk) oldukça önemlidir. Kullanılan parametrik istatistiksel tekniklerin geçerli olabilmesi için populasyon şans değişkeninin
TABLO I: Bağımlı değişken; Tüketim,- bağımsız değişkenler; gelir ve fiyat olmak üzere değişkenlere ait veriler verilmiştir.
 EKONOMETRİ II Uygulama - Otokorelasyon TABLO I: Bağımlı değişken; Tüketim,- bağımsız değişkenler; gelir ve fiyat olmak üzere Tuketim 58 Gelir 3959 Fiyat 312 değişkenlere ait veriler verilmiştir. 56 3858
EKONOMETRİ II Uygulama - Otokorelasyon TABLO I: Bağımlı değişken; Tüketim,- bağımsız değişkenler; gelir ve fiyat olmak üzere Tuketim 58 Gelir 3959 Fiyat 312 değişkenlere ait veriler verilmiştir. 56 3858
The International New Issues In SOcial Sciences
 Number: 4 pp: 89-95 Winter 2017 SINIRSIZ İYİLEŞMENİN ÖRGÜT PERFORMANSINA ETKİSİ: BİR UYGULAMA Okan AY 1 Giyesiddin NUROV 2 ÖZET Sınırsız iyileşme örgütsel süreçlerin hiç durmaksızın örgüt içi ve örgüt
Number: 4 pp: 89-95 Winter 2017 SINIRSIZ İYİLEŞMENİN ÖRGÜT PERFORMANSINA ETKİSİ: BİR UYGULAMA Okan AY 1 Giyesiddin NUROV 2 ÖZET Sınırsız iyileşme örgütsel süreçlerin hiç durmaksızın örgüt içi ve örgüt
Korelasyon. Korelasyon. Merkezi eğilim ve değişim ölçüleri bir defada sadece bir değişkenin özelliklerini incelememize imkan tanır.
 Korelasyon Korelasyon Merkezi eğilim ve değişim ölçüleri bir defada sadece bir değişkenin özelliklerini incelememize imkan tanır. Biz şimdi, bir değişkenin özelliklerini diğer değişkenle olan ilişkisine
Korelasyon Korelasyon Merkezi eğilim ve değişim ölçüleri bir defada sadece bir değişkenin özelliklerini incelememize imkan tanır. Biz şimdi, bir değişkenin özelliklerini diğer değişkenle olan ilişkisine
BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2
 1 BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2 Bu bölümde bir veri seti üzerinde betimsel istatistiklerin kestiriminde SPSS paket programının kullanımı açıklanmaktadır. Açıklamalar bir örnek üzerinde hareketle
1 BÖLÜM 8 BİLGİSAYAR UYGULAMALARI - 2 Bu bölümde bir veri seti üzerinde betimsel istatistiklerin kestiriminde SPSS paket programının kullanımı açıklanmaktadır. Açıklamalar bir örnek üzerinde hareketle
Varyans Analizi (ANOVA) Kruskal-Wallis H Testi. Doç. Dr. Ertuğrul ÇOLAK. Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı
 Kruskal-Wallis H Testi. Doç. Dr. Ertuğrul ÇOLAK. Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı") Varyans Analizi (ANOVA) Kruskal-Wallis H Testi Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Tek Yönlü Varyans Analizi SPSS de Tek
Varyans Analizi (ANOVA) Kruskal-Wallis H Testi Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Tek Yönlü Varyans Analizi SPSS de Tek
Data View ve Variable View
 SPSS i çalıştırma 0 SPSS İlk Açılışı 1 Data View ve Variable View 2 Değişken Tanımlama - 1 3 Değişken Tanımlama - 2 4 Boş Veri Sayfası 5 Veri Girişi - 1 6 Veri Girişi - 2 7 Dosya Kaydetme 1 2 3 8 File
SPSS i çalıştırma 0 SPSS İlk Açılışı 1 Data View ve Variable View 2 Değişken Tanımlama - 1 3 Değişken Tanımlama - 2 4 Boş Veri Sayfası 5 Veri Girişi - 1 6 Veri Girişi - 2 7 Dosya Kaydetme 1 2 3 8 File
Korelasyon ve Regresyon
 Korelasyon ve Regresyon Kazanımlar 1 2 3 4 5 6 Değişkenlerin ilişkisini açıklamak ve hesaplamak için Pearson korelasyon katsayısı Örneklem r ile evren korelasyonu hakkında hipotez testi yapmak Spearman
Korelasyon ve Regresyon Kazanımlar 1 2 3 4 5 6 Değişkenlerin ilişkisini açıklamak ve hesaplamak için Pearson korelasyon katsayısı Örneklem r ile evren korelasyonu hakkında hipotez testi yapmak Spearman
Korelasyon ve Regresyon
 Korelasyon ve Regresyon Kazanımlar 1 2 3 4 5 6 Değişkenlerin ilişkisini açıklamak ve hesaplamak için Pearson korelasyon katsayısı Örneklem r ile evren korelasyonu hakkında hipotez testi yapmak Spearman
Korelasyon ve Regresyon Kazanımlar 1 2 3 4 5 6 Değişkenlerin ilişkisini açıklamak ve hesaplamak için Pearson korelasyon katsayısı Örneklem r ile evren korelasyonu hakkında hipotez testi yapmak Spearman
Kullanılacak İstatistikleri Belirleme Ölçütleri. Değişkenin Ölçek Türü ya da Yapısı
 ARAŞTIRMA MODELLİLERİNDE KULLANILACAK İSTATİSTİKLERİ BELİRLEME ÖLÇÜTLERİ Parametrik mi Parametrik Olmayan mı? Kullanılacak İstatistikleri Belirleme Ölçütleri Değişken Sayısı Tek değişkenli (X) İki değişkenli
ARAŞTIRMA MODELLİLERİNDE KULLANILACAK İSTATİSTİKLERİ BELİRLEME ÖLÇÜTLERİ Parametrik mi Parametrik Olmayan mı? Kullanılacak İstatistikleri Belirleme Ölçütleri Değişken Sayısı Tek değişkenli (X) İki değişkenli
İstatistik ve Olasılık
 İstatistik ve Olasılık KORELASYON ve REGRESYON ANALİZİ Doç. Dr. İrfan KAYMAZ Tanım Bir değişkenin değerinin diğer değişkendeki veya değişkenlerdeki değişimlere bağlı olarak nasıl etkilendiğinin istatistiksel
İstatistik ve Olasılık KORELASYON ve REGRESYON ANALİZİ Doç. Dr. İrfan KAYMAZ Tanım Bir değişkenin değerinin diğer değişkendeki veya değişkenlerdeki değişimlere bağlı olarak nasıl etkilendiğinin istatistiksel
Mann-Whitney U ve Wilcoxon T Testleri
 Mann-Whitney U ve Wilcoxon T Testleri Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Parametrik olmayan yöntem Mann-Whitney U testinin
Mann-Whitney U ve Wilcoxon T Testleri Doç. Dr. Ertuğrul ÇOLAK Eskişehir Osmangazi Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı Konu Başlıkları Parametrik olmayan yöntem Mann-Whitney U testinin
8.Sunum. Yrd. Doç. Dr. Sedat ŞEN 1
 8.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Bir önceki sunumda korelasyon kullanarak iki değişken arasındaki ilişkiyi tespit etmeye çalıştık. Bu sunumda iki değişken arasında ilişkiyi göstermenin yanında bir değişkeni
8.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Bir önceki sunumda korelasyon kullanarak iki değişken arasındaki ilişkiyi tespit etmeye çalıştık. Bu sunumda iki değişken arasında ilişkiyi göstermenin yanında bir değişkeni
İÇİNDEKİLER ÖNSÖZ... Örneklem Genişliğinin Elde edilmesi... 1
 İÇİNDEKİLER ÖNSÖZ... v 1. BÖLÜM Örneklem Genişliğinin Elde edilmesi... 1 1.1. Kitle ve Parametre... 1 1.2. Örneklem ve Tahmin Edici... 2 1.3. Basit Rastgele Örnekleme... 3 1.4. Tabakalı Rastgele Örnekleme...
İÇİNDEKİLER ÖNSÖZ... v 1. BÖLÜM Örneklem Genişliğinin Elde edilmesi... 1 1.1. Kitle ve Parametre... 1 1.2. Örneklem ve Tahmin Edici... 2 1.3. Basit Rastgele Örnekleme... 3 1.4. Tabakalı Rastgele Örnekleme...
BEZAYAĞI ÖRGÜDE PAMUKLU KUMAŞLARDA KUMAŞ GRAMAJININ REGRESYON ANALİZİ İLE BELİRLENMESİ *
 BEZAYAĞI ÖRGÜDE PAMUKLU KUMAŞLARDA KUMAŞ GRAMAJININ REGRESYON ANALİZİ İLE BELİRLENMESİ * Determination of the Fabric Weight of Cotton Plain Woven Fabrics Using Regression Analyses Füsun DOBA KADEM Tekstil
BEZAYAĞI ÖRGÜDE PAMUKLU KUMAŞLARDA KUMAŞ GRAMAJININ REGRESYON ANALİZİ İLE BELİRLENMESİ * Determination of the Fabric Weight of Cotton Plain Woven Fabrics Using Regression Analyses Füsun DOBA KADEM Tekstil
7.Sunum. Yrd. Doç. Dr. Sedat ŞEN 1
 7.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Buraya kadar olan konularda (t-testi, ANOVA vb.) bağımlı değişkenin gruplar arasında anlamlı bir fark gösterip göstermediğini test ettik. Bu sunumumuzda farklı bir araştırma
7.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Buraya kadar olan konularda (t-testi, ANOVA vb.) bağımlı değişkenin gruplar arasında anlamlı bir fark gösterip göstermediğini test ettik. Bu sunumumuzda farklı bir araştırma
Eğer Veri Çözümleme paketi Araçlar menüsünde görünmüyor ise yüklenmesi gerekir.
 Bölüm BİLGİSAYAR DESTEKLİ İSTATİSTİK EXCEL DESTEKLİ İSTATİSTİK Excel de istatistik hesaplar; Genel Yöntem ve Excel Ġçerikli Çözümler olmak üzere iki esasa dayanabilir. Genel Yöntem; Excel in matematiksel
Bölüm BİLGİSAYAR DESTEKLİ İSTATİSTİK EXCEL DESTEKLİ İSTATİSTİK Excel de istatistik hesaplar; Genel Yöntem ve Excel Ġçerikli Çözümler olmak üzere iki esasa dayanabilir. Genel Yöntem; Excel in matematiksel
Nicel Veri Analizi ve İstatistik Testler
 Nicel Veri Analizi ve İstatistik Testler Yaşar Tonta H.Ü. BBY tonta@hacettepe.edu.tr yunus.hacettepe.edu.tr/~tonta/courses/spring2009/bby208/ SLIDE 1 Nicel Analiz Olguları tanımlamak ve açıklamak için
Nicel Veri Analizi ve İstatistik Testler Yaşar Tonta H.Ü. BBY tonta@hacettepe.edu.tr yunus.hacettepe.edu.tr/~tonta/courses/spring2009/bby208/ SLIDE 1 Nicel Analiz Olguları tanımlamak ve açıklamak için
Kategorik Veri Analizi
 Kategorik Veri Analizi 6.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli
Kategorik Veri Analizi 6.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli
SA Ğ KALIM ANAL Ġ ZLER Ġ
 SAĞKALIM ANALĠZLERĠ Sağkalım Analizleri Sağkalım verilerini analiz etmek üzere kullanılan istatistiksel yöntemlerdir. Sağkalım verileri, yanıt değişkeni bir olay meydana gelene kadar geçen süre olan verilerdir.
SAĞKALIM ANALĠZLERĠ Sağkalım Analizleri Sağkalım verilerini analiz etmek üzere kullanılan istatistiksel yöntemlerdir. Sağkalım verileri, yanıt değişkeni bir olay meydana gelene kadar geçen süre olan verilerdir.
Tekrarlı Ölçümler ANOVA
 Tekrarlı Ölçümler ANOVA Repeated Measures ANOVA Aynı veya ilişkili örneklemlerin tekrarlı ölçümlerinin ortalamalarının aynı olup olmadığını test eder. Farklı zamanlardaki ölçümlerde aynı (ilişkili) kişiler
Tekrarlı Ölçümler ANOVA Repeated Measures ANOVA Aynı veya ilişkili örneklemlerin tekrarlı ölçümlerinin ortalamalarının aynı olup olmadığını test eder. Farklı zamanlardaki ölçümlerde aynı (ilişkili) kişiler
Çoklu Regresyon Korelasyon Analizinde Varsayımdan Sapmalar ve Çimento Sektörü Üzerine Uygulama *
 Çoklu Regresyon Korelasyon Analizinde Varsayımdan Sapmalar ve Çimento Sektörü Üzerine Uygulama * Erkan SEVİNÇ ** Giriş Bu çalışmada İMKB de taş ve toprağa dayalı sanayi altında işlem gören şirketlerin
Çoklu Regresyon Korelasyon Analizinde Varsayımdan Sapmalar ve Çimento Sektörü Üzerine Uygulama * Erkan SEVİNÇ ** Giriş Bu çalışmada İMKB de taş ve toprağa dayalı sanayi altında işlem gören şirketlerin
H.Ü. Bilgi ve Belge Yönetimi Bölümü BBY 208 Sosyal Bilimlerde Araştırma Yöntemleri II (Bahar 2012) SPSS Ders Notları II (19 Nisan 2012)
 SPSS Ders Notları II (19 Nisan 2012)") H.Ü. Bilgi ve Belge Yönetimi Bölümü BBY 208 Sosyal Bilimlerde Araştırma Yöntemleri II (Bahar 2012) SPSS Ders Notları II (19 Nisan 2012) Aşağıdaki analizlerde lise öğrencileri veri dosyası kullanılmıştır.
H.Ü. Bilgi ve Belge Yönetimi Bölümü BBY 208 Sosyal Bilimlerde Araştırma Yöntemleri II (Bahar 2012) SPSS Ders Notları II (19 Nisan 2012) Aşağıdaki analizlerde lise öğrencileri veri dosyası kullanılmıştır.
2x2 ve rxc Boyutlu Tablolarla Hipotez Testleri
 x ve rxc Boyutlu Tablolarla Hipotez Testleri İki tür spesifik uygulamada kullanılır: 1. Bağımsızlık Testi (Test of Independency): Sayım verilerinden oluşan iki değişken arasında bağımsızlık (veya ilişki)
x ve rxc Boyutlu Tablolarla Hipotez Testleri İki tür spesifik uygulamada kullanılır: 1. Bağımsızlık Testi (Test of Independency): Sayım verilerinden oluşan iki değişken arasında bağımsızlık (veya ilişki)
Proceedings July 25-27, 2017; Paris, France
 Determination of the Relationship between Students' Economic Status and Their Happiness by Ordinal Logistic Regression Method: The Case of Cumhuriyet University. Ziya Gökalp Göktolga 1, Engin Karakış 2
Determination of the Relationship between Students' Economic Status and Their Happiness by Ordinal Logistic Regression Method: The Case of Cumhuriyet University. Ziya Gökalp Göktolga 1, Engin Karakış 2
10.Sunum. Yrd. Doç. Dr. Sedat ŞEN 1
 10.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli Sürekli Korelasyon, doğrusal regresyon
10.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli Sürekli Korelasyon, doğrusal regresyon
BKİ farkı Standart Sapması (kg/m 2 ) A B BKİ farkı Ortalaması (kg/m 2 )
 A B BKİ farkı Ortalaması (kg/m 2 )") 4. SUNUM 1 Gözlem ya da deneme sonucu elde edilmiş sonuçların, rastlantıya bağlı olup olmadığının incelenmesinde kullanılan istatistiksel yöntemlere HİPOTEZ TESTLERİ denir. Sonuçların rastlantıya bağlı
4. SUNUM 1 Gözlem ya da deneme sonucu elde edilmiş sonuçların, rastlantıya bağlı olup olmadığının incelenmesinde kullanılan istatistiksel yöntemlere HİPOTEZ TESTLERİ denir. Sonuçların rastlantıya bağlı
REGRESYON. 9.Sunum. Yrd. Doç. Dr. Sedat ŞEN
 REGRESYON 9.Sunum 1 Önceki Sunumda Basit regresyon analizini SPSSte nasıl yapacağımızı Çoklu regresyon analizini SPSSte nasıl yapacağımızı Regresyon verisini olası problemli değerler için nasıl kontrol
REGRESYON 9.Sunum 1 Önceki Sunumda Basit regresyon analizini SPSSte nasıl yapacağımızı Çoklu regresyon analizini SPSSte nasıl yapacağımızı Regresyon verisini olası problemli değerler için nasıl kontrol
3. BÖLÜM: EN KÜÇÜK KARELER
 3. BÖLÜM: EN KÜÇÜK KARELER Bu bölümde; Kilo/Boy Örneği için Basit bir Regresyon EViews Denklem Penceresinin İçeriği Biftek Talebi Örneği için Çalışma Dosyası Oluşturma Beef 2.xls İsimli Çalışma Sayfasından
3. BÖLÜM: EN KÜÇÜK KARELER Bu bölümde; Kilo/Boy Örneği için Basit bir Regresyon EViews Denklem Penceresinin İçeriği Biftek Talebi Örneği için Çalışma Dosyası Oluşturma Beef 2.xls İsimli Çalışma Sayfasından
BİYOİSTATİSTİK DERSLERİ AMAÇ VE HEDEFLERİ
 BİYOİSTATİSTİK DERSLERİ AMAÇ VE HEDEFLERİ DÖNEM I-I. DERS KURULU Konu: Bilimsel yöntem ve istatistik Amaç: Biyoistatistiğin tıptaki önemini kavrar ve sonraki dersler için gerekli terminolojiye hakim olur.
BİYOİSTATİSTİK DERSLERİ AMAÇ VE HEDEFLERİ DÖNEM I-I. DERS KURULU Konu: Bilimsel yöntem ve istatistik Amaç: Biyoistatistiğin tıptaki önemini kavrar ve sonraki dersler için gerekli terminolojiye hakim olur.
ÖNGÖRÜ TEKNĐKLERĐ ÖDEV 5 (KEY)
") ÖNGÖRÜ TEKNĐKLERĐ ÖDEV (KEY) Aşağıda verilen Y zaman sersisi bir ürünle ilgili satışları,aylar itibariyle, gösteren bir seridir. a) Bu serinin garfiğini çizip serinin taşıdığı desenleri (Trend, mevsimsellik
ÖNGÖRÜ TEKNĐKLERĐ ÖDEV (KEY) Aşağıda verilen Y zaman sersisi bir ürünle ilgili satışları,aylar itibariyle, gösteren bir seridir. a) Bu serinin garfiğini çizip serinin taşıdığı desenleri (Trend, mevsimsellik
PARAMETRİK ve PARAMETRİK OLMAYAN (NON PARAMETRİK) ANALİZ YÖNTEMLERİ.
 ANALİZ YÖNTEMLERİ.") AED 310 İSTATİSTİK PARAMETRİK ve PARAMETRİK OLMAYAN (NON PARAMETRİK) ANALİZ YÖNTEMLERİ. Standart Sapma S = 2 ( X X ) (n -1) =square root =sum (sigma) X=score for each point in data _ X=mean of scores
AED 310 İSTATİSTİK PARAMETRİK ve PARAMETRİK OLMAYAN (NON PARAMETRİK) ANALİZ YÖNTEMLERİ. Standart Sapma S = 2 ( X X ) (n -1) =square root =sum (sigma) X=score for each point in data _ X=mean of scores
KARŞILAŞTIRMA İSTATİSTİĞİ, ANALİTİK YÖNTEMLERİN KARŞILAŞTIRILMASI, BİYOLOJİK DEĞİŞKENLİK. Doç.Dr. Mustafa ALTINIŞIK ADÜTF Biyokimya AD 2005
 KARŞILAŞTIRMA İSTATİSTİĞİ, ANALİTİK YÖNTEMLERİN KARŞILAŞTIRILMASI, BİYOLOJİK DEĞİŞKENLİK Doç.Dr. Mustafa ALTINIŞIK ADÜTF Biyokimya AD 2005 1 Karşılaştırma istatistiği Temel kavramlar: Örneklem ve evren:
KARŞILAŞTIRMA İSTATİSTİĞİ, ANALİTİK YÖNTEMLERİN KARŞILAŞTIRILMASI, BİYOLOJİK DEĞİŞKENLİK Doç.Dr. Mustafa ALTINIŞIK ADÜTF Biyokimya AD 2005 1 Karşılaştırma istatistiği Temel kavramlar: Örneklem ve evren:
Örneklemden elde edilen parametreler üzerinden kitle parametreleri tahmin edilmek istenmektedir.
 ÇIKARSAMALI İSTATİSTİKLER Çıkarsamalı istatistikler, örneklemden elde edilen değerler üzerinde kitleyi tanımlamak için uygulanan istatistiksel yöntemlerdir. Çıkarsamalı istatistikler; Tahmin Hipotez Testleri
ÇIKARSAMALI İSTATİSTİKLER Çıkarsamalı istatistikler, örneklemden elde edilen değerler üzerinde kitleyi tanımlamak için uygulanan istatistiksel yöntemlerdir. Çıkarsamalı istatistikler; Tahmin Hipotez Testleri
KORELASYON. 7.Sunum. Yrd. Doç. Dr. Sedat ŞEN
 KORELASYON 7.Sunum 1 Korelasyon Buraya kadar olan konularda (t-testi, ANOVA vb.) bağımlı değişkenin gruplar arasında anlamlı bir fark gösterip göstermediğini test ettik. Bu sunumumuzda farklı bir araştırma
KORELASYON 7.Sunum 1 Korelasyon Buraya kadar olan konularda (t-testi, ANOVA vb.) bağımlı değişkenin gruplar arasında anlamlı bir fark gösterip göstermediğini test ettik. Bu sunumumuzda farklı bir araştırma
SPSS UYGULAMALARI-II Dr. Seher Yalçın 1
 SPSS UYGULAMALARI-II 27.12.2016 Dr. Seher Yalçın 1 Normal Dağılım Varsayımının İncelenmesi Çarpıklık ve Basıklık Katsayısının İncelenmesi Analyze Descriptive Statistics Descriptives tıklanır. Açılan pencerede,
SPSS UYGULAMALARI-II 27.12.2016 Dr. Seher Yalçın 1 Normal Dağılım Varsayımının İncelenmesi Çarpıklık ve Basıklık Katsayısının İncelenmesi Analyze Descriptive Statistics Descriptives tıklanır. Açılan pencerede,
BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ
 1 BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel
1 BÖLÜM 6 MERKEZDEN DAĞILMA ÖLÇÜLERİ Gözlenen belli bir özelliği, bu özelliğe ilişkin ölçme sonuçlarını yani verileri kullanarak betimleme, istatistiksel işlemlerin bir boyutunu oluşturmaktadır. Temel
Nedensel Modeller Y X X X
 Tahmin Yöntemleri Nedensel Modeller X 1, X 2,...,X n şeklinde tanımlanan n değişkenin Y ile ilgili olmakta; Y=f(X 1, X 2,...,X n ) şeklinde bir Y fonksiyonu tanımlanmaktadır. Fonksiyon genellikle aşağıdaki
Tahmin Yöntemleri Nedensel Modeller X 1, X 2,...,X n şeklinde tanımlanan n değişkenin Y ile ilgili olmakta; Y=f(X 1, X 2,...,X n ) şeklinde bir Y fonksiyonu tanımlanmaktadır. Fonksiyon genellikle aşağıdaki
Kitle: Belirli bir özelliğe sahip bireylerin veya birimlerin tümünün oluşturduğu topluluğa kitle denir.
 BÖLÜM 1: FREKANS DAĞILIMLARI 1.1. Giriş İstatistik, rasgelelik içeren olaylar, süreçler, sistemler hakkında modeller kurmada, gözlemlere dayanarak bu modellerin geçerliliğini sınamada ve bu modellerden
BÖLÜM 1: FREKANS DAĞILIMLARI 1.1. Giriş İstatistik, rasgelelik içeren olaylar, süreçler, sistemler hakkında modeller kurmada, gözlemlere dayanarak bu modellerin geçerliliğini sınamada ve bu modellerden
VERİ MADENCİLİĞİ. Karar Ağacı Algoritmaları: SPRINT algoritması Öğr.Gör.İnan ÜNAL
 VERİ MADENCİLİĞİ Karar Ağacı Algoritmaları: SPRINT algoritması Öğr.Gör.İnan ÜNAL SPRINT Algoritması ID3,CART, ve C4.5 gibi algoritmalar önce derinlik ilkesine göre çalışırlar ve en iyi dallara ayırma kriterine
VERİ MADENCİLİĞİ Karar Ağacı Algoritmaları: SPRINT algoritması Öğr.Gör.İnan ÜNAL SPRINT Algoritması ID3,CART, ve C4.5 gibi algoritmalar önce derinlik ilkesine göre çalışırlar ve en iyi dallara ayırma kriterine
BAĞIMLI KUKLA DEĞİŞKENLİ MODELLER A- KADININ İŞGÜCÜNE KATILIM MODELİ NİN DOM İLE E-VIEWS DA ÇÖZÜMÜ
 BAĞIMLI KUKLA DEĞİŞKENLİ MODELLER A- KADININ İŞGÜCÜNE KATILIM MODELİ NİN DOM İLE E-VIEWS DA ÇÖZÜMÜ Modeldeki değişken tanımları aşağıdaki gibidir: IS= 1 i.kadının bir işi varsa (ya da iş arıyorsa) 0 Diğer
BAĞIMLI KUKLA DEĞİŞKENLİ MODELLER A- KADININ İŞGÜCÜNE KATILIM MODELİ NİN DOM İLE E-VIEWS DA ÇÖZÜMÜ Modeldeki değişken tanımları aşağıdaki gibidir: IS= 1 i.kadının bir işi varsa (ya da iş arıyorsa) 0 Diğer
A. Regresyon Katsayılarında Yapısal Kırılma Testleri
 A. Regresyon Katsayılarında Yapısal Kırılma Testleri Durum I: Kırılma Tarihinin Bilinmesi Durumu Kırılmanın bilinen bir tarihte örneğin tarihinde olduğunu önceden bilinmesi durumunda uygulanır. Örneğin,
A. Regresyon Katsayılarında Yapısal Kırılma Testleri Durum I: Kırılma Tarihinin Bilinmesi Durumu Kırılmanın bilinen bir tarihte örneğin tarihinde olduğunu önceden bilinmesi durumunda uygulanır. Örneğin,
REGRESYON. 10.Sunum. Dr. Sedat ŞEN
 REGRESYON 10.Sunum 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, doğrusal regresyon Sürekli Sürekli Korelasyon, doğrusal regresyon
REGRESYON 10.Sunum 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, doğrusal regresyon Sürekli Sürekli Korelasyon, doğrusal regresyon
İÇİNDEKİLER. BÖLÜM 1 Değişkenler ve Grafikler 1. BÖLÜM 2 Frekans Dağılımları 37
 İÇİNDEKİLER BÖLÜM 1 Değişkenler ve Grafikler 1 İstatistik 1 Yığın ve Örnek; Tümevarımcı ve Betimleyici İstatistik 1 Değişkenler: Kesikli ve Sürekli 1 Verilerin Yuvarlanması Bilimsel Gösterim Anlamlı Rakamlar
İÇİNDEKİLER BÖLÜM 1 Değişkenler ve Grafikler 1 İstatistik 1 Yığın ve Örnek; Tümevarımcı ve Betimleyici İstatistik 1 Değişkenler: Kesikli ve Sürekli 1 Verilerin Yuvarlanması Bilimsel Gösterim Anlamlı Rakamlar
Adım Adım SPSS. 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü. Y. Doç. Dr. İbrahim Turan Nisan 2011
 Adım Adım SPSS 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü Y. Doç. Dr. İbrahim Turan Nisan 2011 File (Dosya) Menüsü Excel dosyalarını SPSS e aktarma Variable View (Değişken Görünümü 1- Name (İsim - Kod)
Adım Adım SPSS 1- Data Girişi ve Düzenlemesi 2- Hızlı Menü Y. Doç. Dr. İbrahim Turan Nisan 2011 File (Dosya) Menüsü Excel dosyalarını SPSS e aktarma Variable View (Değişken Görünümü 1- Name (İsim - Kod)
2. REGRESYON ANALİZİNİN TEMEL KAVRAMLARI Tanım
 2. REGRESYON ANALİZİNİN TEMEL KAVRAMLARI 2.1. Tanım Regresyon analizi, bir değişkenin başka bir veya daha fazla değişkene olan bağımlılığını inceler. Amaç, bağımlı değişkenin kitle ortalamasını, açıklayıcı
2. REGRESYON ANALİZİNİN TEMEL KAVRAMLARI 2.1. Tanım Regresyon analizi, bir değişkenin başka bir veya daha fazla değişkene olan bağımlılığını inceler. Amaç, bağımlı değişkenin kitle ortalamasını, açıklayıcı
İSTATİSTİK SPSS UYGULAMA
 İSTATİSTİK SPSS UYGULAMA Yrd. Doç. Dr. H. İbrahim CEBECİ SPSS UYGULAMA Bu bölümde SPSS veri girişi, Basit grafik hazırlama, örneklem çekimi ve tanımlayıcı istatistiksel analizler hakkında SPSS uygulamaları
İSTATİSTİK SPSS UYGULAMA Yrd. Doç. Dr. H. İbrahim CEBECİ SPSS UYGULAMA Bu bölümde SPSS veri girişi, Basit grafik hazırlama, örneklem çekimi ve tanımlayıcı istatistiksel analizler hakkında SPSS uygulamaları
CHAPTER 6 SIMPLE LINEAR REGRESSION
 CHAPTER 6 SIMPLE LINEAR REGRESSION Bu bölümdeki amacımız değişkenler arasındaki ilişkiyi gösteren en uygun eşitliği kurmaktır. Konuya giriş için şu örnekle başlayalım; Diyelim ki Mr. Bump adındaki birisi
CHAPTER 6 SIMPLE LINEAR REGRESSION Bu bölümdeki amacımız değişkenler arasındaki ilişkiyi gösteren en uygun eşitliği kurmaktır. Konuya giriş için şu örnekle başlayalım; Diyelim ki Mr. Bump adındaki birisi
Dependent Variable: Y Method: Least Squares Date: 03/23/11 Time: 16:51 Sample: Included observations: 20
 ABD nin 1966 ile 1985 yılları arasında Y gayri safi milli hasıla, M Para Arazı (M) ve r faiz oranı verileri aşağıda verilmiştir. a) Y= b 1 +b M fonksiyonun spesifikasyon hatası taşıyıp taşımadığını Ramsey
ABD nin 1966 ile 1985 yılları arasında Y gayri safi milli hasıla, M Para Arazı (M) ve r faiz oranı verileri aşağıda verilmiştir. a) Y= b 1 +b M fonksiyonun spesifikasyon hatası taşıyıp taşımadığını Ramsey
Excel dosyasından verileri aktarmak için Proc/Import/Read Text-Lotus-Excel menüsüne tıklanır.
 ZAMAN SERİSİ MODEL Aşağıdaki anlatım sadece lisans düzeyindeki temel ekonometri bilgisine göre hazırlanmıştır. Bir akademik çalışmanın gerektirdiği birçok ön ve son testi içermemektedir. Bu dosyalar ilk
ZAMAN SERİSİ MODEL Aşağıdaki anlatım sadece lisans düzeyindeki temel ekonometri bilgisine göre hazırlanmıştır. Bir akademik çalışmanın gerektirdiği birçok ön ve son testi içermemektedir. Bu dosyalar ilk
LOJİSTİK REGRESYON ANALİZİ
 LOJİSTİK REGRESYON ANALİZİ Lojistik Regresyon Analizini daha kolay izleyebilmek için bazı terimleri tanımlayalım: 1. Değişken (incelenen özellik): Bireyden bireye farklı değerler alabilen özellik, fenomen
LOJİSTİK REGRESYON ANALİZİ Lojistik Regresyon Analizini daha kolay izleyebilmek için bazı terimleri tanımlayalım: 1. Değişken (incelenen özellik): Bireyden bireye farklı değerler alabilen özellik, fenomen
2. BASİT DOĞRUSAL REGRESYON 12
 1. GİRİŞ 1 1.1 Regresyon ve Model Kurma / 1 1.2 Veri Toplama / 5 1.3 Regresyonun Kullanım Alanları / 9 1.4 Bilgisayarın Rolü / 10 2. BASİT DOĞRUSAL REGRESYON 12 2.1 Basit Doğrusal Regresyon Modeli / 12
1. GİRİŞ 1 1.1 Regresyon ve Model Kurma / 1 1.2 Veri Toplama / 5 1.3 Regresyonun Kullanım Alanları / 9 1.4 Bilgisayarın Rolü / 10 2. BASİT DOĞRUSAL REGRESYON 12 2.1 Basit Doğrusal Regresyon Modeli / 12
Parametrik Olmayan İstatistiksel Yöntemler IST
 Parametrik Olmayan İstatistiksel Yöntemler IST-4035-6- EÜ İstatistik Bölümü 08 Güz Non-Parametric Statistics Nominal Ordinal Interval One Sample Tests Binomial test Run test Kolmogrov-Smirnov test X test
Parametrik Olmayan İstatistiksel Yöntemler IST-4035-6- EÜ İstatistik Bölümü 08 Güz Non-Parametric Statistics Nominal Ordinal Interval One Sample Tests Binomial test Run test Kolmogrov-Smirnov test X test
KUKLA DEĞİŞKENLİ MODELLER
 KUKLA DEĞİŞKENLİ MODELLER Bir kukla değişkenli modeller (Varyans Analiz Modelleri) Kukla değişkenlerin diğer kantitatif değişkenlerle alındığı modeller (Kovaryans Analizi Modeller) Kukla değişkenlerin
KUKLA DEĞİŞKENLİ MODELLER Bir kukla değişkenli modeller (Varyans Analiz Modelleri) Kukla değişkenlerin diğer kantitatif değişkenlerle alındığı modeller (Kovaryans Analizi Modeller) Kukla değişkenlerin
İki Ortalama Arasındaki Farkın Önemlilik Testi (Student s t Test) Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı
 Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı") İki Ortalama Arasındaki Farkın Önemlilik Testi (Student s t Test) Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı İki Ortalama Arasındaki Farkın Önemlilik Testi (Student s t test) Ölçümle
İki Ortalama Arasındaki Farkın Önemlilik Testi (Student s t Test) Ankara Üniversitesi Tıp Fakültesi Biyoistatistik Anabilim Dalı İki Ortalama Arasındaki Farkın Önemlilik Testi (Student s t test) Ölçümle
Korelasyon testleri. Pearson korelasyon testi Spearman korelasyon testi. Regresyon analizi. Basit doğrusal regresyon Çoklu doğrusal regresyon
 Korelasyon testleri Pearson korelasyon testi Spearman korelasyon testi Regresyon analizi Basit doğrusal regresyon Çoklu doğrusal regresyon BBY606 Araştırma Yöntemleri Güleda Doğan Ders içeriği Korelasyon
Korelasyon testleri Pearson korelasyon testi Spearman korelasyon testi Regresyon analizi Basit doğrusal regresyon Çoklu doğrusal regresyon BBY606 Araştırma Yöntemleri Güleda Doğan Ders içeriği Korelasyon
SPSS-Tarihsel Gelişimi
 SPSS -Giriş SPSS-Tarihsel Gelişimi ilk sürümü Norman H. Nie, C. Hadlai Hull ve Dale H. Bent tarafından geliştirilmiş ve 1968 yılında piyasaya çıkmış istatistiksel analize yönelik bir bilgisayar programıdır.
SPSS -Giriş SPSS-Tarihsel Gelişimi ilk sürümü Norman H. Nie, C. Hadlai Hull ve Dale H. Bent tarafından geliştirilmiş ve 1968 yılında piyasaya çıkmış istatistiksel analize yönelik bir bilgisayar programıdır.
rasgele değişkeninin olasılık yoğunluk fonksiyonu,
 3.6. Bazı Sürekli Dağılımlar 3.6.1 Normal Dağılım Normal dağılım hem uygulamalı hem de teorik istatistikte kullanılan oldukça önemli bir dağılımdır. Normal dağılımın istatistikte önemli bir yerinin olmasının
3.6. Bazı Sürekli Dağılımlar 3.6.1 Normal Dağılım Normal dağılım hem uygulamalı hem de teorik istatistikte kullanılan oldukça önemli bir dağılımdır. Normal dağılımın istatistikte önemli bir yerinin olmasının
KUKLA DEĞİŞKENLİ MODELLERDE KANTİTATİF DEĞİŞKEN SAYISININ İKİ SINIF İÇİN FARKLI OLMASI DURUMU
 KUKLA DEĞİŞKENLİ MODELLERDE KANTİTATİF DEĞİŞKEN SAYISININ İKİ SINIF İÇİN FARKLI OLMASI DURUMU.HAL: Sabit Terimlerin Farklı Eğimlerin Eşit olması Yi = b+ b2di + b3xi + ui E(Y Di =,X i) = b + b3xi E(Y Di
KUKLA DEĞİŞKENLİ MODELLERDE KANTİTATİF DEĞİŞKEN SAYISININ İKİ SINIF İÇİN FARKLI OLMASI DURUMU.HAL: Sabit Terimlerin Farklı Eğimlerin Eşit olması Yi = b+ b2di + b3xi + ui E(Y Di =,X i) = b + b3xi E(Y Di
Kukla Değişken Nedir?
 Kukla Değişken Nedir? Cinsiyet, eğitim seviyesi, meslek, din, ırk, bölge, tabiiyet, savaşlar, grevler, siyasi karışıklıklar (=darbeler), iktisat politikasındaki değişiklikler, depremler, yangın ve benzeri
Kukla Değişken Nedir? Cinsiyet, eğitim seviyesi, meslek, din, ırk, bölge, tabiiyet, savaşlar, grevler, siyasi karışıklıklar (=darbeler), iktisat politikasındaki değişiklikler, depremler, yangın ve benzeri
6. Ders. Genelleştirilmiş Lineer Modeller (Generalized Linear Models, GLM)
") 6. Ders Genelleştirilmiş Lineer Modeller (Generalized Linear Models, GLM) Y = X β + ε Lineer Modeli pek çok özel hallere sahiptir. Bunlar, ε nun dağılımına (bağımlı değişkenin dağılımına), Cov( ε ) kovaryans
6. Ders Genelleştirilmiş Lineer Modeller (Generalized Linear Models, GLM) Y = X β + ε Lineer Modeli pek çok özel hallere sahiptir. Bunlar, ε nun dağılımına (bağımlı değişkenin dağılımına), Cov( ε ) kovaryans
SPSS (Statistical Package for Social Sciences)
") SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) SPSS Data Editör iki arayüzden oluşur. 1. Data View
SPSS (Statistical Package for Social Sciences) SPSS Data Editor: Microsoft Excel formatına benzer satır ve sütunlardan oluşan çalışma sayfası (*sav) SPSS Data Editör iki arayüzden oluşur. 1. Data View
13. Olasılık Dağılımlar
 13. Olasılık Dağılımlar Mühendislik alanında karşılaşılan fiziksel yada fiziksel olmayan rasgele değişken büyüklüklerin olasılık dağılımları için model alınabilecek çok sayıda sürekli ve kesikli fonksiyon
13. Olasılık Dağılımlar Mühendislik alanında karşılaşılan fiziksel yada fiziksel olmayan rasgele değişken büyüklüklerin olasılık dağılımları için model alınabilecek çok sayıda sürekli ve kesikli fonksiyon
ÖRNEK BULGULAR. Tablo 1: Tanımlayıcı özelliklerin dağılımı
 BULGULAR Çalışma tarihleri arasında Hastanesi Kliniği nde toplam 512 olgu ile gerçekleştirilmiştir. Olguların yaşları 18 ile 28 arasında değişmekte olup ortalama 21,10±1,61 yıldır. Olguların %66,4 ü (n=340)
BULGULAR Çalışma tarihleri arasında Hastanesi Kliniği nde toplam 512 olgu ile gerçekleştirilmiştir. Olguların yaşları 18 ile 28 arasında değişmekte olup ortalama 21,10±1,61 yıldır. Olguların %66,4 ü (n=340)
BİYOİSTATİSTİK Korelasyon Analizi Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH
 BİYOİSTATİSTİK Korelasyon Analizi Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr 1 Bir değişkenin değerinin,
BİYOİSTATİSTİK Korelasyon Analizi Yrd. Doç. Dr. Aslı SUNER KARAKÜLAH Ege Üniversitesi, Tıp Fakültesi, Biyoistatistik ve Tıbbi Bilişim AD. Web: www.biyoistatistik.med.ege.edu.tr 1 Bir değişkenin değerinin,
Ch. 12: Zaman Serisi Regresyonlarında Ardışık Bağıntı (Serial Correlation) ve Değişen Varyans
 ve Değişen Varyans") Yıldız Teknik Üniversitesi İktisat Bölümü Ekonometri II Ders Notları Ders Kitabı: J.M. Wooldridge, Introductory Econometrics A Modern Approach, 2nd. ed., 2002, Thomson Learning. Ch. 12: Zaman Serisi Regresyonlarında
Yıldız Teknik Üniversitesi İktisat Bölümü Ekonometri II Ders Notları Ders Kitabı: J.M. Wooldridge, Introductory Econometrics A Modern Approach, 2nd. ed., 2002, Thomson Learning. Ch. 12: Zaman Serisi Regresyonlarında
Değişken Türleri, Tanımlayıcı İstatistikler ve Normal Dağılım. Dr. Deniz Özel Erkan
 Değişken Türleri, Tanımlayıcı İstatistikler ve Normal Dağılım Dr. Deniz Özel Erkan Evren Parametre Örneklem Çıkarım Veri İstatistik İstatistik Tanımlayıcı (Descriptive) Çıkarımsal (Inferential) Özetleme
Değişken Türleri, Tanımlayıcı İstatistikler ve Normal Dağılım Dr. Deniz Özel Erkan Evren Parametre Örneklem Çıkarım Veri İstatistik İstatistik Tanımlayıcı (Descriptive) Çıkarımsal (Inferential) Özetleme
BİRDEN ÇOK BAĞIMLI DEĞİŞKENİ OLAN MODELLER
 BİRDEN ÇOK BAĞIMLI DEĞİŞKENİ OLAN MODELLER Birden çok bağımlı değişkenin yer aldığı modelleri incelemek amacıyla kullanılan modeller Birden Çok Bağımlı Değişkenli Regresyon Modelleri ya da kısaca MRM ler
BİRDEN ÇOK BAĞIMLI DEĞİŞKENİ OLAN MODELLER Birden çok bağımlı değişkenin yer aldığı modelleri incelemek amacıyla kullanılan modeller Birden Çok Bağımlı Değişkenli Regresyon Modelleri ya da kısaca MRM ler
Kategorik Veri Analizi
 Kategorik Veri Analizi 10.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli
Kategorik Veri Analizi 10.Sunum Yrd. Doç. Dr. Sedat ŞEN 1 ANALİZ TÜRLERİ Bağımlı Değ. Bağımsız Değ. Analiz Sürekli İki kategorili t-testi, Wilcoxon testi Sürekli Kategorik ANOVA, linear regresyon Sürekli
1. YAPISAL KIRILMA TESTLERİ
 1. YAPISAL KIRILMA TESTLERİ Yapısal kırılmanın araştırılması için CUSUM, CUSUMSquare ve CHOW testleri bize gerekli bilgileri sağlayabilmektedir. 1.1. CUSUM Testi (Cumulative Sum of the recursive residuals
1. YAPISAL KIRILMA TESTLERİ Yapısal kırılmanın araştırılması için CUSUM, CUSUMSquare ve CHOW testleri bize gerekli bilgileri sağlayabilmektedir. 1.1. CUSUM Testi (Cumulative Sum of the recursive residuals